새소식
반응형
이번 시간에는 그래프 탐색 방법 중 깊이 우선 탐색(DFS)에 대해서 배워볼 것입니다.
그래프는 탐색하는 동안 동일한 정점으로 다시 이동할 수 있는 싸이클이 있을 수 있습니다. 그래서 동일한 정점이 다시 처리되지 않도록 하려면 처리 후 정점을 방문(visited)했다는 표시를 함으로써 중복 방문을 피하도록 하는 것이 그래프 탐색의 핵심입니다.
DFS는 그래프의 개념이 반드시 선행되어야 하기 때문에 다음 포스트를 먼저 확인하길 바랍니다.
Tree(트리) 자료구조의 설명은 이곳을 참조
Graph(그래프) 자료구조의 설명은 이곳을 참조
전에 배웠던 트리 탐색 중 Preorder, Inorder, Postorder가 바로 DFS의 예입니다.
"Stack을 이용하여 구현"
재귀 호출로 구현하는 방법도 있으나 재귀 호출 자체가 call stack이 계속 쌓이는 형태이기 때문에 스택을 이용해서 구현 할 것입니다.
물론 재귀 호출을 이용한 DFS도 이후 내용에 있습니다.
BFS와의 가장 큰 차이점이라 하면, DFS는 탐색을 한 뒤 이전의 정점으로 돌아오는데 이것을 백트래킹(Backtracking)이라고 합니다.
갈 수 있는 최대한 멀리까지 탐색해 보는 방법
루트 노드(혹은 임의의 다른 노드)에서부터 시작하여 다음 branch로 넘어가기 전에 해당 branch를 먼저 완전히 탐색해 나가는 방법입니다.
미로와 같은 것을 탐색한다고 할 때 한 방향으로만 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 뒤로 돌아 가장 가꾸운 갈림길로 가서 그곳에서부터 다른 방향으로 다시 탐색을 하는 방법이라고 생각하면 편하다.
즉, 넓게(wide) 탐색하기 전에 깊이(deep) 탐색하는 것이다.
사용하는 경우: 모든 노드를 방문 하고 싶을 때 사용합니다.
예를 들어, 지구상의 존재하는 모든 인관관계를 표현한 후 철수와 영희 사이에 존재하는 경로를 찾는 경우가 있다.
DFS가 BFS에 비해서 간단한 편입니다. 단순히 탐색 속도 자체만 봤을 때는 DFS가 BFS에 비해서 느린데, 그 이유가 모든 노드를 방문해야 하기 때문입니다.
DFS의 특징 몇 가지를 살펴 보도록 하겠습니다.
나중에 들어오는 데이터를 먼저 탐색해 나가는 방식을 따르면 인접한 데이터를 먼저 순회하는 것이 아닌 더 깊이 들어가는 방향으로 순회를 하는 것이기 때문에 스택 구조를 사용하는 것입니다.
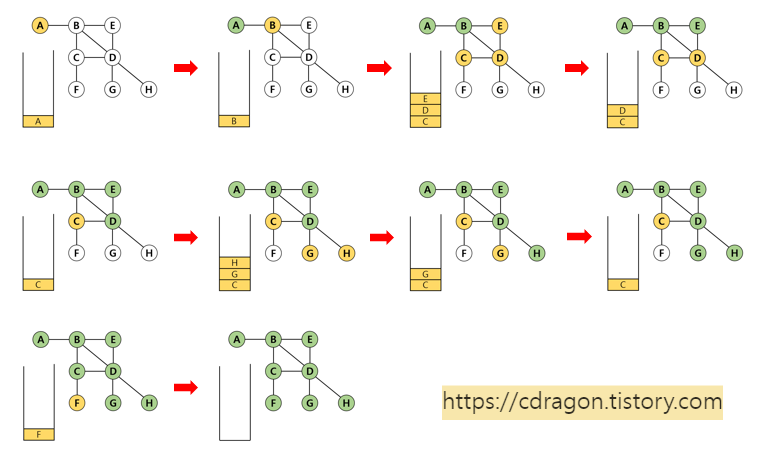
DFS는 인접한 노드들을 바로 다 탐색하는 것이 아니라 인접한 노드 중에서 더 깊이 들어갈 수 있는 노드가 있으면 그 분기(branch)를 먼저 다 탐색해야 그 전의 노드들을 탐색할 수 있습니다.
그렇기 때문에 스택의 특성과 매우 잘 맞는 것입니다.
스택에서 데이터가 빠짐(pop)과 동시에 해당 데이터는 초록색이 되고 이와 인접한 노드는 노란색이 되면서 방문(push)을 한 상태(스택에 진입한 상태)가 되고 큐에서 순서대로 데이터를 빼면서(초록색으로 만들면서,or visited에 들어가면서) 인접 노드들이 큐에 삽입되는(노란색이 되는, 스택에 진입) 과정을 반복하는 것입니다. (모든 노드가 초록색이 될 때까지, 스택이 빌 때까지 반복한다.)
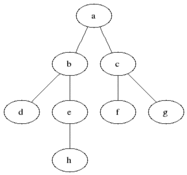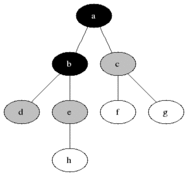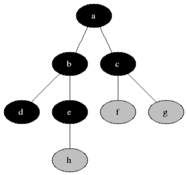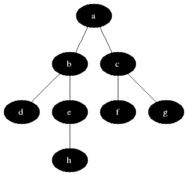
방문순서 : A-B-E-D-H-G-C-F
이전에 시간 구현을 했던 스택 구조를 가져와서 DFS를 구현해 보도록 하겠습니다.
public static List<Integer> dfs(IGraph graph, int from) {
List<Integer> result = new ArrayList<>();
Set<Integer> visited = new HashSet<>();
//dfs를 위한 Mystack
IStack<Integer> stack = new MyStack<>();
//자바의 스택 사용을 원하면
//Stack<Integer> stack = new Stack<>();
//1.
stack.push(from);
visited.add(from);
//2.
while (stack.size > 0) {
Integer next = stack.pop();
result.add(next);
for (Integer n : graph.getNodes(next)) {
if (!visited.contains(n)) {
stack.push(n);
visited.add(n);
}
}
}
return result;
}Input parameter: 지난 시간 구현한 그래프(iGraph), 시작 노드(from)
Return: 방문한 노드를 순서대로 저장한 리스트
DFS에서 cycle의 존재 여부를 확인하는 방법은 Back Edge가 있는지를 확인하면 됩니다.
Back Edge는 자기 자신을 가리키거나(Loop) 자신의 이전 정점을 가리키는 경우의 Edge(간선)을 의미하며 이 Back Edge가 있으면 순환이 있다고 봅니다.
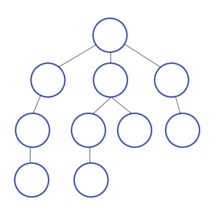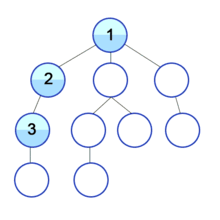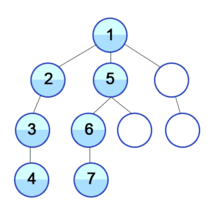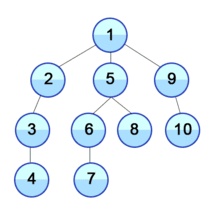
아래 그림을 통해 예시를 살펴보겠습니다.
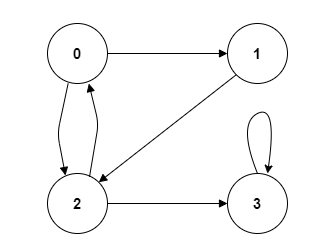
위 그림의 2번 노드에서 시작한다고 하면 여기서 Back Edge는 1 → 2를 가리키는 것, 3이 자기 자신을 가리키는 것, 그리고 0이 2를 가리키는 것 이렇게 세 가지가 Back Edge가 됩니다.
과정은 다음과 같습니다.
무방향 그래프는 상호 연결되어 있기 때문에 방향 그래프에서 순환 탐지 하듯이 탐지를 시도하면 무조건 순환이 있는 것으로 탐지됩니다.
그래서 이를 보완한 방법은 다음과 같습니다.
이해를 위해 다음과 같은 예시를 들어보겠습니다.
인접 정점의 parent가 현재 정점인 경우를 생각해 봅시다.
현재를 A, 인접 정점을 B라고 할 때, A를 방문하고 B에서 다시 A를 방문했다면 무방향 그래프에서 상호 인접 정점끼리는 무조건 재탐색 수행을 하고자 하기 때문에 이것을 제외 시켜야 합니다.
하지만 만약, 현재 정점이 parent가 아니라면 A → B → A 의 순이 아니라 A → B → ? → ? → A처럼 중간에 다른 정점들을 추가로 탐색 했다는 의미이며, 이는 당연히 cycle이 있는 것입니다.
DFS는 그래프 탐색 방법 중 하나로 그래프 구조에서 모든 정점을 탐색할 수 있는 알고리즘 중에 하나입니다. 깊이를 우선순위로 하여 탐색을 진행하기 때문에 재귀 혹은 스택 구조를 활용합니다.
재귀를 이용하여 탐색을 진행한다는 점에서 완전탐색 알고리즘의 재귀 / 백트래킹과 유사하다고 느낄 수 있습니다.
하지만, 재귀라는 것은 자기 자신의 함수(메소드)를 호출하는 방식이기 때문에 DFS는 재귀 방식을 이용해 수행하는 많은 알고리즘 중에 하나인 것입니다.
또한 백트래킹은 재귀를 통해 알고리즘을 풀어 가는 기법으로 가지지기를 통해서 탐색을 하다가 유망하지 않다고 생각이 들면 추가 탐색을 진행하지 않고 뒤로 돌아(Back) 다시 탐색(Tracking)을 진행하는 방식입니다.
그래서 DFS와 백트래킹 간에는 이러한 차이점이 있는 것입니다.
| [Algorithm | Java] Dijkstra Algorithm(다익스트라 알고리즘) (0) | 2022.12.28 |
|---|---|
| [Algorithm | Java] Dynamic Programming(다이나믹 프로그래밍) 알고리즘 (4) | 2022.12.28 |
| [자료구조 | Java] Graph(그래프) (0) | 2022.12.28 |
| [자료구조 | Java] Heap & Priority Queue(힙과 우선순위 큐) (2) | 2022.12.28 |
| [자료구조 | Java] Tree, Binary Tree(트리, 이진 트리) (0) | 2022.12.28 |
소중한 공감 감사합니다