새소식
반응형
이번 시간에는 그래프 탐색 방법 중 너비 우선 탐색(BFS)에 대해서 배워볼 것입니다.
그래프는 탐색하는 동안 동일한 정점으로 다시 이동할 수 있는 싸이클이 있을 수 있습니다. 그래서 동일한 정점이 다시 처리되지 않도록 하려면 처리 후 정점을 방문(visited)했다는 표시를 함으로써 중복 방문을 피하도록 하는 것이 그래프 탐색의 핵심입니다.
Queue를 이용하여 구현
DFS는 그래프의 개념이 반드시 선행되어야 하기 때문에 다음 포스트를 먼저 확인하길 바랍니다.
Tree(트리) 자료구조의 설명은 이곳을 참조
Graph(그래프) 자료구조의 설명은 이곳을 참조
루트 노드(혹은 임의의 다른 노드)에서부터 시작하여 인접한 노드를 먼저 탐색해 나가는 방법입니다.
또한 BFS는 그래프에서 최단 경로를 찾는 정점 기반 알고리즘으로 유명합니다.
특징은 다음과 같습니다.
너비 우선 탐색(BFS)이 깊이 우선 탐색(DFS)보다 더 복잡하다.
BFS의 특징 몇 가지를 더 자세히 살펴 보도록 하겠습니다.
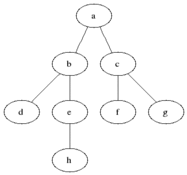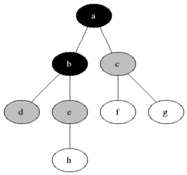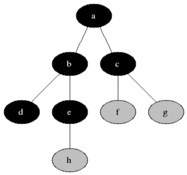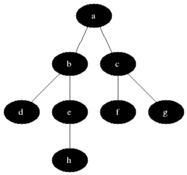
그림을 통해 알아보도록 하겠습니다.

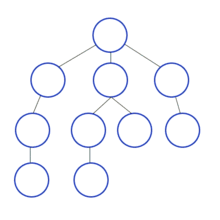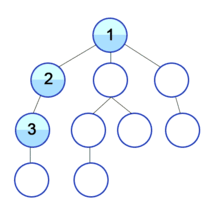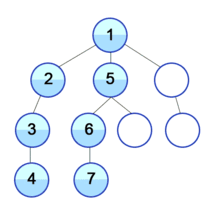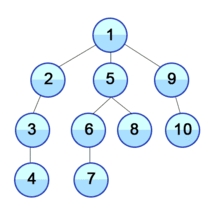
큐에서 데이터가 빠짐(dequeue)과 동시에 해당 데이터는 초록색이 되고 이와 인접한 노드는 노란색이 되면서 방문(enqueue)을 한 상태가 되고 큐에서 순서대로 데이터를 빼면서(초록색으로 만들면서) 인접 노드들이 큐에 삽입되는(노란색이 되는, 큐에 진입) 과정을 반복하는 것이다. (모든 노드가 초록색이 될 때까지, 즉 큐가 빌 때까지 반복한다.)
방문순서 : A-B-C-D-E-F-G-H
package graph;
import java.util.*;
public class GraphAlgorithms {
public static List<Integer> bfs(IGraph iGraph, int from) {
List<Integer> result = new ArrayList<>();
Set<Integer> visited = new HashSet<>();
Queue<Integer> queue = new LinkedList<>();
queue.add(from);
visited.add(from);
while (!queue.isEmpty()) {
Integer next = queue.poll();
result.add(next);
for (Integer n : iGraph.getNodes(next)) {
if(!visited.contatins(n)) {
queue.add(n);
visited.add(n);
}
}
}
return result;
}
}Input parameter: 지난 시간 구현한 그래프(iGraph), 시작 노드(from)
Return: 방문한 노드를 순서대로 저장한 리스트
과정:
너비 우선 탐색(BFS)는 퍼즐 게임 등을 해결할 때 많이 쓰이는 알고리즘이다. 또한 다익스트라 알고리즘에도 사용되며 이에 대한 포스팅은 다음을 참고하세요.
최단 경로 문제는 코딩테스트나 여러 문제 사이트에서 난이도 있는 문제이며 단골 문제이기도 합니다.
특히, 이는 DFS가 아닌 BFS로 풀어야 문제의 결과를 신속하게 낼 수 있습니다. 왜냐하면 BFS를 통해 구현하면 모든 정점방문 결과를 최단 경로로 보장이 가능하지만 DFS는 보장할 수 없기 때문입니다.
하지만 BFS로 최단 경로 문제를 풀때는 다음과 같은 제약 조건이 있습니다.
아래 그림을 보면서 최단 경로 문제를 이해해 보도록 하자.

만약 주황색으로 칠해진 곳에서 출발하여 빨간색으로 칠해진 곳으로 가야하는 것이 문제라고 합시다.
이때 유일한 경로는 파란 화살표와 빨간 화살표가 있을 수 있습니다.(다른 경로에 비해 대표적인 경로)
이 상황에서 BFS로 탐색을 하면 빨간 부분과 파란 부분의 인접 정점을 동시에 차례 대로 탐색을 하면서 시작점이 고정이기 때문에 무조건적으로 모든 인접 정점이 "최소의 경우로만 이동하는 것이 보장"됩니다.
그래서 BFS로 탐색 시, 원하는 위치에 도착했다면 추가적인 탐색을 종료하고 바로 결과가 나오는 것입니다.
그러나 DFS로 탐색을 하면, 상단의 빨간색 부분부터 우선 탐색이 이루어질 수 있는데, 하지만 이 경로는 최소 경로라는 것을 보장 받지 못합니다. 실제로 최소경로가 아니기도 하죠?
이를 보장을 받기 위해서는 이미 방문한 정점에 대해서 미방문(non-visited) 상태로 전환하고 다른 동일 위치에 도달할 수 있는 경우를 모두 체크해야 하는데, 이는 DFS가 아니라 Broute Force(
무차별 대입 방법, 마구 대입
)이게 됩니다.
이러한 이유로 최단 경로 문제를 풀 때는 BFS가 상당히 유리하게 작용합니다.
아래와 같은 방향 그래프에 대해 생각해 봅시다.

BFS를 통해 순환을 탐지하기 위해서는 위상 정렬을 사용할 수 있습니다.
방식은 다음과 같습니다.
무방향 그래프는 상호 연결되어 있기 때문에 방향 그래프에서 cycle을 탐지했던 것처럼 탐지하면 무조건 cycle이 있는 것으로 탐지됩니다.
따라서 다른 방법을 사용 해야 합니다. 방법은 아래와 같습니다.
이해를 위해 다음과 같은 예시를 들어보겠습니다.
인접 정점의 parent가 현재 정점인 경우를 생각해 봅시다.
현재를 A, 인접 정점을 B라고 할 때, A를 방문하고 B에서 다시 A를 방문했다면 무방향 그래프에서 상호 인접 정점끼리는 무조건 재탐색 수행을 하고자 하기 때문에 이것을 제외 시켜야합니다.
하지만 만약, 현재 정점이 parent가 아니라면 A → B → A 의 순이 아니라 A → B → ? → ? → A처럼 중간에 다른 정점들을 추가로 탐색 했다는 의미이며, 이는 당연히 cycle이 있는 것입니다.
이 예시들을 보시고 골똘히 생각해 보시면 아시겠지만 모두 인접한 데이터에 대해 우선적으로 찾는 것이 중요한 것들입니다.
긴 글 읽어주셔서 감사합니다.
소중한 공감 감사합니다