새소식
반응형
이번 시간에는 Heap 자료구조와 우선순위 큐 (Priority Queue)에 대해서 알아봅시다.
Heap 자료구조에 대해서 배워 보도록 합시다.
시작하기 앞서
Computer Science(CS) 분야에서 힙이라는 것은 두 가지의 의미를 가지고 있습니다.
이 두 가지는 같은 용어를 사용하지만 엄연히 다른 의미를 갖고 있기 때문에 구분하여 알아두어야 합니다.
그렇지만 자료구조 및 알고리즘 수업이기 때문에 여기서는 자료구조 힙에 대해 먼저 보도록 하겠습니다.
(CS 카테고리 중 운영체제 수업에서 Java의 메모리 영역으로써의 힙 내용이 다뤄집니다.)
힙(heap)은 이진 힙(binary heap)이라고도 하고, 최댓값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전 이진 트리를 기본으로 한 자료구조입니다.
자료구조 힙은 다음과 같은 속성을 가지고 있습니다.
자료구조 힙에 대해 한 문장을 요약하자면 다음과 같습니다.
최솟값 또는 최댓값을 빠르게 찾아내기 위한 완전 이진 트리 형태로 만들어진 자료구조
완전 이진 트리의 설명은 이곳을 참조
먼저 힙에는 두 가지 종류가 있는 지 보겠습니다.
최대 힙이란 부모 노드의 값은 항상 자식 노드보다 크거나 같을 때를 의미한다.루트 노드 = 트리의 최댓값 일때를 말한다.최소 힙이란 부모 노드의 값은 항상 자식 노드보다 작거나 같을 때를 의미합니다.루트 노드 = 트리의 최솟값입니다.따라서, 새로운 노드가 추가되더라도 힙에서는 이러한 구조가 항상 유지 되어야 하고 좌우 노드에 대한 크기는 신경 쓰지 않고 상하 관계의 크기만을 신경 쓴 구조라고 볼 수 있습니다.
아래 그림을 살펴 보면서 최대 힙과 최소 힙을 이해해 보겠습니다.
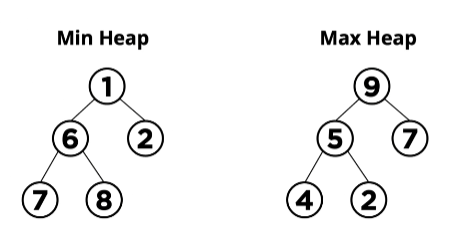
왼쪽 그림은 최소 힙(min heap)으로 트리의 어떤 부모 노드도 자식 노드보다 큰 노드는 존재하지 않습니다. 따라서
루트 노드가 트리의 데이터 중에 최솟값을 갖게 됩니다.
오른쪽 그림은 최대 힙(max heap)으로 트리의 어떤 부모 노드도 자식 노드보다 작은 노드가 존재하지 않습니다. 따라서
루트 노드가 트리의 데이터 중에 최댓값을 갖게 됩니다.
따라서 힙은 '부모 노드는 항상 자식 노드보다 우선순위가 높다' 는 것을 의미하는 구조이며 이를 조금만 돌려서 생각해 보면 루트 노드는 항상 우선순위가 더 높은 노드라는 것을 의미합니다.
이를 통해, 최댓값과 최솟값을 빠르게 찾아낼 수 있다는 장점(시간 복잡도 : O(1))과 함께 삽입, 삭제 연산시에도 부모노드가 자식노드보다 우선순위만 높으면 되므로 결국 트리의 깊이만큼만 비교를 하면 되기 때문에 O(log2n)의 시간 복잡도를 가져 매우 빠르게 수행이 가능합니다.
힙 구조는 최대/ 최소를 기준으로 데이터를 빠르게 찾는 연산입니다.
또한 삽입에 있어서는 O(log2n) 의 시간 복잡도를 갖고, 삭제 역시 O(log2n)의 시간 복잡도를 갖습니다.
힙은 중간에 빈 값이 존재하지 않는 완전 이진 트리이기 때문에 일차원 배열로 표현해도 문제 없습니다.
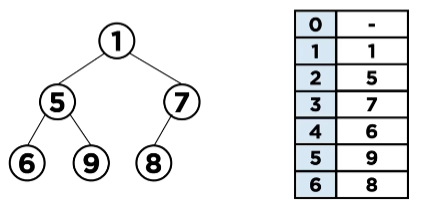
위 그림처럼 배열에 값을 채울 수 있고 0번 index부터 채울 수도 있지만 앞 Tree구조에서 설명 드린 노드 탐색의 용이성 때문에 1번 index부터 루트 노드의 데이터를 채운 모습입니다.
Tree(트리) 자료구조의 설명은 이곳을 참조하세요.
지난 시간 배웠던 성질을 복습해 보도록 하겠습니다.
[성질]
| 루트 노드 | 1 |
| 노드 i의 부모 | i/2 |
| 노드 i의 왼쪽 자식 | i*2 |
| 노드 i의 오른쪽 자식 | i*2 + 1 |

최대 힙을 예로 설명하겠습니다.
예를 들어,

위와 같은 힙 구조가 있다고 가정해 봅시다.
max heap에서 heapify 작업 과정은 다음과 같습니다.
완전 이진 트리에서 heap 구조를 만드는 작업을 합니다.

배열에 표현된 힙은 루트 노드의 index가 1이라고 할 때, n/2 + 1(중간에서 다음 칸) 부터 n(마지막 노드) 까지는 모두 leaf 노드라는 속성을 갖고 있습니다.
leaf 노드를 제외한 나머지 노드(1 ~ n/2)에 heapify를 수행하면 heap 구조화를 진행할 수 있습니다.
시간 복잡도 O(n)
그렇다면 heapify는 어떤 식으로 진행되는지 설명드리도록 하겠습니다.
Min heap에 데이터 '1' 삽입하기
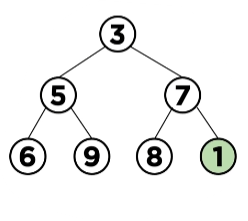
위와 같이 1을 삽입하기 위해서는 다음과 같은 과정이 진행됩니다.

여기서는 1과 7의 위치가 바뀐 것을 볼 수 있습니다. 바꾸기를 진행했다면 다시 2번으로 돌아가 조건을 만족하는 지를 확인하고 만족하지 않는다면 다시 3번 과정으로 가 바꾸기 과정을 진행하고 이 과정을 삽입이 종료(조건 만족)되기 전까지 계속해서 반복합니다.

이번에는 힙의 조건을 만족하므로 삽입 연산이 종료됩니다.
다음은 삭제 연산에 대해서 보도록 하겠습니다.
힙은 최솟값이나 최댓값을 알아내기 편한 구조이기 때문에 루트 노드에서만 삭제 연산이 이루어 지는 경우만 다뤄보도록 하겠습니다.
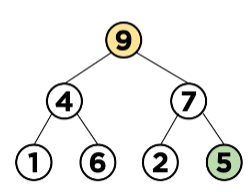
Max Heap에서 최댓값 삭제하기
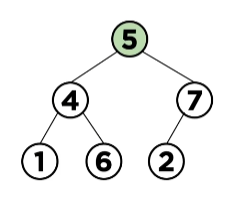
위 그림에서는 루트 노드 5가 조건(Max Heap)을 만족하지 않기 때문에 자식 노드와 위치를 바꾸어 줍니다.
이 과정으로 다음그림과 같이 됩니다.
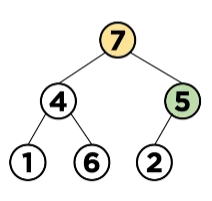
위 그림에서 다시 2번 조건으로 돌아가 힙의 조건을 만족하는 지를 봤을 때 Max Heap을 만족하는 구조이므로 삭제연산이 종료 됩니다.
맨 처음 그림과 비교하였을 때 힙의 구조를 망가트리지 않고 9만 잘 제거된 것을 볼 수 있습니다.
힙에서 삽입과 삭제는 루트 노드의 위치만 알면 되기 때문에 모두 O(log2n)의 시간 복잡도를 갖습니다.
[장점]
[단점]
IHeap interface
package heap;
public interface IHeap<T> {
void insert(T val);
boolean contains(T val);
T pop();
T peek();
int size();
}힙 구현에 있어 필요한 프로토타입을 선언합니다.
package heap;
public class MaxHeap<T extends Comparable<T>> implements IHeap<T> {
...
}최대 힙과 최소 힙 중 한 가지만 구현하면 나머지 한 가지는 부등호만 반대로 해 주면 되기 때문에 여기서는 최대 힙만 구현할 것입니다.
T[] data;
int size;
int maxSize;
public MaxHeap(int maxSize) {
this.maxSize = maxSize;
this.data = (T[]) new Comparable[maxSize + 1];
this.size = 0;
}데이터를 배열의 1번 index 부터 삽입을 하기 때문에 크기를 maxSize+1만큼 설정했습니다.
private int parent(int pos) {
return pos / 2;
}
private int leftChild(int pos) {
return pos * 2;
}
private int rightChild(int pos) {
return (2 * pos) + 1;
}트리 구조를 배열로 나타냈을 때 index를 통해 특정 노드의 위치를 찾을 수 있습니다.
private boolean isLeaf(int pos) {
return (pos > (size / 2) && pos <= size);
}리프 노드의 인덱스도 위에서 설명했듯이 인덱스를 통해 알아낼 수 있습니다.
삽입은 leaf에 데이터를 삽입한 후 값의 위치를 찾아주는 연산이 진행됩니다.
@Override
public void insert(T val) {
this.data[++this.size] = val;
int current = this.size;
while (this.data[parent(current)] != null &&
this.data[current].compareTo(this.data[parent(current)]) > 0 {
Collections.swap(Arrays.asList(this.data), current, parent(current));
current = parent(current);
})
}
@Override
public T pop() {
T top = this.data[1];//루트 노드 값
this.data[1] = this.data[this.size--];
heapify(1);
return top;
}pop()
private void heapify(int idx) {
if(isLeaf(idx)) {
return;
}
T current = this.data[idx];
T left = this.data[leftChild(idx)];
T right = this.data[rightChild(idx)];
if (current.compareTo(left) < 0 || current.compareTo(right) < 0) {
if (left.compareTo(right) > 0) {
Collections.swap(Arrays.asList(this.data), idx, leftChild(idx));
heapify(leftChild(idx);
} else {
Collections.swap(Arrays.asList(this.data), idx, rightChild(idx));
heapify(rightChild(idx);
}
}
}heapify()
public boolean contains(T val) {
for (int i = 1; i < this.size; i++) {
if (val.equals(this.data[i])) {
return true;
}
}
return false;
}힙(heap)은 BST(이진 탐색 트리)와 다르게, 값을 비교하면서 Child를 타고 내려가는 것이 아니기 때문에 for문을 통해 값 비교를 하는 방식입니다.
data에 val이 존재하면 true를 리턴하고 그렇지 않으면 false를 리턴합니다.
@Override
public T peek() {
if (this.size < 1)
throw new RuntimeException();
return this.data[1];
}가장 최상위 값인 루트 노드의 값을 가져옵니다.
@Override
public int size() {
return this.size;
}사이즈를 리턴하는 메소드입니다.
힙의 대표적인 응용 사례는 우선순위 큐가 있습니다.
우선순위 큐는 말 그대로 우선 순위가 높은 것을 먼저 꺼내기 위해 만들어진 구조이며 힙이라고도 불립니다.
여기서 의문이 생기실 수 있습니다.
그럼 배열로 각 데이터를 비교해서 새로 저장하면 되지 않나?
물론 가능하긴 하지만 효율적인 방법이 아닙니다. 왜냐하면 선형으로 처음부터 비교를 하면서 위치를 찾으면 시간복잡도 O(n)을 요구하고 n 이 충분히 크다면 시간 초과가 발생할 것이기 때문입니다.
그래서 이를 더 빠르게 구현하기 위해서 힙이 나온 것입니다.
일반 큐
우선순위 큐
package heap;
import java.util.PriorityQueue;
public class PriorityQueueTest {
static class Task {
int priority; //일의 중요도
String title; //업무 내용
public Task(int priority, String title) {
this.priority = priority;
this.title = title;
}
}
public static void main(String[] args) {
PriorityQueue<Task> pq = new PriorityQueue<>((t1, t2) -> {
return t1.priority - t2.priority;
// t1, t2를 바꿀 경우 역순 가능
});
pq.add(new Task(4, "키보드 청소하기"));
pq.add(new Task(1, "알고리즘 문제 풀기"));
pq.add(new Task(3, "취업 공고 찾아보기"));
pq.add(new Task(2, "강의 듣기"));
while (!pq.isEmpty()) {
Task task = pq.poll();
System.out.println("[중요도: " + task.priority + "]" + task.title);
}
}
}
// 출력 결과
// [중요도: 1] 알고리즘 문제 풀기
// [중요도: 2] 강의 듣기
// [중요도: 3] 취업 공고 찾아보기
// [중요도: 4] 키보드 청소하기t1의 priority 와 t2의 priority를 빼기 연산으로 어떤 것의 우선순위가 더 높은 지를 판단 하는 연산을 추가합니다.
이 연산을 통해 정해지는 우선순위를 기반으로 큐가 정렬이 되는 것입니다.
만약 이 과정을 그냥 리스트를 이용해 구현했으면 우선순위를 찾기 위해 n번의 순회를 거쳐야 하기 때문에 O(n)의 시간 복잡도를 갖습니다.
하지만 힙으로 구현하여 O(logN)의 시간 복잡도 안에 이 과정을 수행할 수 있게 되는 것입니다.
우선순위 말고도 힙 정렬이라는 알고리즘도 힙을 사용한 것 입니다..
과정은 다음과 같습니다.
이는 힙 자료구조의 특성을 이용한 정렬 방법으로 아래 그림을 한 번 보겠습니다.

그림의 왼쪽에 있는 데이터처럼 정렬 되지 않은 데이터가 들어올 때 이 데이터들로 힙 자료구조를 생성하게 됩니다. 가운데 그림을 보면 Min Heap으로 생성됨을 볼 수있습니다.
루트 노드에 대해 pop연산을 통해 데이터를 추출해 오면 항상 최솟값 만을 가져올 수 있기 때문에 정렬된 상태의 데이터를 나열할 수 있게 됩니다.
만약 Min Heap이 아니라 Max Heap이라면 오름차순으로 정렬되는 것이 아니라 내림차순으로 정렬 되는 것입니다.
또한 Dijkstra 알고리즘이라는 곳에도 쓰이기도 합니다.
Dijkstra 알고리즘의 설명은 이곳을 참조
| 정렬 방식 | Average | Worst | Memory | Stable 여부 | In-Place 여부 | Run-time(정수 60,000개) 단위: sec |
| Bubble 정렬 | O(n²) | O(n²) | O(1) | O | O | 7.438 |
| Bubble 정렬 | O(n²) | O(n²) | O(1) | X | O | 10.842 |
| Insertion 정렬 | O(n²) | O(n²) | O(1) | O | O | 22.894 |
| Shell 정렬 | O(nlog₂n) | O(n²) | O(1) | X | O | 0.056 |
| Merge 정렬 | O(nlog₂n) | O(nlog₂n) | O(1) | O | X | 0.014 |
| Quick 정렬 | O(nlog₂n) | O(n²) | O(1) | X | O | 0.034 |
| Heap 정렬 | O(nlog₂n) | O(nlog₂n) | O(1) | X | O | 0.026 |
우선 순위 큐를 이용한 알고리즘 문제
Bubble 정렬의 설명은 이곳을 참조
Insertion 정렬의 설명은 이곳을 참조
Shell 정렬의 설명은 이곳을 참조
Merge 정렬의 설명은 이곳을 참조
Quick 정렬의 설명은 이곳을 참조
Heap 정렬은 우선순위 큐에서 사용하는 정렬이므로 해당 포스팅 이곳을 참조
Topological 정렬의 설명은 이곳을 참조
| [Algorithm | Java] 깊이 우선 탐색(DFS) (그래프 탐색) 알고리즘 (4) | 2022.12.28 |
|---|---|
| [자료구조 | Java] Graph(그래프) (0) | 2022.12.28 |
| [자료구조 | Java] Tree, Binary Tree(트리, 이진 트리) (0) | 2022.12.28 |
| [Algorithm | Java] Quick Sort(퀵 정렬) (7) | 2022.12.28 |
| [Algorithm | Java] Merge Sort(합병 정렬) (0) | 2022.12.28 |
소중한 공감 감사합니다