새소식
반응형
이번 시간에는 다익스트라 라는 최단 거리를 알아내는 알고리즘에 대해 배워 보도록 하겠습니다.
그래프에서 최단 경로를 찾아내는 알고리즘은 많이 나와있지만 그 중에서 가장 기본이 되는 알고리즘을 뜻함.
다른 최단 거리 알고리즘은 다익스트라를 기반으로 나온 알고리즘입니다.
다익스트라 알고리즘에 대해 미리 조금 살펴보자면 다음과 같은 것들이 존재합니다.
다익스트라 알고리즘은 우선순위큐를 이용하여 구현하기 때문에 우선순위 큐에 대한 내용을 다음 포스팅에서 확인하기 바랍니다.
Heap 정렬은 우선순위 큐에서 사용하는 정렬이므로 해당 포스팅 이곳을 참조
다익스트라 알고리즘의 특징은 다음과 같습니다.
여러 도시 중 A라는 도시에서 G라는 도시까지 간다고 가정합시다.
경로는 여러가지가 있을 것을 것입니다.
만약 한 경로마다 소모되는 시간은 다음 그림과 같다고 합시다.
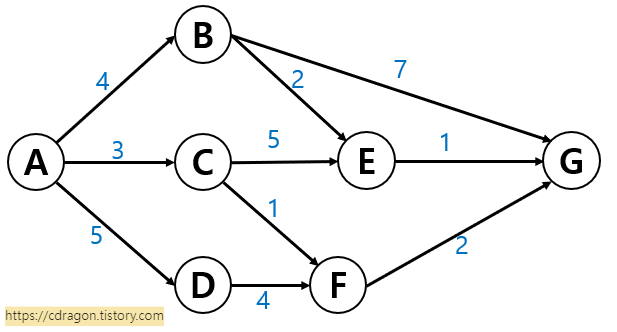
그렇다면 이때 가장 최단 거리의 경로는 어떤 것일까요?
다익스트라 알고리즘은 이 문제를 다음과 같은 명제로 제시합니다.
"부분 경로에서 최단 거리의 집합"
아래 그림에 나오는 숫자들의 색깔은 다음을 의미합니다.
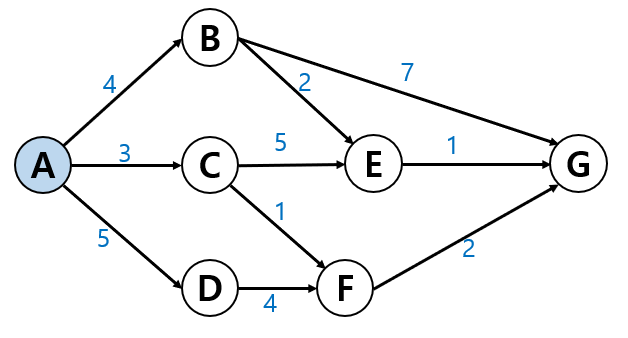
다음에 갈 수 있는 도시는 3개뿐 : B, C, D
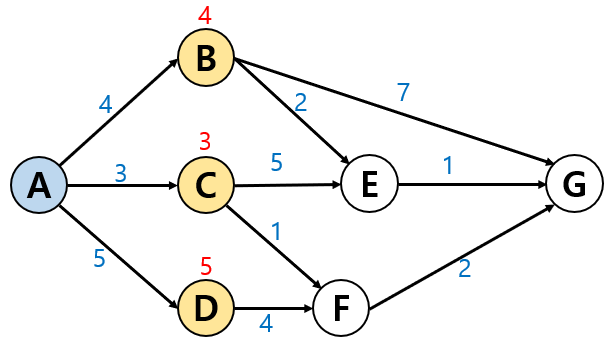
다음 세 도시(B, C, D) 중 다음으로 갈 수 있는 경로 탐색합니다.
1. B도시에서 다음으로 갈 수 있는 경로는
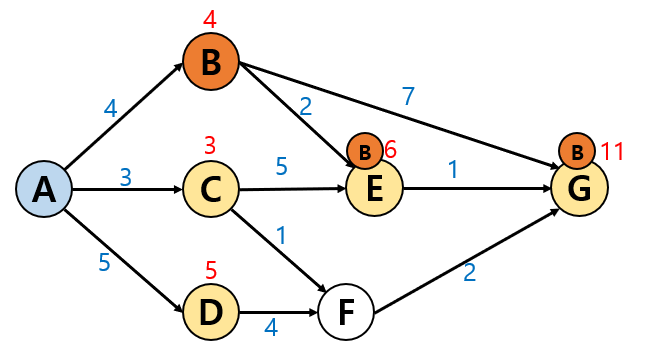
2. C도시에서 다음으로 갈 수 있는 경로는

위에서 B를 거쳐 E를 가는 것이 더 빠르기 때문에 이 경로는 제외합니다.
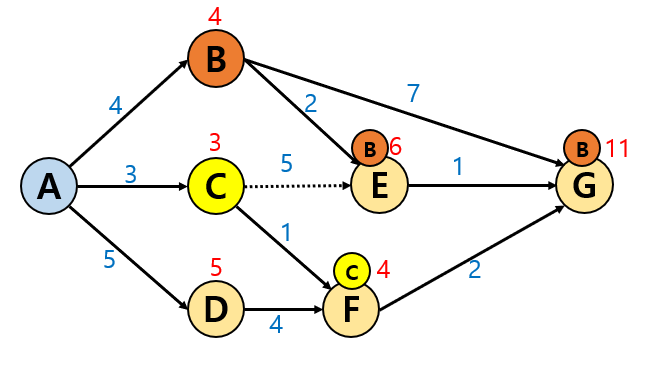
3. D도시에서 다음으로 갈 수 있는 경로는
위에서 C를 거쳐 F에 가는 것이 더 빠르기 때문에 이 경로는 제외합니다.
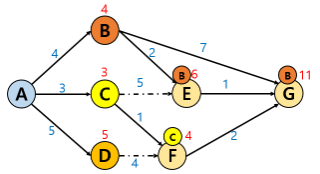
남은 두 도시(E, F)에서 다음으로 갈 수 있는 경로 탐색합니다.
1. E 도시에서 다음으로 갈 수 있는 경로는
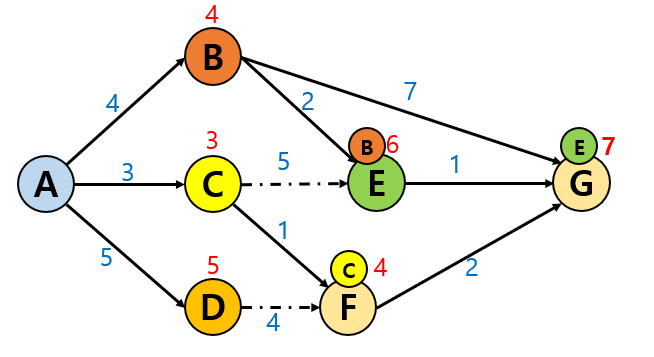
이전에 A에서 B를 거쳐 G에 도착했던 경로(11시간 소모)보다 시간 소모가 더 적기 때문에 해당 경로로 update합니다.
2. F도시에서 다음으로 갈 수 있는 경로는
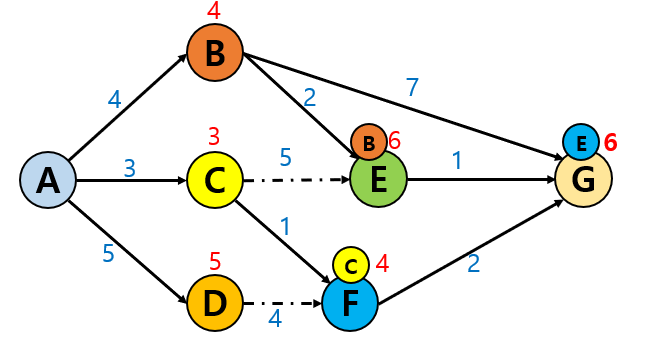
바로전에 A-B-E-G 경로에 비해 1시간이 더 적은 6시간이 소모되므로 이 경로로 다시 update합니다.
이를 통해 다익스트라는 전체 경로의 최단 경로를 찾기 위해서 중간중간 부분 노드에서의 최단 경로를 찾고 새로 탐색한 경로가 내가 이전에 찾았던 경로보다 더 짧은 거리라면 해당 거리로 계속해서 업데이트합니다.
이런 방식을 통해 최종적으로 목적지에 도착했을 때의 최단 거리를 찾아내는 방식인 것입니다.
1. 시작 노드에서 출발하여
2. 연결되어 있는 노드들을 탐색하며
3. 최단 거리를 업데이트
→ 특정 노드까지의 최단 거리 경로를 저장하는 방식이 중요함 → 배열 사용
그렇다면 배열을 어떻게 활용하여 이를 저장하는 지 봅시다.
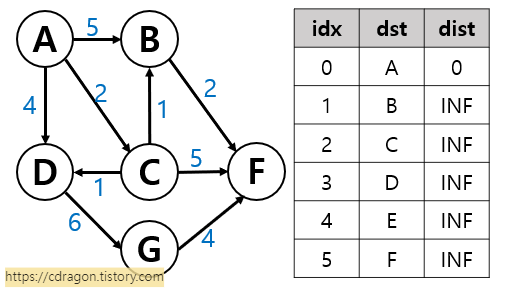
위 그림에서 A노드에서 F노드까지 가는 경로를 탐색한다고 가정하겠습니다.
배열에 값이 업데이트 된다는 것은 우선순위 큐에 삽입된다는 뜻이기도 합니다.
1. 먼저 노드 수만큼 배열을 생성합니다.
2. 배열의 값을 출발 노드에는 0, 나머지는 infinite(무한, ∞)값으로 넣습니다.
3. 출발 노드 큐에 삽입합니다
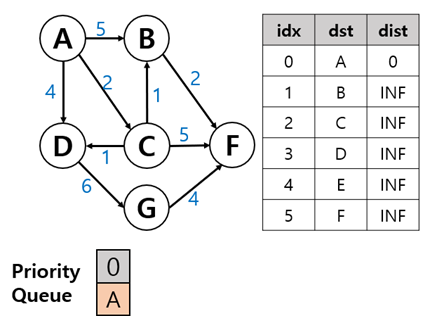
4. A 노드에서 갈 수 있는 경우 따져보기
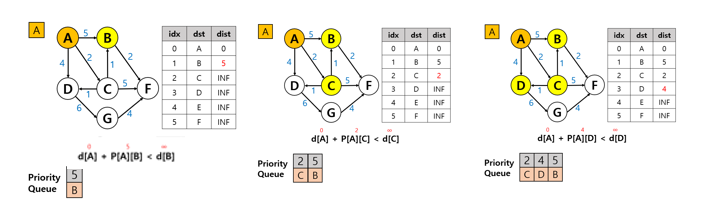
1. B노드(1번 그림): 5시간
2. C노드(2번 그림): 2시간
3. D노드(3번 그림): 4시간
5. 그 다음 큐에서 데이터를 빼서 탐색 계속 진행(C 노드)
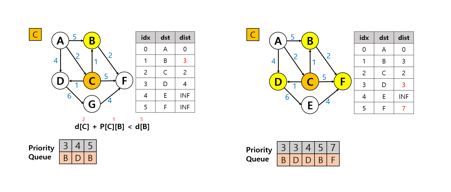
1. B노드(1번 그림): 3
2. D노드/F노드 : 3/7
6. 다음 우선순위 큐에 있는 노드에 대하여 탐색을 진행(B 노드)
B노드에서 갈 수 있는 경우는 F노드 뿐이다.
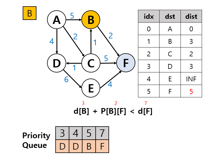
이전에 기록된 F의 값은 7로, B노드를 거치는 경우가 업데이트 되었기 때문에 이를 적용하여 계산한 결과가 5이기 때문에 다시 F값이 업데이트 된다.
7. 우선순위 큐에서 D노드 꺼내 탐색 진행
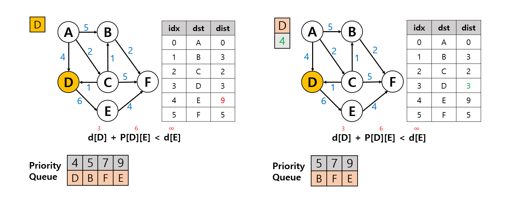
E노드(1번 그림): 9
8. 그 다음 큐도 D 노드이기 때문에 7번 과정을 진행 하지만 이 값은 업데이트 되지 않는다.
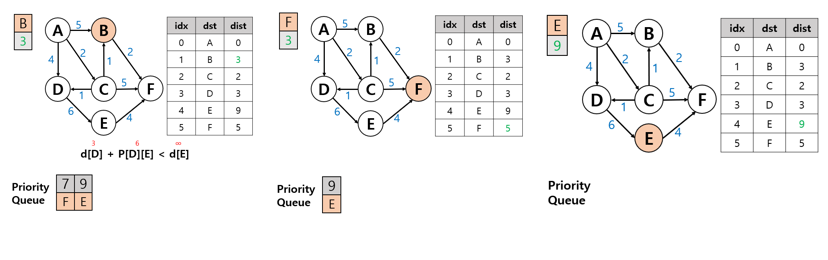
마찬 가지로 유선순위 큐에 있는 큐는 순서대로 탐색하며 위 과정을 반복하여 큐를 비워줍니다.

최종적으로 위 표와 같이 노드 별 거리가 배열의 데이터로 초기화 된 값으로 저장이 된 모습입니다.
위 표가 의미하는 바는 굉장히 중요한데요, A의 값이 0이라는 것부터 A노드는 기준이 되어 다른 index의 값이 A 노드와의 최단 거리를 의미하게 됩니다.
따라서 A노드부터의 최단거리를 구하고 싶으면 해당 노드의 index만 알면 됩니다!
우선순위 큐를 사용하여 최단 거리를 매번 계산하지 않고 가져올 수 있기 때문에 이를 활용하여 구현해 볼 것입니다.
public static int dijkstraShortestPath(Igraph graph, int src, int dst) {
// 1.
int size = 0;
for (int n : graph.getVertexes()) {
if (size < n) {
size = n + 1;
}
}
// 2.
//distance 배열을 노드 갯수 만큼 초기화
int[] dist = new int[size];
for (int i = 0; i < dist.length; i++) {
dist[i] = Integer.MAX_VALUE; //distance 값을 INF로 초기화
}
dist[src] = 0; // 시작 노드의 distance = 0
// 3.
//<vertex, distance>
// distance를 기준으로 하는 민힙(minHeap)
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> {
return a[1] - b[1];
});
pq.add(new int[] {src, 0});
// 4.
while (!pq.isEmpty()) {
int[] top = pq.poll();
int veretex = top[0];
int distance = top[1];
if (dis[vertex] < distance) {
continue;
}
for (int node : graph.getNodes(vertex)) {
if (dist[node] > dist[vertex] + graph.getDistance(vertex, node)) {
dist[node] = dist[vertex] + graph.getDistance(vertex, node);
pq.add(new int[] {node, dist[node]});
}
}
// 5.
return dist[dst];
}parameter:
return:
과정
1. 가장 먼저 노드가 몇 개인지 센다.
2. distance 배열은 노드 갯수만큼 있기 때문에 1번에서 구한 값으로 distance 배열을 초기화한다.
3. 우선순위 큐를 생성해 준다.
4. 큐가 빌 때까지 다음 과정을 반복한다.
5. 큐가 비어서 4번 반복문이 종료가 되면 최단 거리 배열의 목적지에 해당하는 index의 데이터 값을 리턴하면서 마무리한다.
| [Algorithm | Java] Greedy Algorithm(그리디 알고리즘) (0) | 2022.12.28 |
|---|---|
| [Algorithm | Java] 너비 우선 탐색(BFS)(그래프 탐색) 알고리즘 (0) | 2022.12.28 |
| [Algorithm | Java] Dynamic Programming(다이나믹 프로그래밍) 알고리즘 (4) | 2022.12.28 |
| [Algorithm | Java] 깊이 우선 탐색(DFS) (그래프 탐색) 알고리즘 (4) | 2022.12.28 |
| [자료구조 | Java] Graph(그래프) (0) | 2022.12.28 |
소중한 공감 감사합니다