이번 시간에는 트리 구조에 대해서 배워보도록 하겠습니다.
1. 트리(Tree)란?


트리란 노드들이 나무 가지처럼 연결된 비선형(non-linear), 계층적 자료구조로 위 그림처럼 나무를 거꾸로 뒤집어 놓은 것과 같은 모양이어서 트리(tree)라는 이름을 가지게 된 자료구조입니다.
개요
트리는 한 노드가 여러 노드를 가르킬 수 있는 비선형적 자료구조를 일컫는 말입니다.
앞서 배웠던 리스트(List), 스택(Stack), 큐(Queue)는 이전 데이터와 다음 데이터 간의 순서가 존재했습니다.
트리도 물론 내부적으로 순서 정보를 가지도록 구현할 수도 있지만 트리 구조자체의 특성상 순서는 그렇게 중요하지 않습니다.
그래서 트리는 뒤에서 배우게 될 그래프(Graph)의 일종이며 데이터 구조의 상하 개념 계층의 구조적 속성을 표현한다는 특징도 있습니다.
다음 사진처럼 우리가 자주 쓰는 컴퓨터의 파일, 폴더의 계층 구조를 트리 구조라고 할 수 있습니다.

1-1. 관련 용어
트리의 구조를 그림을 통해 살펴보면서 이와 관련된 용어에 대해 정리를 해 보도록 하겠습니다.

- Node: 트리 구조에서 각 구성요소를 의미하는 단위
- 위 그림에서는 A~J까지를 모두 Node라고 할 수 있다.
- Root Node: 트리의 시작 노드로, 부모가 없는 최상위 노드
- 위 그림에서 A노드를 의미
- 트리는 최대 1개의 Root Node를 가질 수 있다.
- Edge: 노드와 노드 간의 연결을 하는 선
- Path: 특정 노드에서 노드까지의 경로 (순서)
- 한 번 지나쳤던 경로를 다시 지나는 것은 허락하지 않는다.
- Terminal Node(Leaf Node): 자식 노드가 존재하지 않는, 즉 다시 말해 밑으로 또 다른 노드가 연결 되어있지 않는 노드
- 위 그림에서 H, I, J, F, G와 같은 노드를 말한다.
- Sub-Tree: 전체 큰 트리 구조 안의 작은 트리 구조
- 트리의 재귀적인 특성을 보여준다.
- Depth: 루트 노드로부터 얼마나 떨어져 있는 지를 뜻하는 단위
- 루트 노드의 바로 아래 노드는 depth 1로 잡는다.
- 루트 노드가 기준이기 때문에 루트 노드는 depth 0이다.
- Level: 트리 구조에서 같은 위치, 즉 같은 depth를 가지는 노드들을 한 레벨로 나타내는 단위
- Root Node가 기준이고 이 위치를 level 0으로 잡는다.
- 루트 노드에서 어떤 노드까지의 간선 수이다.
- Height: 트리에서 가장 최고 레벨, 가장 깊은(deep) 층
- 어떤 노드에서 리프 노드까지 가장 긴 경로의 간선 수이다.
- Order: 부모 노드가 가질 수 있는 최대 자식의 수
- 예를 들어 order 4라고 하면 부모 노드는 최대 3명의 자식 노드를 가질 수 있는 것이다.
또한 상위 노드를 부모 노드라 하며 부모 노드에서 파생된 노드를 자식 노드라 합니다.
이때, 같은 부모를 가진 노드를 형제 관계(Sibling)에 있다고 하며, 자식 수를 차수로 나타내어 degree라고도 합니다.
예를 들어, 위 그림에서 Node D는 H, I 노드의 부모(Parent) 노드이며, degree 2의 차수를 갖는 노드입니다.
1-2. 트리 종류
- 편향 트리(skew tree)
- 모든 노드들이 자식 노드를 하나씩만 가진 트리입니다. 경사 트리라고도 불립니다.
- 또한 아래 그림은 왼쪽 자식만 존재하기 때문에 left skew tree라고 합니다.

- 이진 트리(Binary Tree)
- 뒤에서 배울 내용으로 각 노드의 차수(자식 노드)가 2이하인 트리 구조입니다.
- 이진 탐색 트리(Binary Search Tree, BST)
- 이 역시도 조금 있다가 배울 것이지만 굉장히 중요한 트리 구조로 BST라고도 하며 순서화된 이진 트리입니다.
- 노드의 왼쪽 자식은 부모의 값보다 항상 작은 값을 가져야 하고 노드의 오른쪽 자식은 부모의 값보다 항상 큰 값을 가져야 한다는 규칙이 존재합니다.
- m원 탐색 트리(m-way Search Tree)
- 최대 m 개의 서브 트리를 갖는 탐색 트리입니다.
- 이진 탐색 트리의 확장된 형태로 높이를 줄이기 위해 사용합니다.
- 균형 트리(Balanced Tree, B-Tree)
- m원 탐색 트리에서 높이 균형을 유지하는 트리입니다.
- height-balanced m-way tree라고도 합니다.
1-3. 사용 예
트리는 굉장히 많은 곳에서 사용되고 있습니다.
<계층적인 데이터 저장>
- 트리는 데이터를 계층 구조로 저장하기 때문에 파일 이나 폴더와 같이 계층구조를 갖는 곳에 사용됩니다.
<효율적인 검색 속도>
- 효율적인 삽입, 삭제, 검색을 위해 트리 구조를 사용합니다.
<힙(Heap)>
- 이후에 배울 힙(heap)도 트리를 이용한 구조입니다.
- Heap 정렬은 우선순위 큐에서 사용하는 정렬로 이곳을 참조
<데이터 베이스 인덱싱>
- 데이터베이스 인덱싱을 구현하는데 트리를 사용합니다.
- 컴퓨터 공학적 지식에서 굉장히 중요한 일입니다.
- 예) B-Tree, B+Tree, AVL-Tree
<Trie 자료구조>
- 사전(Dictionary)을 저장하는 데 사용되는 특별한 종류의 트리입니다.
- Trie에 대한 설명은 이곳을 참조
2. 이진 트리
자 그럼 트리 구조 중에서 이진 트리에 대해 배워 보도록 합시다.
이진 트리는 다음과 같은 특징을 갖습니다.
- 각 노드가 최대 2개(0-2)의 자식 노드를 가지는 트리를 의미합니다.
- 자식 노드에는 왼쪽 자식 노드와 오른쪽 자식노드가 있으며 이 둘은 엄연히 다른 노드입니다.
- 최대 2개라는 것은 자식이 없을 수도(0개) 있고 1개만 있을 수도 있다는 것입니다.

2-1. 이진 트리 유형
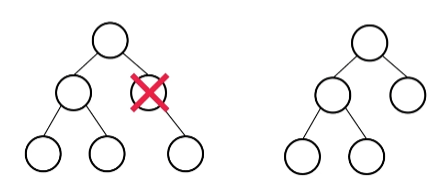
<정 이진 트리(full binary tree) (or 엄격한 (strict) 이진 트리)>
: 모든 노드가 2개의 자식을 가지는 트리를 의미합니다. (즉 자식 노드가 1개인 노드가 아예 없어야 만족한다.)
왼쪽 그림은 자식 노드가 하나인 노드가 존재하기 때문에 정 이진 트리가 될 수 없고 오른쪽 그림은 자식 노드가 하나인 노드가 존재하지 않기 때문에 정 이진 트리라고 할 수 있습니다.
<포화 이진 트리(Perfect Binary tree)>
: 모든 노드가 2개의 자식을 가지고 leaf 노드가 모두 같은 레벨인 트리입니다.
높이가 h일 때 노드 갯수는 2k+1 - 1 개를 가진다는 특징있습니다. 이 때, Leaf 노드의 갯수는 2h 개가 됩니다.


<완전 이진 트리(Complete Binary Tree)>
다음 두 조건을 만족할 대 완전 이진 트리라고 합니다.
- 마지막 레벨을 제외하고 모든 노드가 채워진 트리 구조입니다.
- 노드는 왼쪽에서 오른쪽으로 채워져야 합니다.
아래 그림에서 왼쪽과 오른쪽 그림 모두 완전 이진 트리라고 할 수 있습니다. 만약 왼쪽그림에서 level 1의 오른쪽 노드의 자식 노드가 오른쪽 자식 노드만 있었다면 완전 이진 트리가 될 수 없는 것입니다.

포화 이진 트리는 완전 이진 트리의 조건을 모두 만족하므로
포화 이진 트리는 완전 이진 트리에 속한다라고 볼 수 있고 이 명제의 역은 무조건 성립하는 것은 아니다.
아래 그림은 완전 이진 트리가 될 수 없는 구조를 보여주고 있습니다.

2-2. 1차원 배열로 표현하는 이진 트리
트리는 선형 구조인 1차원 배열로도 표현이 가능합니다.
아래의 그림을 살펴봅시다.

왼쪽 트리는 level 순, 그 이후엔 왼쪽에서 오른쪽 순서로 각 노드에 index를 붙여 표현 가능합니다.
따라서 완전 이진 트리는 위의 그림과 같이 배열을 빈틈없이 모두 채울 수 있습니다.
더 쉽게 이해 되도록 그림을 추가하였습니다.

완전 이진 트리는 왼쪽 노드에서 오른쪽 노드 순서로 채워진다는 것이 중요한 사실입니다.
경사 이진 트리같은 경우에는 위 오른쪽 그림철머 배열에 빈 공간이 생기기 때문에 불필요한 공간이 낭비 될 수 있고 배열 크기를 넘어가는 노드를 추가할 수 없다는 점이 단점입니다.
또한, 중간이 비어있는 트리의 경우(왼쪽 자식 노드는 있는데 오른쪽 자식 노드는 없는 경우) 배열 사이에 null 값이 들어간 구조로 나타나게 됩니다.

한 가지 신기한 점은 배열을 사용할 때, 0번 index는 비우고 1번 index 부터 Root Node를 채운 점인데, 그 이유는 이렇게 함으로써 탐색을 쉽게 할 수 있기 때문입니다.
다음 표는 이진 트리의 속성으로 인해 정해지는 배열의 인덱스입니다 .
| 노드 위치 |
index |
| 루트 노드 | 1 |
| 노드 i의 부모 | i/2 |
| 노드 i의 왼쪽 자식 | i * 2 |
| 노드 i의 오른쪽 자식 | i * 2 + 1 |
| 노드 위치 | index |
| 루트 노드 | 0 |
| 노드 i의 부모 | (i - 1) / 2 |
| 노드 i의 왼쪽 자식 | i*2 + 1 |
| 노드 i의 오른쪽 자식 | i*2 + 2 |
이로써 우리는 위 표와 같은 식 연산을 통해 쉽게 특정 노드의 index를 찾을 수 있습니다.

- 6의 index를 찾도록 해 봅시다.
- 6은 노드 3의 왼쪽 자식 노드입니다.
- 표의 3번째 식을 통해 3 * 2 = 6 입니다.
- 따라서 6의 index는 6입니다.
그래서 이진 트리를 구현함에 있어서 노드를 사용할 것인데 이때 left 노드와 right노드를 통해 구현할 것입니다.
class Node {
int data;
Node left;
Node right;
}
연결 리스트를 사용하면 배열 보다는 접근(access) 속도는 느리지만(random access가 불가하기 때문) 삽입, 삭제가 쉽고 노드를 포인터로 연결하는 개념이기 때문에 노드 수에 제한이 없습니다.
- LinkedList(연결리스트)의 설명은 이곳을 참조
2-3. 이진 트리의 응용
- 힙(Heap)
- 이진 탐색 트리 (Binary Search Tree)
- B-Tree
- AVL 트리(Adelson-Velsky and Landis에서 따온 이름)
- 수식 트리(Expression Tree)
- 허프만 코딩 트리(Huffman coding tree)
- 우선 순위 큐(PQ)
바로 다음 챕터에서 배울 힙(Heap) 구조라는 것도 트리의 한 가지이고, Binary Search Tree 줄여서 BST라고 하는 것도 이진 트리 구조입니다.
또한 B-Tree라는 것은 이진 트리의 응용으로 데이터 베이스나 파일 시스템에 사용되는 중요한 구조입니다.
2-4. 이진 트리의 기본 연산
트리도 자료 구조이기 때문에 앞에서 배운 다른 구조들과 동일하게 다음과 같은 연산이 가능합니다.
- 트리에 데이터 삽입하기
- 데이터 삭제하기
- 데이터 검색하기
- 트리 탐색하기
앞에서 배웠던 선형 자료구조들은 앞에서부터 데이터를 탐색하는 것이 그렇게 어렵지 않은 작업이었는데 연결 관계로 표현되는 구조는 그들의 특성상 탐색하는 방식이 선형 구조와 다를 수 밖에 없습니다.
그래서 트리 구조의 탐색은 더욱 신경써서 다뤄 보도록 하겠습니다.
2-5. 트리 순회
트리 순회에 대해서 자세히 알아보도록 합시다.
[트리 순회란?]
트리 구조에서 각 노드를 한 번씩 방문하는 과정을 말합니다.
[트리 순회 방법]
- 전위 탐색 (preorder)
- 중위 탐색 (inorder)
- 후위 탐색 (postorder)
노드 방문을 언제 하느냐에 따라 순회 방법이 나뉘어집니다.
1. Preorder(전위)
- 이름 그대로(pre-) 노드를 가장 먼저 방문
- 이후 왼쪽 서브 트리를 preoder (재귀 호출로).
- 오른쪽 서브 트리를 preorder.
2. Inorder(중위)
- 먼저 왼쪽 서브 트리를 inorder.
- 그 다음에 중간에(루트)노드를 방문.
- 오른쪽 서브 트리를 inorder(재귀적으로).
3. Postorder(후위)
- 먼저 왼쪽 서브 트리를 postorder.
- 오른쪽 서브 트리를 postorder.
- 마지막으로 (루트)노드를 방문.
자 그럼 그림을 통해 전, 중, 후위 탐색이 각각 어떻게 이루어 지는 지 보도록 합시다.

Preorder

먼저 전위탐색은 각 노드가 루트 노드 - 왼쪽 서브 트리 - 오른쪽 서브 트리 순으로 preorder를 진행합니다.
[순서]
- 노드 방문
- 왼쪽 서브 트리 preorder
- 오른쪽 서브 트리 preorder
이것이 모두 만족해야 해당 노드의 preorder가 끝난 것임을 유의합시다.

자 그럼 루트 노드인 A노드부터 시작해 보도록 하겠습니다.
- A 노드 방문(A 노드: 1번 만족 = A1)
- 왼쪽 서브 트리인 B 노드 방문(B1, A12)
- 왼쪽 서브 트리인 D 노드 방문 (D1, B12)
- D노드는 왼쪽 노드가 없고 오른쪽 노드만 있기 때문에 H 노드 방문(H1)
- H노드는 leaf노드이기 때문에 preorder가 완료되었고 이에 따라 D노드도 자동적으로 preorder가 완료. (H123, D123)
- D 노드는 B노드의 왼쪽 노드이었기에 그 다음은 B의 3번 조건을 만족 시키기 위해 오른쪽 노드인 E노드에 방문.(B123, E1)
- 왼쪽 서브 트리인 B 노드 방문(B1, A12)
이러한 방식으로 모든 노드가 preorder가 될 때까지 반복합니다.
Path(노드 방문 순서)를 나타내면 다음과 같습니다.
A - B - D - H - E- C- F - I - J - G - K
Inorder

중위 탐색은 각 노드가 왼쪽 서브 트리 - 루트 노드 - 오른쪽 서브 트리 순으로 preorder를 진행합니다.
[순서]
- 왼쪽 서브 트리 inorder
- 노드 방문
- 오른쪽 서브 트리 inorder
가 되며 이것이 모두 만족해야 해당 노드의 inorder가 끝난 것임을 유의합시다.

중위 탐색에서는 루트 노드인 A에서 시작했을 때 1번 조건이 노드 방문이 아니므로 왼쪽 서브 트리를 탐색하면서 시작합니다.
- A 노드는 그래서 처음에 방문을 한것이 아니라 중간에 방문한 노드가 되는 것입니다.
이 과정으로 inoder를 진행하며 거쳐가는 노드 path(노드 방문 순서)는 다음과 같습니다.
D- H - B- E - A - I - F - J - C - G - K
Postorder

후위 탐색은 각 노드가 왼쪽 서브 트리 - 루트 노드 - 오른쪽 서브 트리 순으로 preorder를 진행한다.
[순서]
- 왼쪽 서브 트리 postorder
- 오른쪽 서브 트리 postorder
- 노드 방문
가 되며 이것이 모두 만족해야 해당 노드의 postorder가 끝난 것임을 유의합시다.

후위 탐색에서는 루트 노드인 A에서 시작했을 때 1번 조건이 왼쪽 서브 트리를 탐색하면서 시작합니다.
- 왼쪽과 오른쪽 서브 트리를 모두 탐색한 후에 노드를 방문할 수 있기 때문에 A 노드가 가장 마지막에 방문한 것이 됩니다.
그 후 이 과정으로 재귀 호출로 계속 반복하며 postorder를 진행하며 거쳐가는 노드 path(노드 방문 순서)는 다음과 같습니다.
H- D - E - B - I - J - F - K - G - C - A
2-6. 정리
| Pre-order | In-order | Post-order |
| A - B - D - H - E- C- F - I - J - G - K | D- H - B- E - A - I - F - J - C - G - K | H- D - E - B - I - J - F - K - G - C - A |
전위 탐색에서는 루트 노드를 가장 먼저 방문하였고,
중위 탐색에서는 루트 노드를 중간에(루트 노드의 왼쪽 노드가 방문된 후에)방문하였으며,
후위 탐색에서는 루트 노드를 가장 마지막에(루트 노드의 왼쪽, 오른쪽 노드를 모두 방문된 후에) 방문한 것을 알 수 있다.
3. 이진 탐색 트리(Binary Search Tree - BST)
이번엔 이진 탐색 트리에 대해서 배워 보겠습니다.
트리 구조 자체적으로는 데이터의 특성에 아무런 제약이 걸리지 않습니다. 그렇기 때문에 트리 노드를 하나하나씩 방문하여 탐색해야 하기 때문에 시간 복잡도 측면에서 큰 이점을 얻지 못합니다.
이에 대하여 더 빠른 탐색을 위해서 데이터 특성에 제약을 줌으로써 Binary Search와 마찬가지로 O(log2n)의 시간 복잡도를 가지며 나온 것이 이진 탐색 트리라고 할 수 있습니다.
그렇다면 데이터 특성에 어떤 제약을 주는 것일까요?
3-1. 이진 탐색 트리 특징
- 이진 탐색 트리도 이진 트리 구조로 이루어져 있다.
- 노드의 왼쪽 서브 트리에는 루트 노드보다 작은 값이 들어있다.
- 노드의 오른쪽 서브 트리에는 루트 노드보다 큰 값이 들어있다.
- 서브 트리 또한 이진 탐색 트리 구조이다.
- 중복된 값은 일체 없다.
3-2. 이진 탐색 트리 방식
그림을 통해 이진 탐색 트리가 어떤 방식으로 이루어져 있는지를 보도록 하겠습니다.

루트 노드인 5를 기준으로 왼쪽 서브 트리에는 5보다 작은 수로 구성 되어있고 오른쪽 서브 트리에는 5보다 큰 수로 구성 되어 있습니다.

연속적으로 하위의 서브 트리를 봐도 각 루트 노드를 기준으로 오른쪽과 왼쪽이 작은 수와 큰 수로 나뉘어져 있는 것을 볼 수 있습니다.
[트리의 최솟값]

트리의 최솟값은 위의 그림처럼 트리 구조의 가장 왼쪽 끝에 위치한 노드가 최솟값이 됩니다. 만약 1의 왼쪽 자식 노드가 있다면 그 노드가 최솟값이 될 것입니다.
[트리의 최댓값]

반대로 트리의 최댓값은 위의 그림처럼 트리 구조의 가장 오른쪽 끝에 위치한 노드가 최댓값이 됩니다. 만약 9의 오른쪽 자식 노드가 있다면 그 노드가 최댓값이 됩니다.
다음과 같은 이진 탐색 트리가 있다고 합시다.

이 트리 구조를 중위 탐색 하면 오름 차순으로 숫자를 가져올 수 있게 됩니다.
- 중위 탐색
- 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 -> 9
이진 탐색 트리는 중위 탐색(Inorder)을 하면 오름 차순으로 인덱스를 탐색 할 수 있습니다.
3-3. 이진 탐색 트리 생성
이진 탐색 트리를 생성할 때는 데이터의 크기를 비교해 가면서 노드를 추가해 갑니다.
[50, 15, 62, 80, 7, 54, 11]위의 데이터들로 이진 탐색 트리를 생성해 보도록 하겠습니다.
- 50이 배열의 첫 번째 데이터이기 때문에 루트 노드로 트리에 삽입합니다.
- 다음 요소를 계속해서 읽고 해당 노드가 루트 노드 요소보다 작으면 왼쪽 하위 트리의 루트로 삽입합니다.
- 그렇지 않으면 오른쪽 하위 트리의 오른쪽 루트로 삽입합니다.

3-4. 이진 탐색 트리의 삽입
기존의 이진 탐색 트리에서 삽입하는 과정은 굉장히 중요합니다.
삽입 과정의 특징을 먼저 살펴 보겠습니다.
- 가장 먼저 해당 데이터가 자신이 들어갈 위치를 찾아야 합니다.
- 그리고 중복된 데이터는 삽입하지 않습니다.
- 그렇기 때문에 만약 숫자를 삽입하려 하는데 탐색을 하다가 같은 숫자가 있는 것을 발견하면 삽입하지 않고 그대로 종료하게 됩니다.
- 데이터를 삽입하거나 삭제하더라도 그 특성이 유지되어야 합니다.
- 추가된 노드는 트리의 leaf 노드에 삽입을 합니다.
- 자식 노드가 3개를 넘으면 안 되기 때문이다.(이진 트리의 특성)
[과정]

만약, 1이라는 데이터를 위 이진 탐색 트리에 삽입하고자 합니다. 그 경우 과정은 다음과 같습니다.
- 그럼 먼저 루트 노드인 8과 비교합니다.
- 1은 루트노드 8보다 더 더 작기 때문에 왼쪽 노드인 5와 다시 비교합니다.
- 5와 비교했을 때도 더 작기 때문에 또 왼쪽 노드로 이동하여 2와 비교합니다.
- 2와 비교했을 때도 더 작은데 왼쪽 노드가 비어있기 때문에 2의 왼쪽 노드에 삽입합니다.
3-5. 이진 탐색 트리의 삭제
삽입은 leaf노드의 위치만 잘 찾아서 삽입만 하면 되는 삭제는 좀 더 까다롭습니다. leaf노드만 삭제 되는 것이 아니라 트리 구조 중간에 위치한 노드도 삭제 될 수 있기 때문입니다.
삭제 과정을 한 번 보겠습니다.
[과정]
삭제 데이터의 위치를 찾습니다.
이때 데이터의 위치는 세 가지로 나뉘어집니다.
- 삭제할 데이터가 leaf인 경우
- 한 개의 자식 노드를 가질 경우
- 두 개의 자식 노드를 가질 경우
이 세 가지 경우를 아래와 같은 이진 탐색 트리에 대해서 생각해 보겠습니다.

1. 삭제 할 데이터가 leaf 노드인 경우

삭제 할 데이터가 leaf인 경우 초기 그림 상에서 2와 8을 의미합니다. 이때는 null을 부모 노드에게 리턴시켜서 자신을 가리키던 자식 포인터를 null로 바꿔주면 됩니다.
2. 한 개의 자식 노드를 가질 경우

삭제하고자 하는 노드가 한 개의 자식 노드를 가질 경우에 해당 노드의 자식 노드를 1의 부모 노드였던 3의 자식 노드를 가리키던 포인터와 연결 시켜 주면 됩니다.
그러면 다음 그림과 같이 되어 이진 탐색 트리의 속성이 유지 되는 것입니다.

3. 두 개의 자식 노드를 가질 경우
삭제 하고자 하는 노드가 두 개의 자식 노드를 가질 경우에는 두 가지 옵션이 존재합니다.
- 왼쪽 서브 트리의 최댓값과 교체
- 오른쪽 서브 트리의 최솟값과 교체

저는 두 번째 방법인 오른쪽 서브 트리의 최솟값과 교체하는 방법을 사용해 보겠습니다.
이때 오른쪽 서브 트리의 최솟값, 즉 inorder 순회에서 다음 노드는 successor(후임) 노드라고 합니다.
과정은 다음과 같습니다.
- 삭제할 노드를 찾는다.
- 삭제할 노드의 successor 노드를 찾는다.
- 삭제할 노드와 successor 노드의 값을 바꾼다.
- successor 노드를 삭제한다. (연결을 끊는다.)

7의 오른쪽 서브 트리에는 8과 9가 존재하여 이 중 최솟값인 8(successor 노드)과 삭제하고자 하는 노드 7을 교체합니다.
이런 과정을 통해 8이라는 데이터가 중복되기 때문에 leaf 노드의 8을 지워주어야 합니다.

이때 지워야 하는 8은 leaf 노드이기 때문에 위 1번 방법으로 null을 대입하여 삭제를 해 주면 아래 그림과 같이 됩니다.

결과적으로 이진 탐색 트리의 구조가 망가지지도 않았고 원하는 노드만 삭제를 했기 때문에 깔끔하게 진행이 된 것을 확인 할 수 있습니다.
3-6. 이진 탐색 트리의 검색(Search)
이진 탐색 트리에서 특정 요소의 위치를 찾는 연산입니다.
과정은 다음과 같다.
[과정]
- 루트에서부터 출발한다.
- 검색 값을 루트 노드와 비교한다.
- 루트보다 작으면 왼쪽에 대해 재귀 호출을 진행하고, 크다면 오른쪽에 대해 재귀 호출을 진행한다.
- 일치하는 값을 찾을 때까지 절차를 반복한다.
- 만약 검색 값이 없다면 null을 반환한다.
3-7. 이진 탐색 트리 구현
이제는 그럼 코드로 구현해 보겠습니다. 이진 탐색 트리는 오히려 코드로 보면서 이해하는 것이 더 도움이 되실 수 있습니다.
ITree 인터페이스
package tree;
public interface ITree<T> {
void insert(T val);
void delete(T val);
boolean contains(T val);
int size();
}트리 구조에 필요한 기능(메소드)들을 inteface를 선언하여 포로토타입으로 선언하였습니다.
이외의 preorder, inorder, postorder와 같은 탐색 기능은 따로 트리 클래스에서 구현해 보도록 하겠습니다.
BinarySearchTree 클래스
package tree;
import java.util.List;
public class BinarySearchTree<T extends Comparable<T>> implements ITree<T> {
...
}노드 클래스
private class Node {
T data;
Node left;
Node right;
Node(T data) { this.data = data;}
Node(T data, Node left, Node right) {
this.data = data;
this.left = left;
this.right = right;
}
}노드를 사용하여 구현할 것이기 때문에 노드 클래스를 만들어 줍니다.
멤버 변수
private Node root;
private int size;루트 노드를 가리키는 변수와 트리 구조 크기를 나타내는 변수 size를 선언합니다.
생성자
public BinarySearchTree() {
this.root = null;
this.size = 0;
}루트 노드가 시작이기 때문에 값에 null을 대입하고 size는 0으로 초기화 시킵니다.
min(), minNode()
트리의 데이터 중 가장 작은 값(최솟값)을 찾아주는 메소드입니다.
public T min() {
return this.minNode(this.root);
}
private T minNode(Node node) {
T minData = node.data;
while (node.left != null) {
minData = node.left.data;
node = node.left;
}
return node;
}가장 왼쪽의 값을 가져 오는 것이기 때문에 루트 노드부터 시작하여 left 자식 노드를 계속 타고 들어가서 가장 마지막 값을 반환하면 됩니다.
minNode() :
- minData에는 최솟값을 계속해서 업데이트를 해 줄 것입니다.
- 반복문을 통해 left노드가 null일 때까지 반복해 줍니다.
- 반복문 안의 내용은 현재의 노드를 left노드로 계속해서 초기화 하면서 타고 들어가며, 각 노드의 데이터를 minData변수에 업데이트를 해 줍니다.
- 그러면 반복문이 끝났을 때는 더 이상 타고 들어갈 곳이 없는 가장 왼쪽 노드의 값을 가져오게 됩니다.
min() :
루트 노드부터 시작하여 타고 내려가기 때문에 인자로 루트 노드를 넘겨 minNode()의 리턴값을 리턴합니다.
max(), minMax()
max() 메소드는 위의 min() 메소드와 다르게 최댓값을 찾는 것이므로 방향만 바꾸어 가장 오른쪽 값을 가져오도록 합니다.
public T max() {
return this.maxNode(this.root);
}
private T maxNode(Node node) {
T maxData = node.data;
while (node.right != null) {
maxData = node.right.data;
node = node.right;
}
return node
}
전위 탐색 - preOrder()
public List<T> preOrder() {
return this.preorderTree(this.root, new ArrayList<>());
}
private List<T> preorderTree(Node node, List<T> visited) {
if(node == null) return visited;
visited.add(node.data);
preorderTree(node.left, visited);
preorderTree(node.right, visited);
return visited;
}- 노드 방문
- 왼쪽 서브 트리 preorder
- 오른쪽 서브 트리 preorder
전위 탐색의 순서에 맞게 코드를 구현했습니다.
preorderTree()
visited는 노드가 방문 했음을 기록하는 리스트 객체이고 이곳에 방문한 node의 데이터를 반복적으로 넣어줍니다.
그리고 왼쪽 서브트리에 대해 반복적으로 재귀 호출을 진행하고 완료되면 오른쪽 서브 트리에 대해 반복적으로 재귀 호출이 진행되도록 합니다.
그리고 재귀가 종료조건 없이 계속해서 호출되면 오류가 발생할 수 있기 때문에 if문으로 node가 null일 때, 즉 leaf 노드의 다음 노드를 방문 시 return 하여 종료하도록 메소드 가장 앞에 작성해 주었습니다.
- 재귀 호출을 통해 left에 대한 탐색이 모두 종료가 되어야 return visited를 하면서 종료가 되고 자연스럽게 다음 코드인 right에 대한 재귀 탐색이 이루어 지게 되는 구조입니다.
중위 탐색 - inOrder()
public List<T> inOrder() {
return this.inorderTree(this.root, new ArrayList<>());
}
private List<T> inoderTree(Node node, List<T> visited) {
if(node == null) return visited;
inorderTree(node.left, visted);
visited.add(node.data);
inorderTree(node.right, visited);
return visited;
}- 왼쪽 서브 트리 preorder
- 노드 방문
- 오른쪽 서브 트리 preorder
중위 탐색의 순서에 맞게 코드를 구현했습니다.
코드 방식은 앞서 설명한 전위 탐색과 순서만 다르지 굉장히 비슷하기 때문에 자세한 설명은 생략하도록 하겠습니다
후위 탐색 - postOrder()
public List<T> postOrder() {
return this.postorderTree(this.root, new ArrayList<>());
}
private List<T> postoderTree(Node node, List<T> visited) {
if(node == null) return visited;
postorderTree(node.left, visted);
postorderTree(node.right, visited);
visited.add(node.data);
return visited;
}- 왼쪽 서브 트리 preorder
- 오른쪽 서브 트리 preorder
- 노드 방문
중위 탐색의 순서에 맞게 코드를 구현했습니다.
코드 방식은 앞서 설명한 전위 탐색, 중위 탐색과 순서만 다르지 굉장히 비슷하기 때문에 자세한 설명은 생략하도록 하겠습니다.
contains(T val)
인자로 넘겨준 값이 존재하는지를 판단하는 메소드로 이 역시도 재귀 호출을 통해 구현해 보도록 하겠습니다. 그러기 위해서 별도로 containsNode() 메소드를 만들어 줍니다.
@Override
public boolean contains(T val) {
return this.containsNode(this.root, val);
}
private boolean containsNode(Node node, T val) {
if (node == null) return false;
// a.compareTo(b)
// a < b : -1
// a == b : 0
// a > b : 1
//val과 node.data가 같은 경우
if (val.compareTo(node.data) == 0) {
return true;
}
//val이 node.data보다 작은 경우
if (val.compareTo(node.data) < 0) {
return containsNode(node.left, val);
}
//val이 node.data보다 큰 경우
return containsNode(node.right, val);
}containsNode()
루트 노드부터 인자로 받아온 값과 비교하는 연산(compareTo() )을 진행하여 일치하면 true를 리턴하고 그렇지 않은 경우는 다음과 같이 진행합니다.
- 찾고자 하는 값이 현재 노드의 데이터보다 작은 경우 left노드를 타고 들어가 재귀적으로 계속해서 판단을 진행합니다.
- 찾고자 하는 값이 현재 노드의 데이터 보다 큰 경우 right노드를 타고 들어가 재귀적으로 계속해서 판단을 진행합니다.
if문으로 종료조건을 달아줍니다.
- 현재 노드가 null인 경우(leaf 노드에서 다음 노드를 타고 들어간 경우)에 종료됩니다.
Insert(T val), insertNode(Node node, T val)
삽입 같은 경우도 마찬가지로 값 비교를 통해 작다면 left노드에 크다면 right노드에 삽입을 진행해 주어야 합니다.
@Override
public void insert(T val) {
this.root = this.insertNode(this.root, val);
this.size++;
}
private Node insertNode(Node node, T val) {
if (node == null) {
return new Node(val);
}
//leaf노드를 찾는 과정
if (val.compareTo(node.data) < 0) {
node.left = insertNode(node.left, val);
} else if (val.compareTo(node.data) > 0) {
node.right = insertNode(node.right, val);
}
return node;
}- 첫 시작을 root 노드로 한다.
- node가 null인 경우 데이터를 삽입할 수 있는 경우 이기 때문에 val 데이터를 가진 노드를 생성(노드 객체 생성)하여 리턴하면 insert()메소드에서 이를 다시 루트 노드로 대입하여 이 노드를 가지고 insertNode() 메소드가 호출된다.
- 만약 자식 노드가 있다면 값을 비교하여 삽입하고자 하는 값이 루트 값보다 더 작다면 left노드를 계속 타고 들어가 삽입하려는 시도를 재귀적으로 한다.
- 마찬가지로 삽입하고자 하는 값이 루트 값보다 더 크다면 right 노드를 타고들어가 삽입하려는 것을 재귀 호출을 이용하여 구현한다.
delete(T val)
삭제 연산도 재귀 호출로 진행됩니다.
@Override
public void delete(T val) {
this.deleteNode(this.root, val);
}
private Node deleteNode(Node node, T val) {
if (node == null) return null;
//삭제할 노드를 찾으러 들어가는 과정
if (val.compareTo(node.data) < 0) {
node.left = deleteNode(node.left, val);
} else if(val.compareTo(node.data) > 0) {
node.right = deleteNode(node right, val);
} else { // val == node.data : 삭제할 노드를 찾은 경우
this.size--;
if (node.left == null) { //삭제할 노드가 leaf 노드인 경우
return node.right;
} else if (node.right == null) {
return node.left
}
node.data = this.minNode(node.right);//successor 노드 찾기
node.right = deleteNode(node.right, node.data);//successor노드와 삭제 노드를 바꾸고 삭제
}
return node;
}삭제하려고 하는 값의 위치를 찾기 위해서 해당 값과 현재 노드의 데이터 값을 재귀 연산으로 비교하여 위치를 찾아 나갑니다.
- 만약 비교를 했을 때 삭제하고자 하는 값이 루트 값보다 더 작으면 왼쪽 서브 트리 어딘가에 값이 위치해 있을 것입니다.
- 그래서 left 노드를 타고 들어가며 재귀 호출을 해 줍니다.
- 반대 경우에는(삭제하고자 하는 값이 루트 값보다 더 크면),
- right노드를 타고 들어가는 재귀 호출을 합니다.
- 만약 위치를 찾은 경우(val == node.data)에는
- 삭제를 해야 하기 때문에 size를 1만큼 감소 시킨다.
- if) 삭제 하고자 하는 노드가 leaf 노드인 경우 null을 리턴시켜 부모 노드의 자식 노드와 연결 시킨다.
- left노드가 null이면 해당 노드는 이진 트리 특성에 따라 leaf 노드일 것이기 때문에 해당 노드의 right 노드, 즉 null을 반환한다.
- if) 삭제 하고자 하는 노드의 자식 노드가 1개인 경우
- left 노드는 비어있지 않으면서 right 노드가 비어있는 경우는 자식 노드가 1개인 경우이므로
- 해당 노드의 자식 노드를 리턴해 준다.
- if) 삭제 하고자 하는 노드의 자식 노드가 2개인 경우
- 오른쪽 서브 트리의 최솟값을 삭제할 노드의 위치로 가져오는 방법 사용한다.
- 가져온 위치의 노드는 삭제 되어야 하므로 deleteNode메소드를 재귀 호출하여 노드의 오른쪽 서브 트리에 값을 가져온 노드 데이터가 삭제된 서브 트리가 위치 하도록 해 준다.
- 마지막으로 삭제한 node를 반환하여 함수를 종료한다.
size()
@Override
public int size() {
return this.size;
}size함수는 미리 size라는 멤버 변수를 만들어 놓았기 때문에 간단하게 변수를 리턴하면서 마무리 해 줍니다.
관련된 문제
자료구조 시간 복잡도 비교
- 평균 시간 복잡도(Average)
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | O(1) | O(n) | O(n) | O(n) |
| Stack | O(n) | O(n) | O(1) | O(1) |
| Queue | O(n) | O(n) | O(1) | O(1) |
| Singly Linked List | O(n) | O(n) | O(1) | O(1) |
| Doubly Linked List | O(n) | O(n) | O(1) | O(1) |
| Hash Table | O(1) | O(1) | O(1) | O(1) |
| Binary Search Tree | O(log₂n) | O(log₂n) | O(log₂n) | O(log₂n) |
| AVL Tree | O(log₂n) | O(log₂n) | O(log₂n) | O(log₂n) |
| B Tree | O(log₂n) | O(log₂n) | O(log₂n) | O(log₂n) |
- 최악의 경우 시간 복잡도(Worst)
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | O(1) | O(n) | O(n) | O(n) |
| Stack | O(n) | O(n) | O(1) | O(1) |
| Queue | O(n) | O(n) | O(1) | O(1) |
| Singly Linked List | O(n) | O(n) | O(1) | O(1) |
| Doubly Linked List | O(n) | O(n) | O(n) | O(n) |
| Hash Table | O(n) | O(n) | O(n) | O(n) |
| Binary Search Tree | O(log₂n) | O(log₂n) | O(log₂n) | O(log₂n) |
| AVL Tree | O(n) | O(n) | O(n) | O(n) |
| B Tree | O(log₂n) | O(log₂n) | O(log₂n) | O(log₂n) |
'CS 지식 > 자료구조와 알고리즘(Java)' 카테고리의 다른 글
| [자료구조 | Java] Graph(그래프) (0) | 2022.12.28 |
|---|---|
| [자료구조 | Java] Heap & Priority Queue(힙과 우선순위 큐) (2) | 2022.12.28 |
| [Algorithm | Java] Quick Sort(퀵 정렬) (7) | 2022.12.28 |
| [Algorithm | Java] Merge Sort(합병 정렬) (0) | 2022.12.28 |
| [Algorithm | Java] Insert Sort(삽입 정렬) (0) | 2022.12.28 |



