새소식
반응형
이번 시간에는 분할 정복 알고리즘(Divide & Conquer Algorithm)에 대해서 알아보도록 할 것입니다.
분할 정복(Divide and Conquer)는 여러 알고리즘의 기본이 되는 핵심 해결 방법으로 다음과 같은 정의를 내리고 있습니다.
문제를 즉각 해결할 수 있을 때까지 재귀적 방식을 통해 두 개 이상의 하위 문제(Sub-problems)들로 나누고(Divide 과정), 문제를 해결한 다음(Conquer 과정) 그 결과를 바탕으로 다시 전체 문제로 돌아가 합치면서 해결해 나가는 과정.
말 그래도 분할했다가 정복하는 알고리즘 인 것입니다.
다음 그림이 그 예시를 보여줍니다.
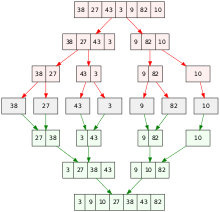
사실 분할 정복 알고리즘은 굉장히 많이 쓰는 알고리즘으로 이 수업에서도 몇 번 다룬 적이 있었습니다.
1) Quick 정렬 - 이곳을 참조
2) Merge 정렬 - 이곳을 참조
3) 이진 탐색(Binary Search) - 이곳을 참조
4) 큰 숫자 곱하기(Karatsuba Algorithm): n자리 수 2개를 곱하여 결과를 나타내는 알고리즘
5) Closest Pair of Points Problem: 모든 point의 쌍의 거리 중 최소의 거리를 찾는 문제
6) Strassens's Alogithm: 두 행렬을 곱하는 알고리즘 중 효과적인 알고리즘
7) 오토 마타: 계산 능력이 있는 추상 기계와 그 기계를 이용한 문제를 컴퓨터 과학 분야의 시각으로 접근한 학문
8) Cooley-Tukey Fast Fourier Transform(FFT) Algorithm: FFT 알고리즘
분할 정복의 과정은 간략하게 다음과 같이 진행됩니다.
위에서 예시로 들었던 병합 정렬의 애니메이션을 통해 살펴봅시다.(링크에 자세한 내용이 있다.)

이렇게 애니메이션으로 보면 너무나 쉽게 순서가 보입니다.
① 분할: 전체 데이터를 반으로 지속적으로 분할한다.
② 정복:데이터가 1개가 남으면 그 자체로 정렬된 상태라고 전 포스팅에서 말한 바 있다. 그래서 그 상태에서 분할된 2개의 데이터를 정렬한다.(하위 문제 해결)
③ 병합: 정렬된 하위 문제를 병합하여 전체 내역을 정렬한다.
분할 정복 방법은 앞서 말했듯이 재귀적으로 자신을 호출하면서 그 연산의 단위를 조금씩 줄여가는 방식이라고 설명했습니다.
따라서 이를 이용하여 분할 정복을 프로그래밍 언어의 방식으로 적용하려면 어떻게 해야할까요?
언어마다 표현 방식이 다르기 때문에 최대한 모든 언어에 적용할 수 있도록 표현하였습니다.
function F(x):
if F(x)가 간단 then:
return F(x)를 계산한 값
else:
x를 x1, x2로 분할
F(x1)과 F(x2)를 호출
return F(x1), F(x2)로 F(x)를 구한 값위 코드를 한 마디로 요약하자면, F(x)가 간단이라는 조건(정복 할 수 있는 범위)을 만족할 때까지 문제를 계속해서 쪼개서 이를 통해 최종 값을 구해내는 방식인 것입니다.
[장점]
[단점]
F(x)가 간단이라는 명제가 난이도가 어떻냐에 따라 알고리즘 퍼포먼스가 굉장히 많은 차이가 존재.F(x) 가 간단을 어떤 기준으로 잡을 것인지가 모호함.
사실 다이나믹 프로그래밍의 정의를 보면 분할 정복과 크게 다를 것이 없어보입니다.
분할 정복과 다이나믹 프로그래밍 모두 주어진 문제를 작은 문제로 작게 쪼개서 서브 문제들을 해결하고 이를 토대로 큰 문제를 해결한다는 점에서 비슷하게 보일 수 있습니다.
둘의 차이점은
위에서 예시로 들었던 합병 정렬에 대해서 생각해 보면,
합병 정렬을 수행할 때에는 작은 하위 문제로 쪼개지지만 중복된 하위 문제들이 발생하지는 않았습니다.
다시 말해서, 분할된 작은 부분들은 모두 큰 문제에 대해 독립적(independent)이고, 동일한 부분을 중복하지 않는다는 의미입니다.
그럼 중복되는 경우는 어떤 것인지 궁금할 것입니다.
다이나믹 프로그래밍 포스팅에서 설명한 부분이지만 이해를 위해 이곳에서도 설명해 보자면, 피보나치 수열에서 F(n) = F(n - 1) + F(n - 2)라는 점화식을 가지고 있다.
여기서는 n이 어떤 수던지 간에 반드시 n -1 번째 수와 n - 2번째 수를 더해야 한다는 것이 모~든 과정에서 중복되는 것을 알 수 있습니다.
즉, n=6일 때, n - 1은 5이고, n- 2는 4입니다.
그런데 5를 구하기 위해서는 n = 5의 값을 구해야 하는 것이고 이는 다시 n - 1인 4와 n - 2인 3을 다시 구해야 합니다.
결과적으로 n이 무슨 수든지 간에, 그 하위 수를 구하는 부분은 중복해서 나타납니다.(단, 피보나치의 경우 n = 1, n = 2인 경우는 제외하고)
그래서 하고 싶은 말은 문제 종류에 따라서 분할 정복이 필요한 문제가 있고 동적 프로그래밍이 필요한 문제가 있다는 것입니다.
또한, 분할 정복은 Top-down방식만 가능하지만 동적 프로그래밍은 Top-down과 Bottom-up 방식이 모두 가능하다는 차이점도 존재합니다.
읽어주셔서 감사합니다.
| [Algorithm | Java] BackTracking(백트래킹) 알고리즘 (0) | 2022.12.28 |
|---|---|
| [Algorithm | Java] Brute Force(브루트 포스, 완전 탐색) 알고리즘 (0) | 2022.12.28 |
| [자료구조 | Java] Trie(트라이) (0) | 2022.12.28 |
| [Algorithm | Java] Shell Sort(셸 정렬) 알고리즘 (0) | 2022.12.28 |
| [Algorithm | Java] Topological Sorting(위상 정렬) 알고리즘 (0) | 2022.12.28 |
소중한 공감 감사합니다