새소식
반응형
이번 시간에는 merge sorting에 대해서 배워보도록 하겠습니다.
저번 포스팅에서 설명했던 정렬 방식들(버블 정렬, 삽입 정렬, 선택 정렬) 은 가장 기본적인 수준의 정렬 방식들입니다.
그러나 이것들은 일반적으로 좋은 성능은 낼 수 없기 때문에 실제로 개발 시에는 잘 사용하지 않습니다.
앞으로 배울 Merge / Quick 정렬은 굉장히 중요하기 때문에 자세히 알아보도록 합시다.

merge sort와 다음 시간에 배울 quick sort가 정렬 알고리즘의 핵심이라고 할 수 있습니다. 하지만 중요한 만큼 이전에 배웠던 것들과는 다르게 매우 복잡하게 진행이 됩니다.
하나의 리스트를 두 개의 균등한 크기의 리스트로 분할하고 부분 리스트를 합치면서 정렬하여 최종적으로 전체가 정렬되게 하는 방법입니다.
전반적인 과정
다음 그림은 합병정렬의 과정을 도식화 한 것입니다.
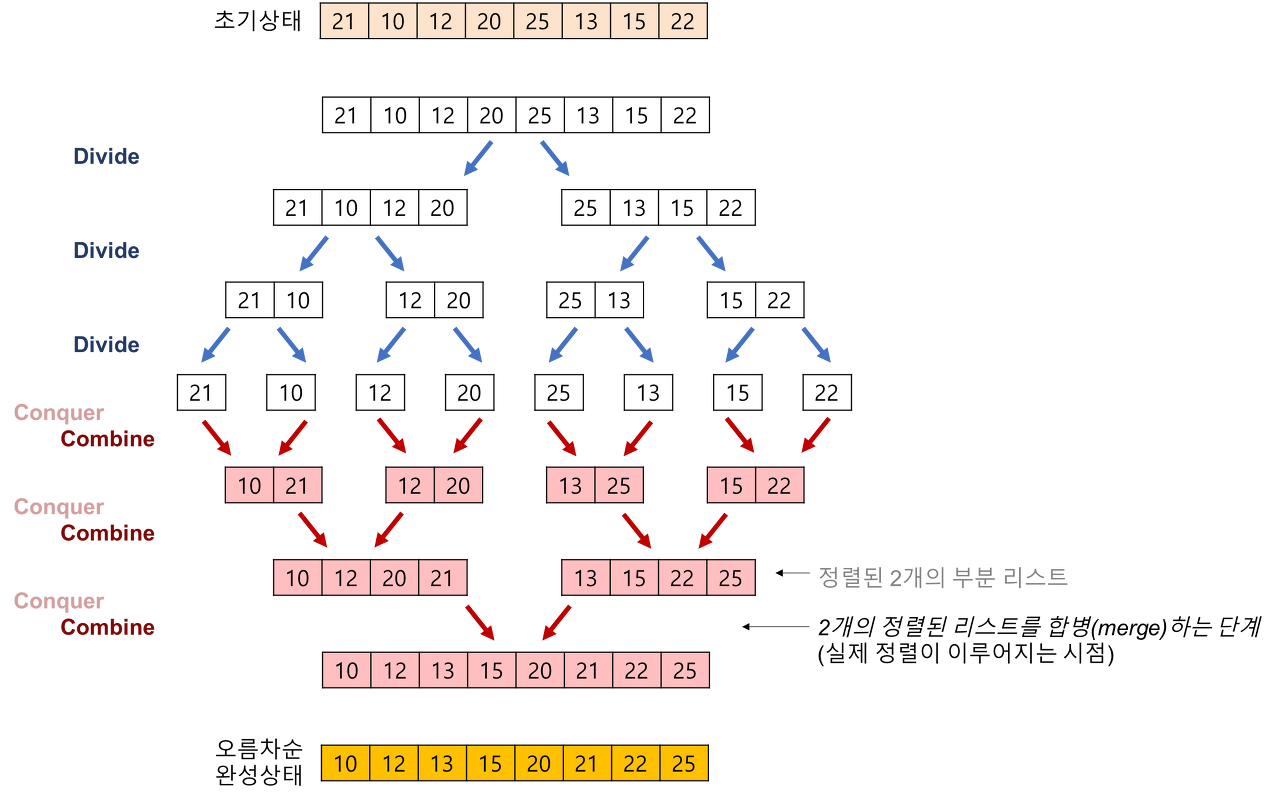
그렇다면 이 과정에 대해 하나하나 자세히 살펴 보도록 하겠습니다.
하나의 리스트를 두 개의 균등한 크기의 서브 리스트로 분할하고 분할 된 리스트를 정렬한 다음, 이 두 정렬도니 서브 리스트를 합쳐서 정련된 전체의 리스트가 되게끔 하는 방법입니다.
합병 정렬은 다음의 단계들로 이루어져 있습니다.
아래 그림처럼 정렬되기 전의 리스트가 있다고 가정합시다. 이 리스트를 크기가 같은 두 개의 리스트로 분할합니다.
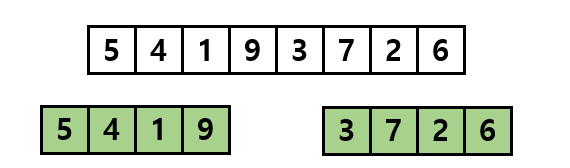
여기서 이 서브 리스트들을 또 다시 같은 크기의 두 서브 리스트로 분할합니다.

이 과정을 가장 하위의 서브 리스트의 크기가 1이 될 때까지 반복합니다. 현재 하위 서브 리스트의 크기는 2이므로 이 과정을 한 번 더 반복해 줍니다.
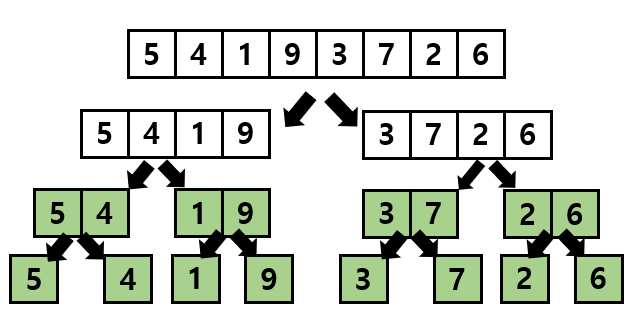
이제 크기가 1인 8개의 서브 리스트들로 분할이 되었습니다.

이제 이 분할된 부분 리스트들을 정렬하면서 다시 합쳐주는 과정(combine)을 진행합니다.
크기가 1인 부분 리스트들을 정렬하여 크기가 2인 부분 리스트로 다시 합칩니다. 이때 합치면서 각 원소들은 자신의 위치로 정렬이 되기 때문에 합쳐진 서브 리스트 들은 항상 정렬된 상태를 유지하게 됩니다.
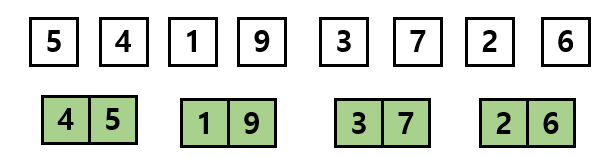
이 과정을 모든 서브 리스트들이 하나의 리스트가 될 때까지 반복해 줍니다.
다음 그림은 이 과정을 반복한 것입니다.
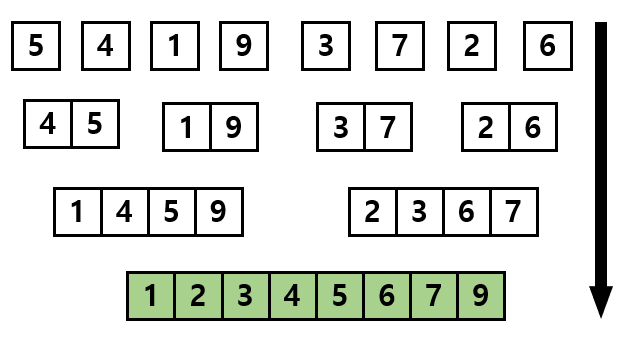
결과적으로 마지막에 합치는 과정에서 크기가 8인 정렬된 리스트를 얻을 수 있게됩니다.
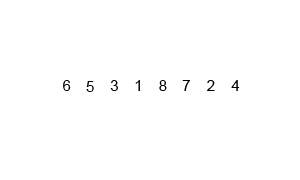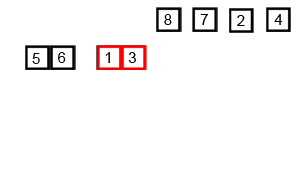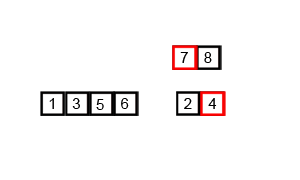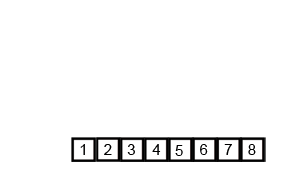
이렇게 하나의 문제를 동일한 유형의 작은 문제들로 분할한 다음, 작은 문제에 대한 결과들을 조합해서 큰 문제들을 해결하는 알고리즘을 분할 정복(Divide and conquer)이라고 합니다.
이 분할 정복은 알고리즘 풀이에 있어서 적지 않게 사용되고 보통 재귀함수로 구현이 됩니다. 그러한 이유로 merge sort 또한 재귀함수로 구현을 할 것입니다.
이에 대해서 더 자세히 다룬 포스팅은 아래 링크를 참조하세요.
[CS 지식/자료구조와 알고리즘(Java)] - [Algorithm] Divide-and-Conquer(분할 정복 알고리즘)
[Algorithm] Divide-and-Conquer(분할 정복 알고리즘)
이번 시간에는 분할 정복 알고리즘(Divide & Conquer Algorithm)에 대해서 알아보도록 할 것이다. 1. 분할 정복 알고리즘이란? 분할 정복(Divide and Conquer)는 여러 알고리즘의 기본이 되는 핵심 해결 방법으
cdragon.tistory.com
O(NlogN)
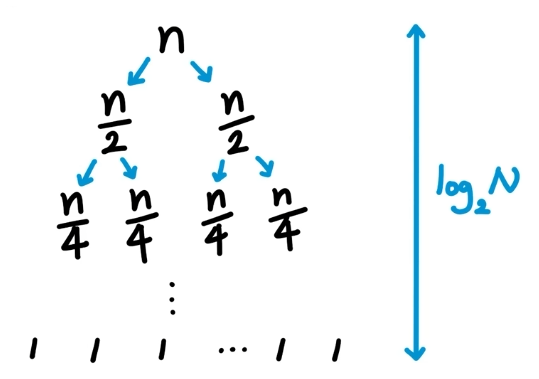
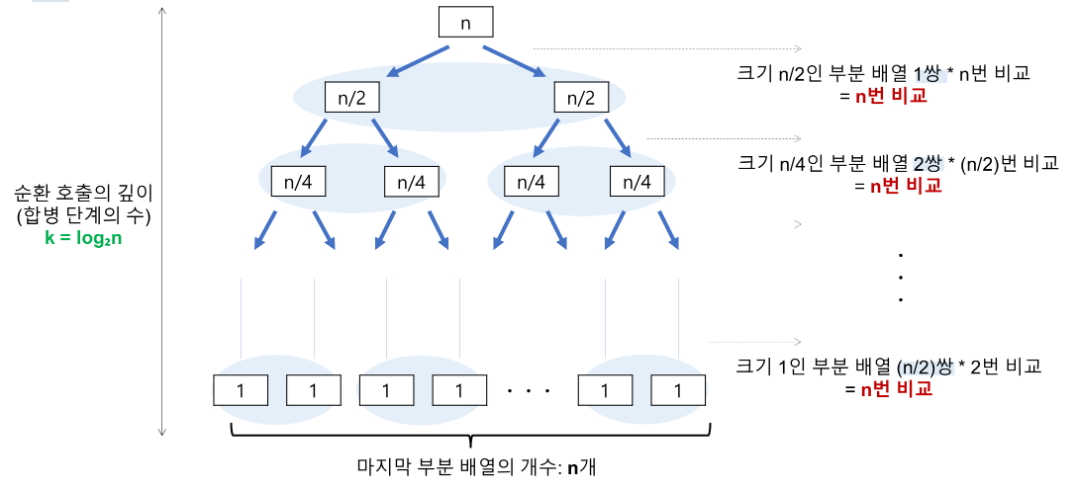
우선 분할 과정에서 리스트의 크기가 1/2씩 감소하게 됩니다. 그래서 처음 n개의 리스트에서 분할을 진행하면 n/2크기의 서브 리스트 2개를 얻게 되고 이 상태에서 분할을 다시 진행하게 되면 n/4크기의 서브 리스트 4개를 얻게 됩니다.
이러한 분할 연산을 모든 서브 리스트들의 크기가 1이 될 때까지 반복해야 하는데 리스트의 크기가 2라면 1번, 4개라면 2번, 8개라면 3번을 반복 해야 크기가 1인 리스트를 얻을 수 있습니다.
따라서, 분할 과정에서 O(log2n)의 시간복잡도를 갖게 됩니다.

또한 분할된 상태에서 리스트들을 다시 합칠 때(합병,Merge) 각 element들을 비교하면서 진행되기 때문에 리스트의 크기가 1인 상태일 때 총 n개의 리스트가 있을 것이므로 이때, n번의 비교연산을 수행하게 됩니다.
이후 합쳐진 상태에서 리스트의 크기가 n/4이고 갯수가 4개라면 또 다시 n번의 비교연산이 필요합니다. 결국 각 depth에서 n번 비교 연산을 갖게 되고 이는 O(n)의 시간 복잡도를 요구하게 됩니다.
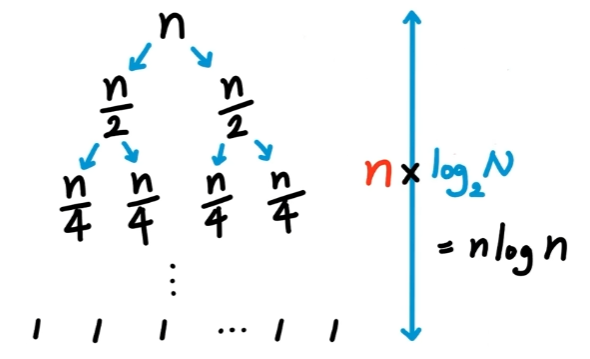
따라서 결과적으로 merge sort의 시간 복잡도는 분할과 합병과정을 합친 O(nlog2n) 의 시간복잡도를 갖게 된다.
merge sort를 구현하는 방법에는 다음과 같은 것들이 있다.
여기서는 1번 방법으로 구현을 해 보도록 할 것이다. Out-of-place 방법은 In-place 방법보다 훨씬 쉽기 때문에 혼자서도 구현을 해 볼 수 있을 겁니다.
package sort;
public class MergeSort implements ISort {
...
}
제일 처음 sort() 메소드를 살펴 보겠습니다. sort()메소드에서 In-place sort가 이루어집니다.(void 리턴)
분할과정을 먼저 살펴봅시다.
@Override
public void sort(int[] arr) {
//in-place sort
mergeSort(arr, 0, arr.length - 1);
}
//분할
private void mergeSort(int[] arr, int low, int high) {
if (low >= high) { //종료 조건
return;
}
int mid = low + ((high - low) / 2);
mergeSort(arr, low, mid);//왼쪽
mergeSort(arr, mid + 1, high);//오른쪽
merge(arr, low, mid, high);
}sort() :
초기시작이므로 처음에는 mergeSort()로 배열의 0번부터 끝까지를 index를 인자로 넘겨 분할을 진행합니다.
분할(mergeSort())
먼저 분할 과정에서 재귀 호출로 중간값을 찾아 이를 기준으로 큰 부분(오른쪽)과 작은 부분(왼쪽)의 인덱스로 나눠지게 하여 이 index를 기반으로 두 개의 서브 리스트들로 분할 되게 합니다.
종료조건은 low가 high보다 크거나 같을 때, 즉 다시 말해서 배열의 크기가 1이 되는 경우 종료하는 것으로 합니다. 종료 시 mergeSort를 호출한 곳으로 돌아갑니다.
다음으로 합병을 살펴 봅시다.
//합병
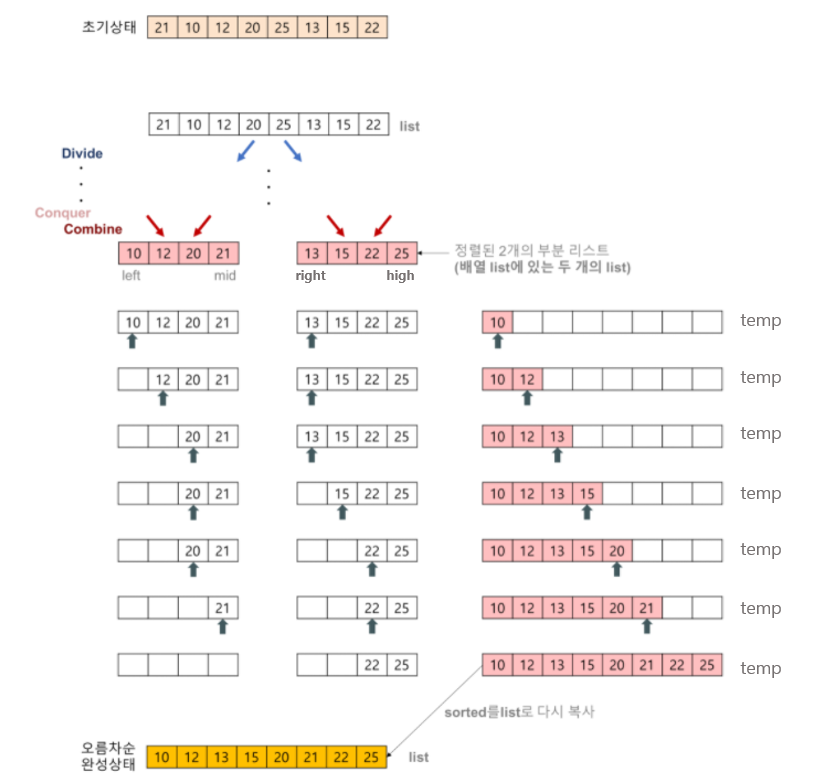
private void merge(int[] arr, int low, int mid, int high) {
int[] temp = new int[high - low + 1];
int idx = 0;
int left = low;
int right = mid + 1;
while (left <= mid && right <= high) {
if (arr[left] <= arr[right]) {
temp[idx] = arr[left];
left++;
} else {
temp[idx] = arr[right];
right++;
}
idx++
}
while (left <= mid) { //왼쪽 리스트에 값이 남아 있는 경우
temp[idx] = arr[left];
idx++;
left++;
}
while (right <= high) { //오른쪽 리스트에 값이 남아 있는 경우
temp[idx] = arr[right];
idx++;
right++;
}
for (int i = low; i <= high; i++) {
arr[i] = temp[i - low];
}
}합병(merge())
코드를 봤을 때 이해가 잘 가지 않을 수 있기 때문에 그림과 함께 설명을 덧붙이겠습니다.
합병 정렬은 일반적인 경우 다음 시간에 배울 퀵 정렬보다 느리지만 어떠한 상황에서도 정확히 O(NlogN)을 보장할 수 있다는 점에서 매우 효율적인 알고리즘이다.
| 정렬 방식 | Average | Worst | Memory | Stable 여부 | In-Place 여부 | Run-time(정수 60,000개) 단위: sec |
| Bubble 정렬 | O(n²) | O(n²) | O(1) | O | O | 7.438 |
| Bubble 정렬 | O(n²) | O(n²) | O(1) | X | O | 10.842 |
| Insertion 정렬 | O(n²) | O(n²) | O(1) | O | O | 22.894 |
| Shell 정렬 | O(nlog₂n) | O(n²) | O(1) | X | O | 0.056 |
| Merge 정렬 | O(nlog₂n) | O(nlog₂n) | O(1) | O | X | 0.014 |
| Quick 정렬 | O(nlog₂n) | O(n²) | O(1) | X | O | 0.034 |
| Heap 정렬 | O(nlog₂n) | O(nlog₂n) | O(1) | X | O | 0.026 |
정렬(Sorting)의 설명은 이곳을 참조
Bubble 정렬의 설명은 이곳을 참조
Insertion 정렬의 설명은 이곳을 참조
Shell 정렬의 설명은 이곳을 참조
Merge 정렬의 설명은 이곳을 참조
Quick 정렬의 설명은 이곳을 참조
Heap 정렬은 우선순위 큐에서 사용하는 정렬이므로 해당 포스팅 이곳을 참조
Topological 정렬의 설명은 이곳을 참조
.
| [자료구조 | Java] Tree, Binary Tree(트리, 이진 트리) (2) | 2022.12.28 |
|---|---|
| [Algorithm | Java] Quick Sort(퀵 정렬) (7) | 2022.12.28 |
| [Algorithm | Java] Insert Sort(삽입 정렬) (0) | 2022.12.28 |
| [Algorithm | Java] Bubble Sort(버블 정렬) (1) | 2022.12.28 |
| [Algorithm | Java] Sorting(정렬) (0) | 2022.12.28 |
소중한 공감 감사합니다