새소식
반응형
이번 시간에는 그래프에 대해 알아보도록 하겠습니다.
그래프(Graph)는 정점(Vertex)의 집합 V와 간선(Edge)의 집합 E로 구성된 비선형 데이터 구조입니다.
먼저 그래프와 트리의 차이점을 살펴보면 다음과 같습니다.
| 구분 | 그래프(Graph) | 트리(Tree) |
| 정의 | 객체 혹은 노드(Node)와 그것을 연결하는 간선(Edge)으로 모인 구조 | 그래프의 한 종류이고 방향성이 없으며 순환하지 않음 |
| 방향성 | 무방향 혹은 유방향으로 가능 | 무방향 그래프 |
| 순환성 | 순환 가능 자기 자신을 연결하는 간선(Self-Loop) 가능 순환(Cyclic), 비순환(Acyclic) 모두 가능 | 순환 불가능 자기 자신 연결 간선(Self-Loop) 불가능 비순환 그래프(Acyclic Graph) |
| 루트 | 루트의 개념이 있거나 없을 수 있음 | 하나의 루트 노드 존재 |
| 모델 | 네트워크 모델 | 계층 모델 |
| 순회 | 넓이 우선 탐색(BFS) 깊이 우선 탐색(DFS) | 전위(Pre) / 중위(In) / 후위(Post) 순회 방식 |
| 간선수 | 그래프에 따라 다르며 없을 수도 있음 | N개의 노드(Node)라면 N-1개 |
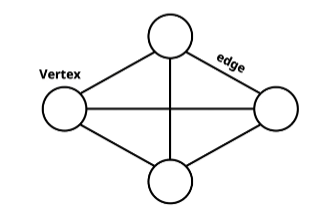
vertex와 edge가 정확히 무엇을 의미할까요? 바로 아래에서 추가적인 용어를 다뤄 보도록 하겠습니다.
그래프(G)는 정점들의 집합 V와 간선들의 집합 E를 사용하여(V, E)로 나타냅니다.
앞에서 배운 트리 또한 그래프의 일종이지만 그래프는 트리 구조 보다 훨씬 더 넓은 범위를 다루고 있다.
그렇다면 그래프는 어디 쓰일까요?

네비게이션 길찾기

우리가 흔히 사용하는 네이게이션 길찾기 기능이 그래프의 탐색을 이용한 기능이라고 할 수 있습니다.
게임 내 캐릭터 이동

자료구조 및 알고리즘 첫 수업(OT) 때 잠깐 설명했단 게임 내 캐릭터 이동도 그래프라고 볼 수 있습니다.
지식 그래프
지식 그래프도 그래프의 일종인데 지식 그래프란 무엇일까요?
쾨니히스베르크의 다리 문제
쾨니히스베르크의 다리 문제도 역시 그래프와 관련된 것입니다.

그래프는 vertex와 edge로 구성되어 있기만 하면은 굉장히 다양한 방법으로 그려질 수 있습니다. 그리고 특징에 따라 여러 그래프를 특정 지을 수 있습니다.
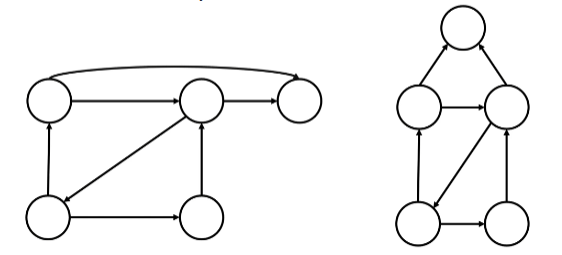

이 방향 그래프에서는 반드시 화살표 방향으로만 노드간의 이동을 할 수 있습니다.

노드 혹은 객체의 연결에 가중치가 부여된 형태의 경우를 의미하며 '네트워크'라고 불리기도 합니다.
edge에 가중치가 부여된 그래프로 가중치는 양수와 음수 모두 될 수 있습니다.
위의 그림에서 A 부터 B까지 갈 수있는 경로는 두 가지입니다.
만약 가중치가 없다면 가장 적은 횟수로 갈 수 있는 첫번째 방법이 당연히 더 효율적일 것입니다.
하지만 가중치 그래프이기 때문에 가중치를 비교해 보면 첫번째 방법은 '7'의 비용이 소모되고 두번째 방법은 총 '3'의 비용이 소모되기 때문에 두번째 방법이 더 효율적인 방법이 될 수 있는 것입니다.
이렇게 가중치 그래프에서 한 vertex에서 다른 vertex까지 가는데 최단 거리를 알아내는 알고리즘으로 다익스트라 알고리즘(Dijkstra Algorithm)과 벨만-포드 알고리즘(Bellman-Ford) 알고리즘을 사용할 수 있는데 다음 시간에 다익스트라 알고리즘에 대해서 배워볼 것입니다.

그래프에서 vertex는 자기 자신으로 이어질 수도 있는데, 한 vertex에서 자기 자신으로 이어지는 edge가 있을 때 이것을 loop(루프)라고 합니다.

한 vertex에서 edge를 타고 가다보면 다시 그 vertex로 돌아오게 되는 그래프를 순환 그래프라고 합니다.
첫 번째 그림은 모든 vertex가 순환 구조를 이루고 있고, 두 번째 그림은 일부분에서 순환 구조가 구성되어 있음을 알 수 있습니다.
반면, 순환이 되지 않는 그래프(사이클이 없는)는 Acyclic Graph(비순환 그래프)라고 하며, 그래서 우리가 앞에서 배운 트리 구조는 순환이 없고 방향만 존재하는 Directed Acyclic Graph가 되겠습니다.
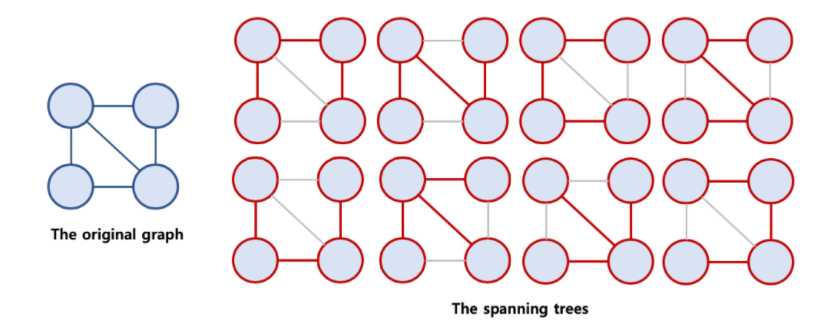
기존 그래프에 모든 노드가 연결되어 있으면, 트리의 속성을 만족하는 그래프로 트리의 속성을 만족하기 때문에 사이클이 존재하면 안됩니다.
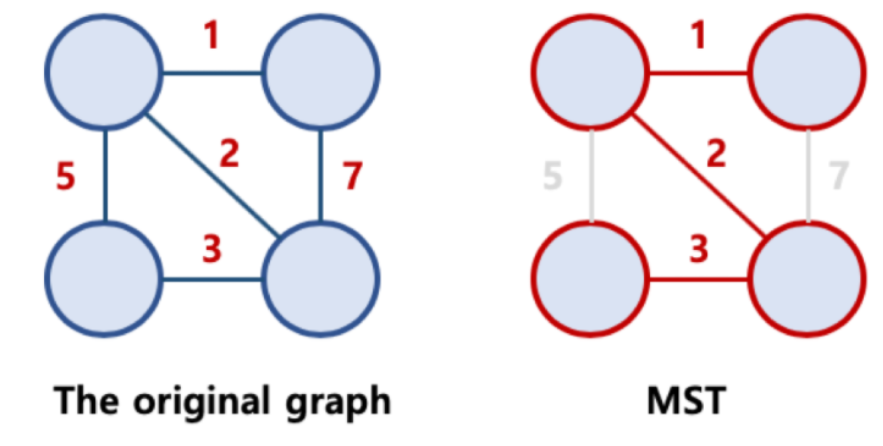
위의 신장트리(Spanning Tree) 중에서 edge의 가중치 합이 최소인 신장트리를 의미합니다.

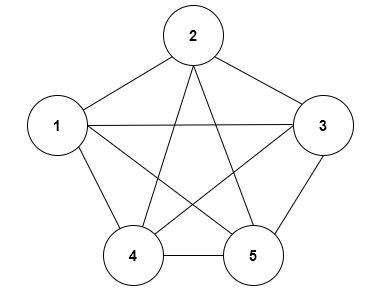
무방향 그래프에서는 단순히 차수(Degree)만을 계산합니다. 즉, 특정 vertex에 연결된 간선의 갯수를 차수라고 보는 것입니다.
아래의 그림에서 2번 정점은 연결된 간선이 3개이기 때문에 차수가 3입니다.
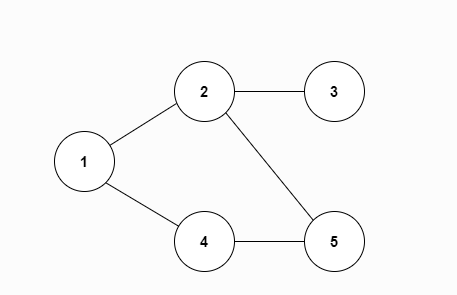
유방향 그래프에서는 내차수(In-Degree)와 외차수(Out-Degree)를 계산합니다. 내차수는 현재 정점 방향으로 들어오는 간선의 갯수이며, 외차수는 현재 정점에서 다른 정점 방향으로 나가는 간선의 갯수입니다.
아래의 그림을 통해 4번 노드는 내차수가 2이고 외차수가 1임을 알 수 있습니다.

그래프는 일반적으로 두 가지 방식으로 표현합니다.

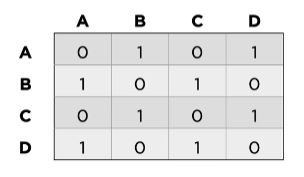
위 그래프에서는 한 vertex가 자기 자신으로 들어가는 edge(즉, Loop)가 존재하는 vertex가 있지 않기 때문에 자기 자신과의 데이터 A-A, B-B, C-C, D-D 모두 0인 것을 볼 수 있다.
방향성 그래프

무방향성 그래프

가중치 그래프
가중치 그래프를 인접행렬로 표현하면 다음과 같고 가중치가 0인 경우와 대비하기 위해서 ∞로 표시하기도 합니다.

인접행렬 장점
인접행렬 단점
그래프 내에 적은 숫자의 간선(Edge)만을 가지는 희소 그래프(Sparse Graph)의 경우 사용합니다.

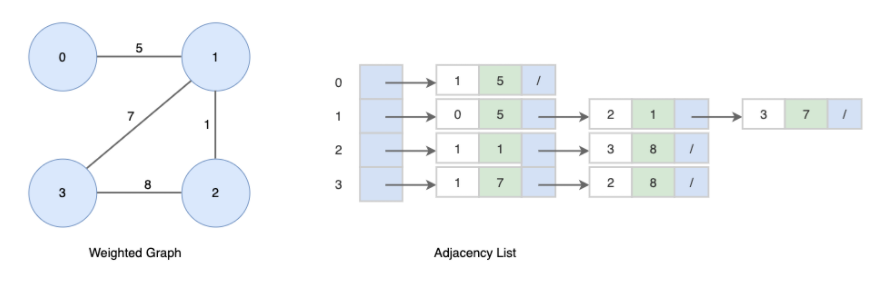
각 vertex별로 리스트가 생성이 되고 그 안의 객체로는 자기 자신과 연결된 vertex의 값이 들어가게 됩니다.
방향성 그래프

무방향성 그래프

가중치 그래프
인접리스트의 장점
인접리스트의 단점
인접 리스트 vs. 인접 행렬
| 방식 | 특징 | 공간 복잡도 | 시간 복잡도 |
| 인접 리스트 | 특정 정점을 접근하기 위해 리스트를 모두 확인해야 한다. | 각 정점의 List에 간선 수 만큼 저장하여 O(E) | 리스트에 각 정점에 연결된 간선의 개수 만큼 저장되므로 O(E) |
| 인접 행렬 | 특정 정점의 연결에 대해 배열로 한 번에 접근 가능하다. | V개의 정점의 수만큼 2차원 배열을 만들기에 O(V2) | 배열이 V x V형태가 되기 때문에 특정 정점의 0이 아닌 경우를 모두 찾아야 하기 때문에 O(V) |
따라서 인접행렬과 인접리스트를 적절히 섞어가면서 사용하는 것이 가장 좋다.
먼저 그래프를 구현하기에 앞서 interface를 살펴봅시다.
package graph;
import ...
public interface IGraph {
void add(int from, int to);
void add(int from, int to, Integer distance); //가중치 노드
Integer getDistance(int from, int to);
Map<Integer, Integer> getIndegrees(); //<노드, 차수의 수>
Set<Integer> getVertexes();
List<Integer> getNodes(int vertext):
}위 코드가 다른 자료구조 구현과 조금 다른 점이 있다면 그래프 interface는 제네릭 타입으로 선언하지 않은 것입니다.
이는 그래프 자체의 구조에 대해 이해를 돕기 위해 integer 정수 타입의 자료만 받아 구현을 할 것이기 때문입니다.
package graph;
import java.util.*;
public class AdjacencyMatrixGraph implements IGraph {
...
}
private Integer[][] matrix;
private Set<Integer> vertexs;
private Map<Integer, Integer> indegrees;그래프의 연결 정보를 저장하기 위한 matrix(2차원 배열)와, 그래프의 vertex들의 정보를 저장하기 위한 vertexes(Set), 차수의 정보를 저장하는 indegrees(Map) 를 선언합니다.
vertexes는 중복을 피해야 하기 때문에 Set 형입니다.
indegrees에 대해 더 설명을 하자면
indegrees.get(3) = 5 는 '노드 3을 가르키는 노드의 갯수가 5개'라는 뜻입니다.
멤버 변수로 선언한 값들에 대한 초기화가 이루어집니다.
public AdjacencyMatrixGraph(int numOfVertex) {
this.vertexes = new HashSet<>();
this.indegrees = new HashMap<>();
this.matrix = new Integer[numOfVertex][];
for (int i = 0; i < numOfvertex; i++) {
this.matrix[i] = new Integer[NumOfVertext];
}
}
add - 인자 3개
@Override
public void add(int from, int to, Integer distance) {
this.vertexes.add(from);
this.vertexes.add(to);
int count = this.indegrees.getOrDefault(to, 0);
indegrees.put(to, count + 1)
matrix[from][to] = distance;
}from과 to를 vertex(노드) 정보에 추가를 합니다. 이는 각각 출발점과 도착점을 의미합니다.
이제 차수 정보를 추가합니다.
indegrees에 key, value가 각각 to, (count + 1) 인 정보를 추가합니다.
마지막으로 matrix의 vertex간의 연결정보를 저장하면서 마무리합니다.
add - 인자 2개
@Override
public void add(int from, int to) {
this.vertexes.add(from);
this.vertexes.add(to);
int count = this.indegrees.getOrDefault(to, 0);
indegrees.put(to, count + 1)
matrix[from][to] = 1;
}나머지 코드는 동일하고 distance를 받지 않는 경우이기 때문에 matrix에는 default값인 1을 넣어줍니다.
만약 양방향 그래프인 경우 from - to 에만 데이터를 넣는 것이 아니라 to - from에도 데이터를 넣어주어야 합니다.
연결이 되지 않는 경우는 null을 넣어줍니다.
@Override
public List<Integer> getNodes(int vertex) {
List<Integer> result = new ArrayList<>();
for (int i = 0, i < this.matrix[vertex].length; i++) {
if (this.matrix[vertex][i] != null) {
result.add(i);
}
}
return result;
}getNode()메소드는 인자로 입력 받은 값이 가리키고 있는 노드들을 가져오는 메소드입니다.
matrix[vertex] [i]는 vertex가 from, i가 to가 되어 vertex가 가리키는 i가 null이 아니라면, 즉 다시말해서 가중치가 얼마가 되는 지는 모르지만 값이 존재하기만 하면 result 리스트에 추가를 해 줍니다.
@Override
public Integer getDistance(int from, int to) {
return this.matrix[from][to];
}
@Override
public Map<Integer, Integer> getIndegrees() {
return this.indegrees;
}
@Override
public Set<Integer> getVertexes() {
return this.vertexes;
}멤버 변수를 가져옴으로써 쉽게 구현 가능합니다.
package graph;
import java.util.*;
public class AdjacencyListGraph implements IGraph {
...
}인접리스트는 노드(연결리스트)를 사용하여 구현해 보도록 하겠습니다.
private class Node {
Integer from;
Integer to;
int weight;
Node(int from, int to) {
this.from = from;
this.to = to;
this.weight = 1;
}
Node(int from ,int to, int weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
}노드 클래스에는 출발 정보와 도착 정보, 가중치 정보가 들어 있어 이를 초기화 시킵니다.
private List<List<Node>> graph;
private Set<Integer> vertexes;
private Map<Integer, Integer> indegrees;인접리스트 방식은 vertex의 수만큼 리스트를 만드는 방식인데 해당 리스트를 graph라는 변수로 선언하였고 나머지 vertexes와 indegrees변수는 인접행렬 구현 때 했던 것과 동일한 기능의 변수입니다.
public AdjacencyListGraph(int numOfVertexe) {
this.vertexes = new HashSet<>();
this.indegrees = new HashMap<>();
this.graph = new ArrayList<>(numOfVertex);
for (int i = 0; i < numOfVertex; i++) {
this.graph.add(new ArrayList<>());
}
}멤버변수로 선언한 변수들에 대한 초기화 과정을 진행합니다.
@Override
public void add(int from, int to, Integer distance) {
vertexes.add(from);
vertexes.add(to);
int count = indegrees.getOrDefault(to, 0);
indegrees.put(to, count + 1);
List<Node> neighbors = this.graph.get(from);
neighbors.add(new Node(from, to, distance))
}인접행렬과 비슷한 방식으로 진행이 됩니다.
단지 인접리스트는 그래프의 형식이 리스트 형식으로 나열되어 있을 뿐입니다.
바깥 리스트의 index의 번호가 노드의 번호가 됩니다.
가령, 아래와 같은 상황에서
0번 노드는 1, 2, 3번 노드를 가리키고 있고 1번 노드는 2번 노드를 가리키고 있고 2번 노드는 0번과 1번 을 가리키고 있으며 3번 노드는 아무 노드도 가리키고있지 않다는 것을 의미합니다.
그래서 from의 노드를 get하여 neighbors에 출발정보와 도착정보, 거리가 들어있는 노드를 저장을 하면 연결 정보가 추가가 됩니다.
@Override
public void add(int from, int to) {
vertexes.add(from);
vertexes.add(to);
int count = indegrees.getOrDefault(to, 0);
indegrees.put(to, count + 1);
List<Node> neighbors = this.graph.get(from);
neighbors.add(new Node(from, to))
}인자가 두 개인 add의 경우 위의 과정과 같고 Node를 추가할 때 distance 변수만 빼 준다.
이 메소드도 인접행렬의 방식과 유사합니다.
@Override
public List<Integer> getNodes(int vertex) {
List<Integer> nodes = new ArrayList<>();
for (Node node: this.graph.get(vertex)) {
nodes.add(node.to);
}
return nodes;
}parameter(인자) vertex가 가리키고 있는 노드들의 정보를 리턴합니다.
@Override
public Integer getDistance(int from, int to) {
for (Node node : this.graph.get(from)) {
if (node.to.equals(to)) {
return node.weight;
}
}
return null;
}from이 가리키고 있는 노드 중에서 to 노드의 weight를 반환합니다.
@Override
public Map<Integer, Integer> getIndegrees() {return this.indegrees;}
@Override
public Set<Integer> getVertexes() {return this.vertexes;}
사실상 그래프 알고리즘 문제에서 가장 중요한 것은 특정 노드에 연결된 모든 노드를 찾는 것이라고 합니다.
따라서 공간도 적게 사용하면서 위 경우 탐색 시간도 빠른 인접 리스트가 훨씬 많이 사용됩니다.
공간 복잡도
인접 행렬: O(V2)
인접 리스트: O(V + E)
시간 복잡도
인접 행렬: O(1)
인접 리스트: O(V)
인접 행렬: O(V)
인접 리스트: O(E)
BFS의 설명은 이곳을 참조
DFS의 설명은 이곳을 참조
Dijkstra 알고리즘의 설명은 이곳을 참조
Topological 정렬의 설명은 이곳을 참조
위 알고리즘은 코딩테스트에서 자주 나오는 단골문제이므로 잘 알아두어야 합니다.
| [Algorithm | Java] Dynamic Programming(다이나믹 프로그래밍) 알고리즘 (4) | 2022.12.28 |
|---|---|
| [Algorithm | Java] 깊이 우선 탐색(DFS) (그래프 탐색) 알고리즘 (4) | 2022.12.28 |
| [자료구조 | Java] Heap & Priority Queue(힙과 우선순위 큐) (2) | 2022.12.28 |
| [자료구조 | Java] Tree, Binary Tree(트리, 이진 트리) (2) | 2022.12.28 |
| [Algorithm | Java] Quick Sort(퀵 정렬) (7) | 2022.12.28 |
소중한 공감 감사합니다