새소식
반응형
이번 시간에는 삽입 정렬(Insertion Sorting)에 대해 배워 보도록 하겠습니다.
삽입 정렬은 특정 데이터를 리스트의 앞에서부터 이미 정렬된 서브 리스트의 값들과 비교하여 자신의 위치에 삽입하는 방식입니다.
이때 서브 리스트는 이미 정렬이 되어있기 때문에 서브 리스트 안에서도 자신이 삽입이 되어야 할 위치가 정해져 있을 것입니다. 그 위치에 데이터를 삽입하는 것이 바로 삽입 정렬입니다.
예를 들어,

그렇다면 이런 의문을 가질 수 있으실 겁니다.
정렬되지 않는 리스트를 정렬하고 싶은 것인데 이미 정렬된 서브 리스트는 어디서부터 나오는 거지?
만약 사이즈가 1인 배열이 있다고 생각해 봅시다. 그렇다면 그 배열은 어떤 값이 들어있더라고 정렬된 상태라고 할 수 있을 것입니다. 아래와 같이 말입니다.
각각 크기가 1인 배열 3개가 있는 모습입니다.

삽입 정렬은 바로 이 아이디어에서 출발합니다.
가장 맨 앞의 데이터를 정렬된 서브 리스트로 보고 시작합니다.

그렇기 때문에 사실 실질적으로는 두 번째 값 index인 1부터 정렬을 본격적으로 시작하는 것입니다.
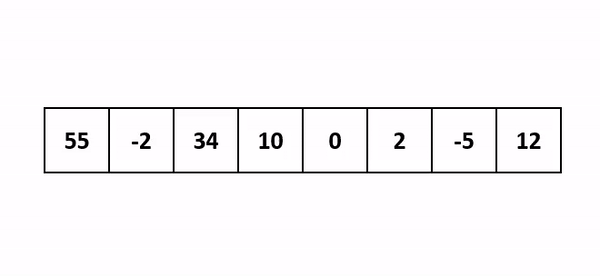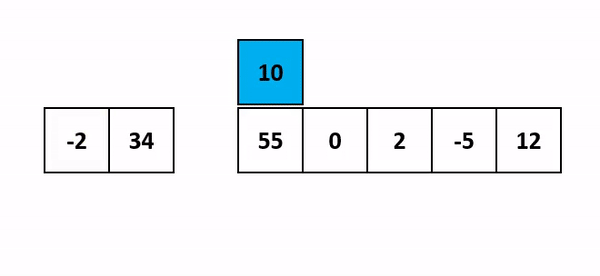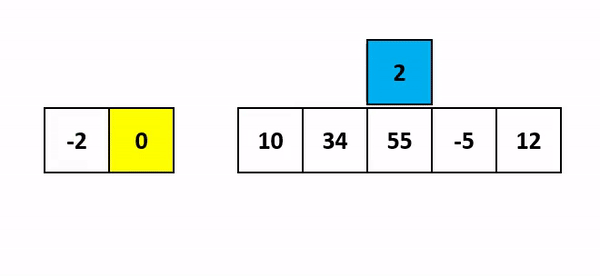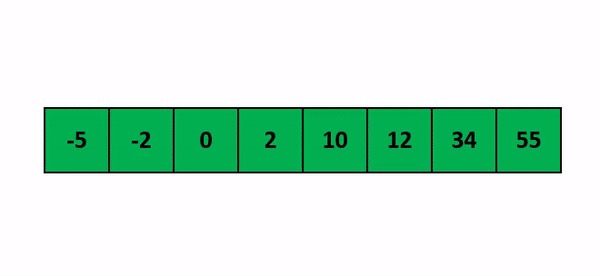
위의 예에서는 '4'라는 값을 가진 데이터는 숫자 '5' 하나만 가진 서브 리스트에 순서에 맞게 삽입해야 합니다. 그렇다면 4는 5보다 작기 때문에 서브 리스트의 0번 index에 4를 추가합니다.
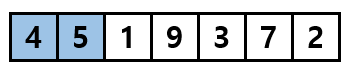
그러면 사이즈가 2인 서브 리스트가 생성이 됩니다.
이를 반복하면 서브 리스트의 크기는 점점 정렬된 상태로 커질 것이고 마지막에는 original 배열의 크기가 되어 원래의 배열을 정렬된 상태가 되는 것입니다.
그 이후에는 뻔합니다. 그 다음 값인 1을 가지고 와서 4와 5가 존재하는 서브 리스트의 어느 부분에 삽입할 지를 결정합니다. 마찬가지로 0번 index이므로 다음 그림과 같이 됩니다.

해당 과정을 거쳐 위 그림과 같이 또 정렬된 서브 리스트가 만들어지게 됩니다.
위의 과정을 반복하여 서브 리스트에 점점 값이 정렬되어 들어오게 되면서 완전히 오름차순으로 정렬된 리스트가 될 것입니다. 아래에 그 과정을 그림으로 나타냈습니다.
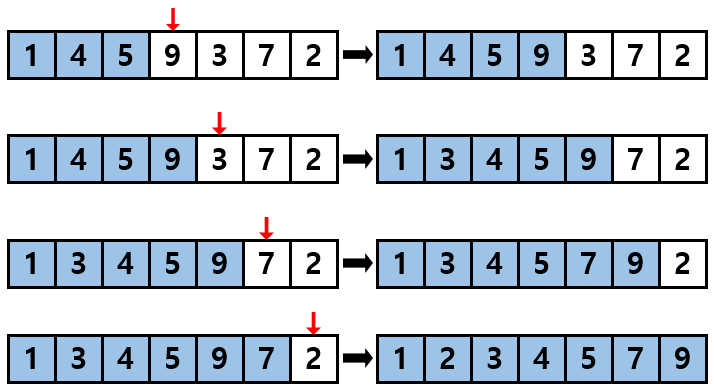
삽입 정렬을 코드로 구현해 보겠습니다.
package sort;
public class InsertionSort implements ISort {
@Override
public void sort(int[] arr) {
for (int i = 1; i < arr.length ;i++) {
int key = arr[i]; // 삽입 위치를 찾아줄 데이터
int j = i - 1; // 0 - j 정렬된 서브 리스트
while(j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
}위에서 설명했듯이 가장 맨 앞의 데이터를 서브 리스트로 생각하고 그 다음 데이터 부터 정렬을 진행하기 때문에 for문의 초기 시작은 1부터 시작합니다.
for 반복문
[장점]
[단점]
<최선의 경우>
<최악의 경우>
| 정렬 방식 | Average | Worst | Memory | Stable 여부 | In-Place 여부 | Run-time(정수 60,000개) 단위: sec |
| Bubble 정렬 | O(n²) | O(n²) | O(1) | O | O | 7.438 |
| Bubble 정렬 | O(n²) | O(n²) | O(1) | X | O | 10.842 |
| Insertion 정렬 | O(n²) | O(n²) | O(1) | O | O | 22.894 |
| Shell 정렬 | O(nlog₂n) | O(n²) | O(1) | X | O | 0.056 |
| Merge 정렬 | O(nlog₂n) | O(nlog₂n) | O(1) | O | X | 0.014 |
| Quick 정렬 | O(nlog₂n) | O(n²) | O(1) | X | O | 0.034 |
| Heap 정렬 | O(nlog₂n) | O(nlog₂n) | O(1) | X | O | 0.026 |
정렬(Sorting)의 설명은 이곳을 참조
Bubble 정렬의 설명은 이곳을 참조
Insertion 정렬의 설명은 이곳을 참조
Shell 정렬의 설명은 이곳을 참조
Merge 정렬의 설명은 이곳을 참조
Quick 정렬의 설명은 이곳을 참조
Heap 정렬은 우선순위 큐에서 사용하는 정렬이므로 해당 포스팅 이곳을 참조
Topological 정렬의 설명은 이곳을 참조
| [Algorithm | Java] Quick Sort(퀵 정렬) (7) | 2022.12.28 |
|---|---|
| [Algorithm | Java] Merge Sort(합병 정렬) (0) | 2022.12.28 |
| [Algorithm | Java] Bubble Sort(버블 정렬) (0) | 2022.12.28 |
| [Algorithm | Java] Sorting(정렬) (0) | 2022.12.28 |
| [Algorithm | Java] Jump Search(점프 탐색) (0) | 2022.12.28 |
소중한 공감 감사합니다