새소식
반응형
NestJS에 대해서 모든걸 샅샅이 알아보도록 합시다.
이번 포스팅은 그 대장정의 첫 발걸음으로 NestJS에 대한 간략한 소개와 백엔드 관련 용어의 의미를 정리해보는 시간이 될 것 입니다.
아무리 NestJS에서 제공하는 모듈이나 테크닉들을 사용한다고 해도 그것을 왜 사용하는지를 모르면 결국은 말짱 도루묵입니다.

우선 NestJS에 대해 깊이 공부하기 위해서는 그와 관련되어 상당히 많은 것들을 알아야 합니다. 우선 당연하게도 NestJS는 백엔드 프레임워크이기 때문에 백엔드와 관련된 지식들은 물론이거니와 NestJS가 채택한 수많은 소프트웨어적 아키텍처와 이를 뒷받침 하는 기술들도 마찬가지이죠.
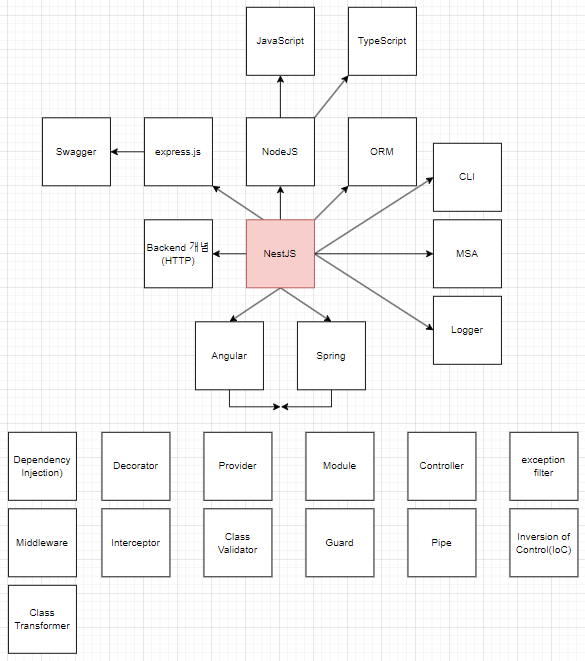
아래 관계도에서 화살표는 크게 의미 없지만 NestJS에서 뻗어나올 수 있는 것들을 정리해보니 잠깐 생각한 것만 해도 저 정도 분량이 나왔습니다. 놀랍게도 앞으로의 포스팅들에서 아래 요소들에 해당하는 내용과 추가적인 개념들까지 전부 다뤄보려고 합니다.
우선 NestJS의 정의는 다음과 같습니다.
Node.js 런타임 위에서 동작하는 TypeScript용 오픈 소스 백엔드 웹 프레임워크
위 문장에서 벌써 "Node.js", "런타임", "TypeScript"와 같이 우리가 정리해야 할 용어가 쏟아지기 시작했습니다.
저는 이 포스팅에서 이렇게 어떤 개념을 먼저 정리하고 그 개념 안에 들어있는 용어를 나중에 다시 또 정리하는 식으로 포스팅을 진행해 보도록 하겠습니다.
Nest는 효율적이고 확장가능한 NodeJS 서버 측 애플리케이션(즉, 백엔드)을 구축하기 위한 프레임워크입니다.
이 프레임워크는 프로그레시브 자바스크립트(웹과 네이티브 앱의 이점을 모두 수용하고 표준 패턴을 사용해 개발된 것)를 사용하며, 타입스크립트로 구축되었을 때 완벽한 지원을 하지만, 개발자가 순수 자바스크립트 만으로도 프로그래밍이 가능하도록 합니다.
또한 Nest는 자신들만의 기술로 OOP(객체지향 프로그래밍), FP(함수형 프로그래밍), FRP(기능적 반응형 프로그래밍)의 요소를 결합하였습니다.
내부적으로는 Express(기본, default)와 같은 강력한 HTTP 서버 프레임워크를 사용하며, 선택적으로 Fastify도 사용하도록 구성할 수 있습니다.
express는 뒤에서 다시 설명해 드리도록 하겠습니다.
또한 Nest는 일반적인 NodeJS 기반의 프레임워크(Express/Fastify)들 보다도 더 높은 수준의 추상화(abstraction)를 제공할 뿐만 아니라 개발자가 이러한 기존 프레임워크의 API를 직접 사용할 수 있게까지도 해줍니다.


최근 몇 년 동안 NodeJS 덕분에 JavaScript는 프론트엔드 및 백엔드 애플리케이션 모두에게 있어 '최애 언어'가 되었습니다. 개발자의 생산성을 향상시켜 주었고, 빠르게 테스트가 가능하게 해주었으며, 확장 가능한 프론트엔드 애플리케이션을 만들 수 있는 SPA 프레임워크 및 라이브러리들(Angular, React, Vue)로 멋진 프로젝트를 만들 수 있게 되었기 때문이죠.
하지만 이렇게 수 년에 걸쳐 Node를 위한 훌륭한 라이브러리, 헬퍼, 도구가 나왔음에도 백엔드 쪽에서는 결국 아키텍처라는 굉장히 중요한 문제를 효과적으로 해결해 준 프레임워크는 없었습니다.(그 이유는 뒤의 express 설명에서 나옵니다.)
정리하면, Nest는 개발자와 팀이 고도로 테스트 가능하고 쉽게 확장 가능하며, 각 코드가 느슨하게 결합되어 유지보수가 용이한 애플리케이션을 아주 손 쉽게 만들 수 있게 도와주는 기본 애플리케이션 아키텍처를 제공하고자 나오게 된 것입니다.
Nest의 아키텍처는 특히 Angular에서 많은 영감을 받아 실제로 구조적으로 유사성이 많이 보입니다.
또한 코드를 구성하는 방식이 객체지향 프로그래밍을 따르기 때문에, 아키텍처나 디자인 패턴 자체도 모던 백엔드에서 사용하는 것을 그대로 가져가, 백엔드 프레임워크 중 인기있는 Spring boot와도 코드를 놓고 봤을 때 상당히 유사함을 발견할 수 있을만큼 Java Spring을 사용하시던 분들도 곧잘 사용하실 수 있게 된다고 합니다.
그렇다면 앞서 자주 언급된 NodeJS는 도대체 무엇이길래, 웹이라는 분야에서 그렇게 많이 사용하게 된 것일까요?

이와 관련되어 Java와 Node를 비교한 글을 포스팅한 적이 있는데, 흥미가 있으신 분들은 아래 링크를 참조해주세요!
[BackEnd] 자바/스프링(Java/Spring)와 Node.js | 대기업은 자바, 스타트업은 Node.js(노드)? (Spring과 Nodejs 중
이번에 포스팅 할 주제는 자바/스프링과 Node.js의 차이점에 대한 내용입니다. 각각이 나오게 된 이유와 어떠한 이유로 사용되고 있는지에 대해 역사부터 시작하여 차근차근 적었으니 굉장히 알
cdragon.tistory.com
NodeJS가 흥한 이유를 간략히 설명하자면 다음과 같습니다.

우리가 "웹"이라고 하면, 보통 브라우저라는 도구를 이용해서 '인터넷'에 들어갔을 때 사용자들끼리 정보를 공유할 수 있는 공간을 일컬어 말하는데요. 여기서 중요한 것은 웹 애플리케이션이라는 것을 구축했을 때 이를 구동시키는 브라우저가 있어야만 우리가 이 웹을 사용할 수 있다는 점입니다. 즉, 애플리케이션을 실행시키는 주체가 있어야 한다는 의미입니다.
그런데 기억해 보시면 불과 몇 년전만 해도 브라우저 시장은 "Internet Explorer"가 압도하고 있었는데 이 브라우저는 그 당시 브라우저면 응당 있어야 하는 기능이었던 자바스크립트를 돌리는 엔진이 없었고 이기적으로 자신들만의 JScript라는 스크립팅 언어만을 돌릴 수 있는 엔진을 탑재하여 수많은 개발자들도 그러한 이유에서 어쩔 수 없이 JScript로 코드를 짜야 했습니다.
그런데 어느 날 개발자들을 구해주기 위해 초신성처럼 구글이 크롬을 들고 나온 것입니다.

구글은 당시 크롬이라는 엄청난 브라우저를 출시했는데, 크롬에는 "v8"이라는 자바스크립트 엔진이 달려있었고 이는 성능이 가히 괴물이라고 할 수 있을 정도로 빨랐습니다.
이렇게 좋은 성능을 가진 자바스크립트 엔진을 보자니 개발자들은 도무지 참을 수가 없었고 내 컴퓨터에서 자바스크립트 코드를 이 v8 엔진으로 돌려보고 싶은 욕구가 생기게 되었습니다. 그렇게 V8 자바스크립트 엔진으로 구동되며, 웹 브라우저 바깥에서도 자바스크립트 코드를 좋은 성능으로 실행시키기 위한 목적으로 탄생한 NodeJS는 크롬 정식 버전이 출시된지 5개월만에 자바스크립트 런타입 환경 오픈소스로서 출격하게 됩니다.
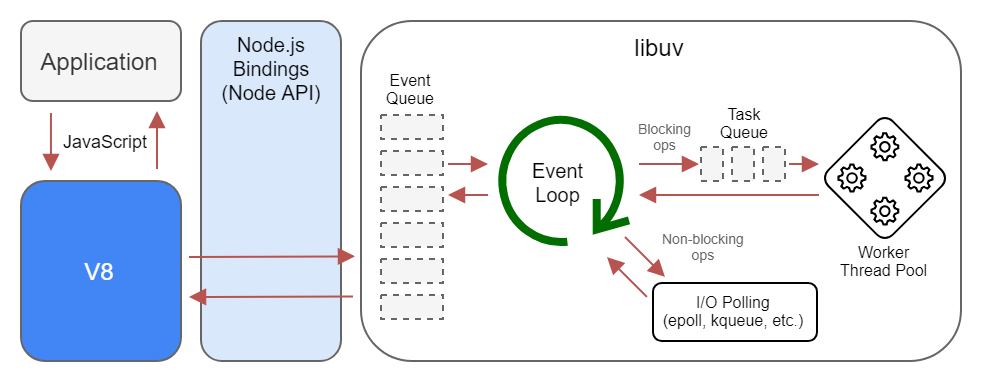
그러나 Node가 단순히 자바스크립트만 빠르게 돌릴 수 있는 플랫폼이었다면 이렇게까지 인기가 있었을지는 모르겠습니다. Node가 지금까지 성장할 수 있었던 배경에는 바로 비동기 이벤트 처리를 할 수 있도록 하는 libuv 라이브러리와 결합했다는 사실이 존재합니다.
비동기 이벤트 처리는 I/O가 빈번하게 일어나는 서비스의 경우 굉장히 우수한 성능을 보일 수 있는데, 웹의 트렌드가 I/O의 중요성이 커지는 서비스가 증가하는 추세를 보였고, 그 시기가 마침 잘 맞아떨어져 NodeJS가 굉장한 인기를 얻을 수 있었던 것입니다.
그 외에도 자바스크립트를 사용하던 프론트엔드 개발자들이 너도 나도 "자바스크립트로 백엔드도 짤 수 있대!"라는 소문을 퍼뜨리며 더 인기가 많아진 이유도 있었습니다.

우리가 흔히 Node를 백엔드 프레임워크라고 잘못 말하지만 정확히 말하면 express가 백엔드 프레임워크이고 Node는 백엔드 애플리케이션을 구축할 수 있는 자바스크립트 런타임일 뿐입니다.
이렇게 좋은 Node를 백엔드 개발자들도 도무지 가만히 놔둘 수가 없었습니다. 그래서 Node의 핵심 모듈만을 이용해서 서버-사이드 애플리케이션을 작성하기 시작했지만 동일하고 비슷한 코드를 계속해서 작성해야 하는 문제가 있었고(Http 요청 본문 파싱, 쿠키 파싱, 세션 관리, URL 경로와 http 요청 메서드를 기반으로 한 복잡한 if 조건을 통해 라우팅 구성, 데이터 타입을 토대로 한 적절한 응답 헤더 결정 등...) 이에 피로함을 느낀 개발자들은 Node 백엔드 생태계를 위한 프레임워크를 만들고자 결심을 합니다.
그래서 node를 기반으로 백엔드를 구축하기 위한 프레임워크가 일사천리로 만들어지기 시작했고, 그렇게 해서 만들어진 것이 바로 Express.js 인 것입니다.
Express는 Node의 핵심 모듈인 Http와 Connect 컴포넌트를 기반으로 하는 웹 프레임워크입니다. 이러한 컴포넌트를 미들웨어(Middleware)라고 하며, 설정보다는 일종의 관례와 같이 이 프레임워크의 철학을 지탱해주는 추춧돌에 해당하는 것들이라고 보시면 됩니다.
위에서 다룬 문제들과 더불어 Node는 여러 문제를 해결함과 동시에, 웹 앱의 MVC패턴의 아키텍처를 제공합니다. 그렇게 백엔드만 갖춘 REST API는 물론이거니와 온갖 기능을 다 제공하는 고도로 확장가능한 이른바 풀스택 실시간 웹 앱에 이르게 되었습니다.
express에 대해서 설명한 김에 express 작동 방식에 대해서 여기서 간략하게 설명드리도록 하겠습니다.
보통 express.js는 메인 파일이라고 하는 진입점이 있습니다.(app.js, index.js, main.js, ...) 메인 파일에서는 다음과 같은 단계를 밟게 됩니다.
1. Controller, Utility, Helper, Model과 같은 자체적인 모듈을 비롯한 서드파티 의존 모듈들을 include 한다.
2. 템플릿 엔진과 해당 템플릿 엔진의 파일 확장자와 같은 Express.js 앱 설정을 구성한다.
3. 오류 핸들러(error handler), 정적 파일 폴더, 쿠키 및 기타 파서와 같은 미들웨어들을 정의한다.
4. 라우팅을 정의한다.
5. MongoDB, Redis 또는 MySQL과 같은 데이터베이스에 연결한다.
6. 앱을 구동한다.
그러면 express 앱이 실행되게 되고 express는 우리가 흔히 아는 server-client model 구조에 맞게 요청을 대기하게 됩니다(listen).
그리고 앱으로 들어오는 각 요청(requests)은 미리 정의된 미들웨어와 라우팅에 따라 맨 위에서 시작해 맨 아래까지 순차적으로 처리되게 되죠.
이러한 측면은 실행 흐름을 제어하는 데 중요하게 작용을 합니다.
예를 들어, 각 요청을 여러 함수가 처리하게 할 수도 있는 것인데, 그러한 함수 중 일부는 중간에 끼어서 사용되어야 할 수도 있기에 이름이 미들웨어(Middleware)인 것입니다.
이후 과정은 다음과 같이 진행됩니다.
1. 쿠키 정보를 파싱(하나의 정보에서 필요한 정보들로 나누는 것)하고, 파싱이 완료되면 다음 단계로 이동한다.
2. URL로부터 매개변수를 파싱하고, 파싱이 완료되면 다음 단계로 이동한다.
3. 사용자가 인증되면(쿠키/세션) 매개변수의 값을 토대로 데이터베이스에서 정보를 가져와 일치하는 것이 있으면 다음 단계로 이동한다.
4. 데이터를 표시하고 응답을 마친다.
express는 굉장히 가볍게 테스트용 서버를 띄울 수도 있고 확장가능성이 높기 때문에 내가 원하는 기능들을 넣고 구조도 자유롭게 짤 수 있다는 장점을 갖고 있습니다.
그치만 때로는 자유가 그렇게 좋은 것만은 아닙니다. 구조의 자유도는 개발자마다의 중구난방 디렉터리 구조와 자기들만의 개발 방식을 만들어내기 때문에 이는 좋은 생태계를 유지할 수 없게 만드는 이유가 됩니다.
아무렇게나 폴더 구조를 구성해도 괜찮다보니 이런 방식 저런 방식이 다 나오게 되고 일종의 "관례"라는 것이 만들어지지 않아 이를 처음 접하는 사람들 입장에서는 다소 혼란을 겪을 수 있는 것입니다.
또한 자바와 같이 type check에 엄격한 언어와 대비되어 자바스크립트는 페이지에 약간의 동적인 기능을 넣고자 굉장히 급조하여 만들어진 언어였기 때문에 코드를 짜면서도 이게 무슨 변순지... 이렇게 짜도 에러가 발생하지 않을지...에 대한 정보를 사전에 알기가 굉장히 어렵죠.
이는 코드를 작성할 때 에러를 발견하는 것이 아니라 서버를 구동시키고 직접 요청을 날려봐야 디버깅이 된다는 의미이기에 개발 효율이 굉장히 떨어지는 일입니다.
또한 위에서 말했듯 express에서 실행하는 미들웨어 순서가 개발자에게 온전히 맡겨져 있다곤 하지만, 사실 그 순서는 당연히 이른바 국룰로써 정해진 바가 있기 마련입니다.
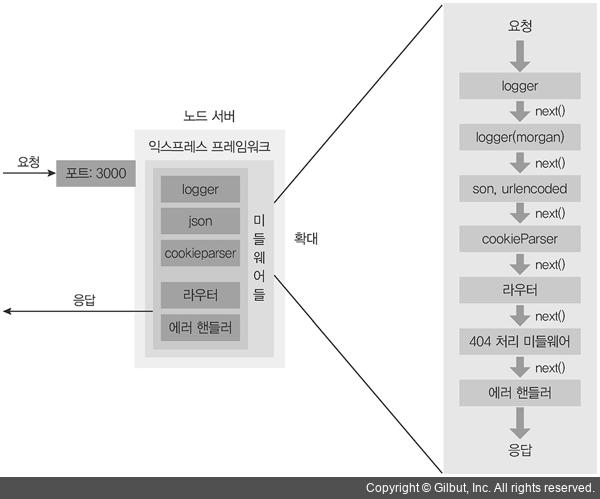
일단 로그인, 인증을 담당하는 미들웨어를 거쳐야 하고, logger와 같이 Request와 Response 각 극단을 다루는 미들웨어를 거쳐야 하며, 각 값들에 대한 검증(validation), 즉 잘못 들어온 값들이 body, query, parameter에 있지는 않은지 체크해주는 미들웨어들을 순서에 맞게 거쳐가야 합니다.
이런 라이프 사이클(생명주기)에 관한 부분을 직접 다루어야 한다는 것은 굉장히 숙련된 개발자가 자기 입맛대로 커스텀하기에는 좋겠지만 신입 개발자가 새로운 프로젝트를 개발하거나 아무리 시니어 개발자라도 프로젝트를 할 때마다 매번 이러한 행위를 반복하는 것은 굉장히 피곤한 일이라고 할 수 있습니다.
express에서는 이러한 과정을 뭉뚱그려 "Middleware"라고 하지만 각자가 다 제 역할을 하고 이에 대한 표현들은 분명히 존재합니다.
예시)
NestJS에서 요청이 왔을 때 위와 같은 미들웨어들이 처리되는 일반적인 순서는
Request -> Guards -> Interceptors -> Pipes -> Controller -> Service -> Interceptors -> filter -> Response
와 같습니다.
그 외에도 express에서는 async/await을 잘 지원하지 않는다거나, 의존성 주입이나 단일 인스턴스에 대한 보장 관련 문제를 nest에서는 깔끔하게 해결해 줍니다.
한 마디로 굉장히 번거로운 과정들을 NestJS에서는 일일히 세팅하는 수고없이 그냥 코드 한 줄만 탁 쓰면 바로 해결되도록 해주는, 말 그대로 강력한 프레임워크를 구축한 것입니다.
자 그럼 이제 위에서 나왔던 용어 중에서 반드시 알아야하고 알아두면 좋을 용어들을 정리해 보면서 NestJS는 어떤 개념을 갖고 있는지 설명해 드리도록 하겠습니다.
우선 웹이 어떻게 동작하는지와 관련하여 이론을 알아야 할 필요가 있습니다.


개발 세상은 월드 와이드 웹(WWW)이 나오고 나서부터 격동적으로 바뀌기 시작했는데요. 이러한 인터넷 기반 정보 공유 공간은 사람들의 정보 공유 욕구를 채우기 굉장히 좋은 공간이었고 이곳에서는 HTML(hypertext markup language)이라는 웹사이트의 모습을 기술하기 위한 hypter text 마크업 언어가 사용되기 시작했습니다.
이처럼 처음에는 정적인 정보(텍스트)만을 담은 정보를 보냈지만 기술이 점차 발전함에 따라 동적이고 능동적인 프로그램을 서버와 클라이언트(브라우저) 사이에 주고 받아야 했기에 사람들은 이와 관련된 표준을 점차 규정하기 시작했습니다.
앞서 설명드린 HTML은 'hypertext'라는 비선형적(non-linear)인 텍스트 정보를 담은 문서를 말하는데요. 이러한 hypertext를 빠르게 교환하기 위해서 나온 프로토콜의 일종으로서 HTTP가 등장하게 됩니다. (HTTP: HyperText Transfer Protocol)
여기서 '프로토콜'이란 일종의 규약 및 규칙을 정한 것이라고 보시면 됩니다. 즉, 서버와 클라이언트 사이에서 메세지를 어떻게 교환할지를 정해 놓은 것이죠.
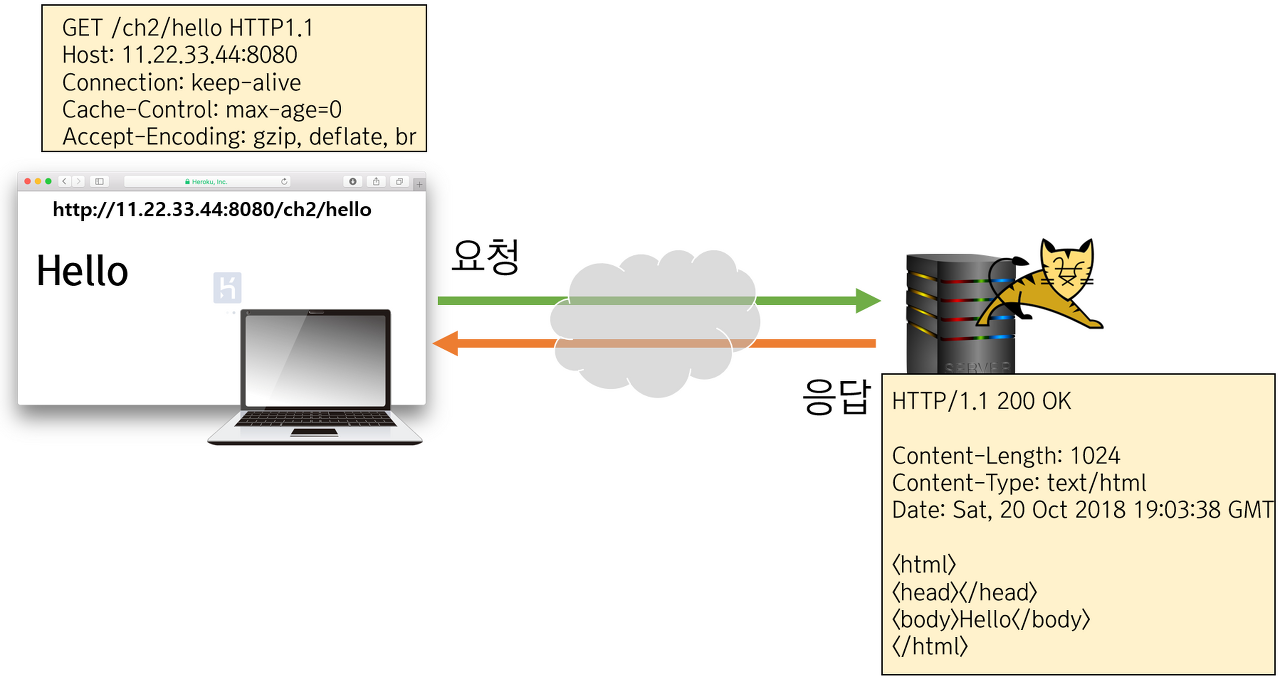
서버-클라이언트 모델은 클라이언트가 요청하는 방식대로 서버가 정보를 응답하는 방식을 말합니다. 그렇기에 우리가 백엔드 서버를 만든다고 할 때는 이러한 규칙에 맞춰서 응답을 내리도록 설정해 주는 과정을 거쳐야 합니다.
그러면 사용자는 어떤 방식으로 서버에 요청을 하게 될까요? 우리가 일반적으로 웹페이지를 접속하여 인터넷을 돌아다닐 때는 위와 같은 '프로토콜'이니 'http'니 하는 것들을 신경쓰지 않고 그냥 이용합니다.
이는 모두 브라우저에서 그러한 행동들을 대신 해주기로 각종 알고리즘이 입력되었기 때문인데요. 그래서 클라이언트는 어떤 주소를 브라우저 주소창에 입력하여 접속하기만 하면 브라우저가 대신 요청을 하여 페이지를 넘나들 수 있게되는 것이고, 심지어는 버튼을 눌러도 요청이 날라가기 때문에 이러한 방식들로 페이지를 변환시키는 것이 가능한 것입니다.
이 때 사용자가 주소창에 입력하는 주소, 버튼을 눌렀을 때 연결되도록 설정된 주소를 URL(Uniform Resource Locator)이라고 합니다.
URL의 기본 구조는 다음과 같습니다.

scheme://<user>:<password>@<host>:<port>/<url-path>
특히, 일반적으로 우리가 많이 사용하는 HTTP URL의 scheme은 다음과 같이 표현됩니다.
http://<host>:<port>/<path>?<searchpart>
위 scheme에서 host에 들어가는 부분은 클라이언트가 접속하고자 하는 서버의 컴퓨터 IP를 의미하게 됩니다. 그래서 보통 '123.123.123.123'과 같은 IPv4 방식의 숫자로 된 표현이 사용되지만 우리가 해당 서버에 접속하기 위해 그러한 IP들을 모두 외울 수는 없으므로 이를 식별하기 쉬운 문자열로 대체하여 1대1로 매핑시키게 되는데 이러한 매핑 데이터 정보를 모두 모아둔 것을 DNS(Domain Name System)라고 합니다.
한 컴퓨터에서는 여러 프로세스를 돌릴 수 있고, 서버라는 개념도 결국 어떠한 컴퓨터를 의미하는 것이기 때문에 하나의 서버에서 여러 프로세스가 돌아가는 것은 당연합니다. 웹 애플리케이션 서버(WAS)는 말 그대로 웹 애플리케이션을 제공하는 서버이기 때문에 제공하는 프로세스가 정해져있습니다.
이 때 각 프로세스를 식별하는 논리 단위를 Port라고 합니다.
포트 번호는 IP주소와 함께 쓰이며 해당하는 프로토콜에 의해 선택적으로 사용되는데, WWW의 URL은 기본적으로 80번 포트를 사용하므로 웬만한 브라우저에서는 포트를 따로 명시하지 않으면 자동적으로 주소 뒤에 80포트를 붙여서 요청을 보내도록 설계가 되어있습니다.
그 이후에 서버는 기다리던 HTTP 요청을 받게되고, 요청된 리소스를 컴퓨터 내에서 찾게됩니다. 그 후 요청에 맞게 HTTP 응답 형식에 맞춰 컨텐츠를 잘 준비하여 요청이 왔던 클라이언트, 즉 브라우저로 이를 다시 돌려 보내주게 됩니다.
이 응답을 위한 컨텐츠는 RESTful하게 준비되는데 REST API에서 REST란 'Representational State Transfer'의 약자로 "리소스의 이름으로 구분하여 해당 리소스의 상태를 주고 받는다"는 것을 의미합니다.
RESTful API라고 하면, 서버와 클라이언트 사이에 통신이 가능하도록 HTTP 프로토콜을 사용하는 웹 서비스를 구축하는데 사용되는 구조적인 스타일을 말합니다. 리소스에 대한 동작을 수행하기 위해 표준 HTTP 메소드(GET, POST, PUT, DELETE)를 사용합니다.
REST API는 보통 여러 엔드포인트(요청하는 곳, 주소)를 가지며 각각의 엔드포인트는 매 요청에 동일한 응답을 반환하게 됩니다.
쉽게 말해, HTTP URI를 통해 가져와야 할 리소스가 명시되는데, 이를 HTTP에서 정한 Method(POST, GET, PUT, DELETE)내에서 해당 리소스에 대해 CRUD(Create-Read-Update-Delete) 연산을 적용하는 것이라고 보시면 됩니다.
REST API
→ example.com/class
→ example.com/class/{반 index}
→ example.com/class/{반 index}/students
→ example.com/class/{반 index}/students/{학생 index}
GraphQL
→ example.com/graphql
(하나의 엔드포인트에 다른 쿼리를 사용해 요청)위처럼 REST API의 경우 반에 속해있는 데이터를 가져오는데에 응답마다 다양한 엔드포인트를 가지게 됩니다.
(하지만 GraphQL은 하나의 엔드포인트 (Root Endpoint)에 다른 쿼리로 요청함으로써 다른 응답을 받을 수 있습니다.)
클라이언트의 요청에 따라 서버가 응답 컨텐츠를 보낼 때는 서버가 어떤 종류의 반응을 보였는지도 같이 알려주어야 하는데요. 이는 Status Code로 명시하게 됩니다.
Status Code 예시)

보통 클라이언트가 잘못된 접속을 하게되면 404와 같은 에러 코드를 반환하는 페이지를 보셨을 것입니다.
또한 서버에 사용자가 과도하게 몰려 서버가 터지게 되는 경우 5xx와 같은 에러 코드를 반환하는 페이지를 보신적도 있으실 겁니다.

이후에 브라우저는 서버로부터 받은 데이터를 해석하고 화면에 표시하게 되는데요. 이때 HTML, CSS, JavaScript 등을 통해 렌더링이 되는 것입니다.
웹 프론트엔드 영역도 엄청난 발전을 거듭해왔는데요. 더 효율적으로 화면을 렌더링하기 위해 "CSR"이라는 방식과 함께 도입된 React, Vue, Angular에 대해서 수차례 들어보셨을 겁니다. 그에 더해 최근에는 CSR의 단점을 보완할 수 있는 "SSR" 방식이 다시 떠오르게 되고 CSR과 SSR 방식 모두를 아우를 수 있는 웹 프론트엔드 프레임워크(Next.js)도 나왔습니다.
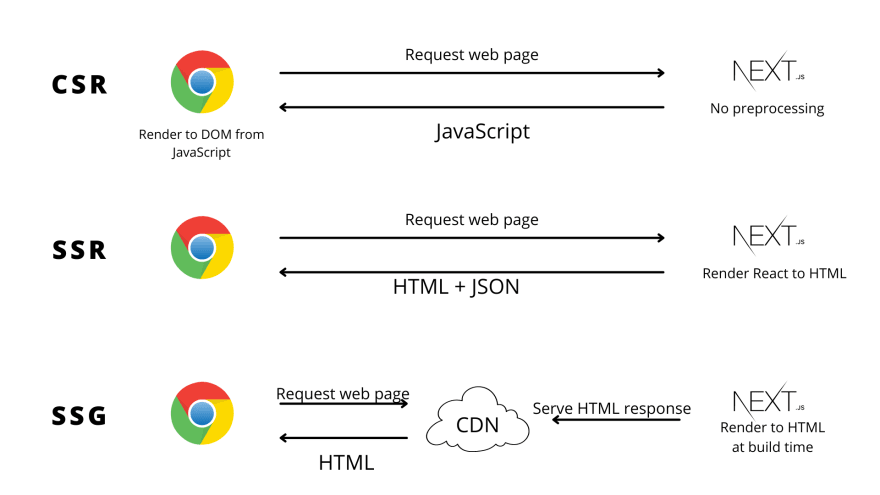
SSR(Server-Side Rendering)과 CSR(Client-Side Rendering)은 웹 렌더링 방식을 말합니다.
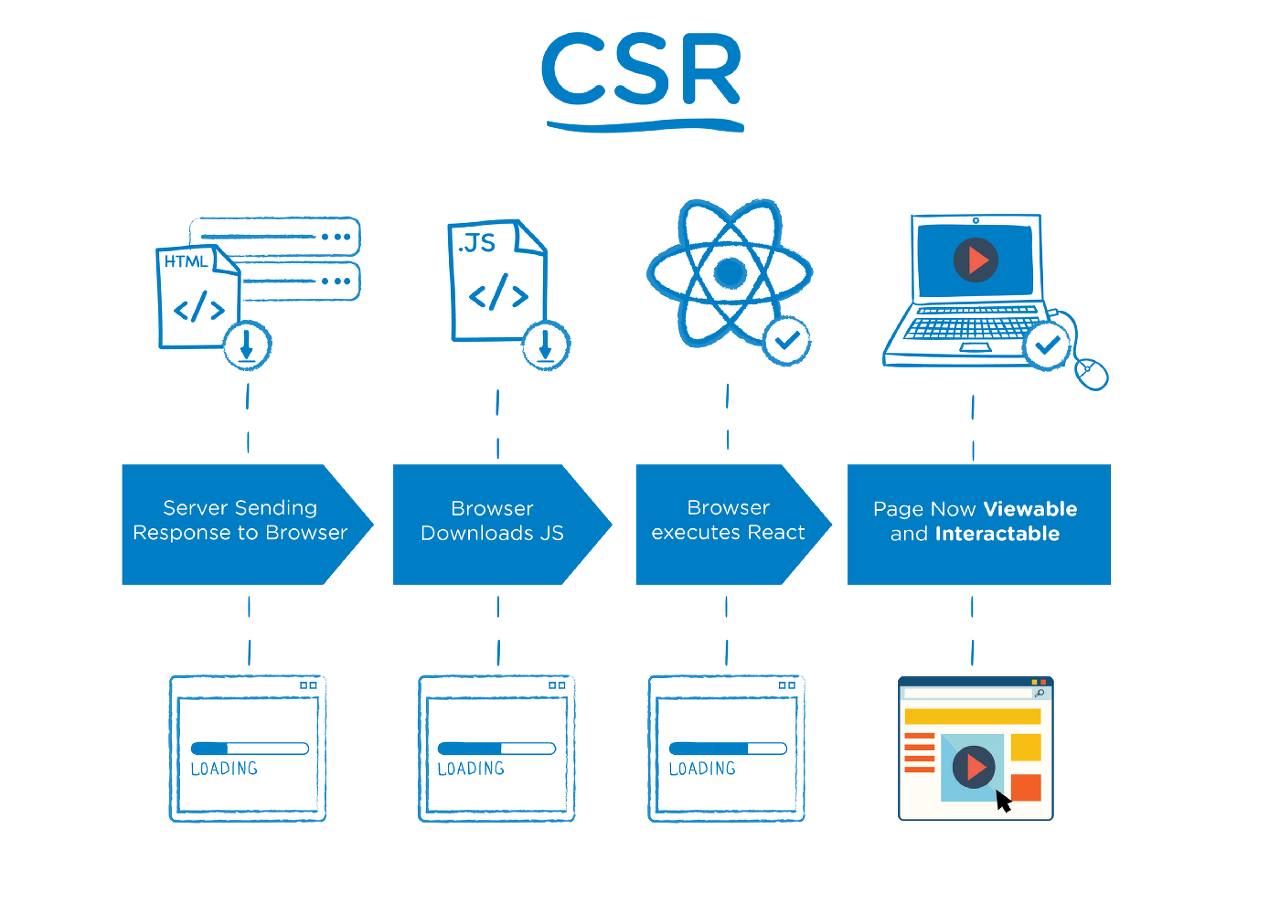
CSR 방식에서는 사용자가 메인 페이지(http://www.naver.com/ 와 같은)에 접속하면, 초기 로드 시에 빈 HTML과 모든 로직이 하나에 전부 담겨 있는 JavaScript 파일 하나를 서버로부터 다운받습니다.
그 후 브라우저는 JavaScript를 이용하여 빈 HTML에 메인 페이지에서 보여줄 컴포넌트들을 직접 렌더링하게 됩니다.
이런 웹 애플리케이션을 부르는 명칭이 바로 SPA(Single Page Application)인데요. 이는 사용자가 여러 페이지를 이동하더라도 최초에 서버에서 전송받은 단 하나의 HTML을 이용해, 컴포넌트만 교체해서 렌더링하기 때문에 단 하나의 페이지, 즉 단일 페이지로 볼 수 있다는 의미에서 나온 이름입니다.
그렇기에 첫 로드 시 모든 로직이 담겨있는 JavaScript를 다운로드 하다보니 첫 접속 시에 로딩 속도가 다소 느리다는 단점과 비어 있는 HTML 파일을 하나만 가져오기 때문에 각 페이지에 대한 정보를 담기 힘들어 좋지 않은 SEO(검색 엔진 최적화)와 같은 단점들이 존재합니다.
그럼 SSR은 그 반대이겠죠?
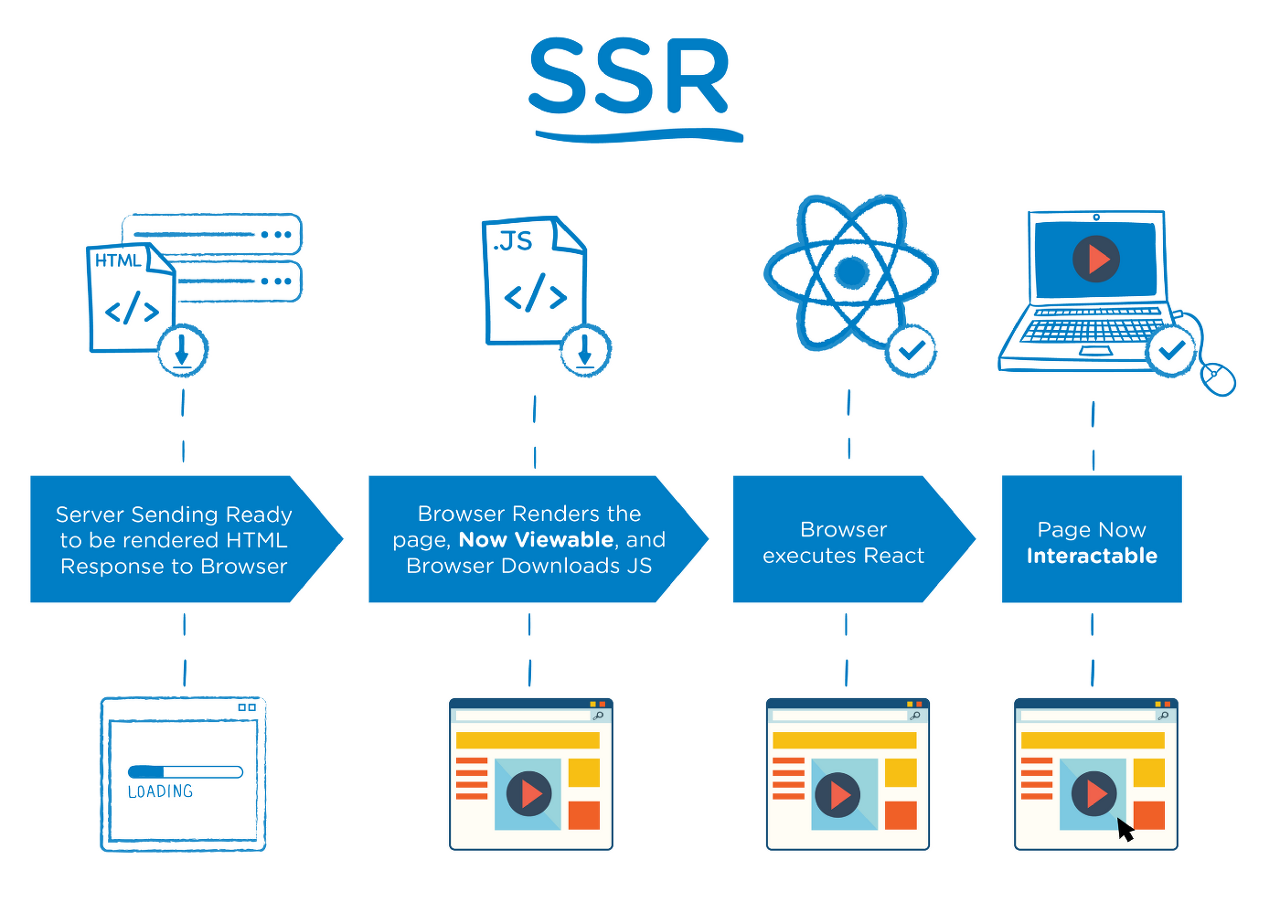
SSR 방식에서는 각 페이지 URL마다 보여줄 내용이 미리 결정되어 있는데 날라온 요청을 보고 그것에 맞게 서버가 렌더링을 하여 완성된 HTML 파일을 로드해 줍니다.
즉, 사용자가 웹 페이지에 접속을 하면 브라우저는 해당 URL에 해당하는 서버에 요청을 전달하고, 서버는 이 URL을 분석하여 어떤 페이지를 렌더링할지 결정합니다. 서버는 렌더링 엔진을 이용해 페이지를 render(그린다)하고, 완성된 HTML을 브라우저에 응답합니다. 여기서는 HTML 파일뿐만 아니라 이후 필요에 따라 JS파일 등의 추가 리소스를 다운받는 과정도 당연히 포함될 수 있습니다.
물론 이 방식은 요청한 페이지에 대한 HTML만을 다운로드 하기 때문에 CSR보다는 초기 접속 속도가 빠르지만 화면의 컴포넌트를 클릭했을 때 새로운 HTML 파일을 서버로부터 받아야 하기 때문에 화면 깜빡임 현상이 존재하게 됩니다.
자 다시 백엔드로 돌아오자면, 위에서 계속 살펴봤듯이 웹 앱에서는 주로 "데이터"를 많이 다루게 됩니다.
데이터를 전달 받기도 하고 그걸 또 처리해서, 또 다시 전달해 주기도 하죠. 그렇다면 어떤 데이터를 어디서 가져와 전달해 주는 것일까요?
클라이언트는 서버에 요청을 날리면서 때로는 본인의 정보를 포함시켜 요청을 보내기도 합니다. 이러한 정보들은 나중에 사용자가 다시 활용해야 할 수도 있으므로 서버는 이를 잃어버리지 않고 잘 저장해두어야 할 책임이 있는데요.
사용자의 데이터를 저장하는 공간으로서 데이터베이스라는 개념이 사용됩니다. 데이터베이스의 정의는 여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합이라고 합니다. 작성된 목록으로써 여러 데이터 베이스 관리 시스템(DBMS)의 통합된 정보들을 저장하고 운영할 수 있는 공용데이터들의 묶음인 것이죠.
데이터베이스의 데이터는 당연하게도 사라지지 않도록 하는 비휘발성 저장공간(디스크)에 저장되게 됩니다.
그러면 이렇게 데이터베이스에 있는 데이터를 그냥 막 전달해도 될까요? 여러 이유들로 인해 그냥 데이터베이스의 데이터를 그 자체로 보내는 행위는 웬만해서 금지됩니다.
그렇다면 프로그램 내에서 데이터들을 어떤 형태로 다루고 어떤 방식으로 전달해야 되는 걸까요? 그 방식에는 여러가지가 존재합니다.
Entity는 실제 DB 테이블과 직접 매핑(mapping)되는 객체입니다.
데이터베이스 과목에서의 Entity
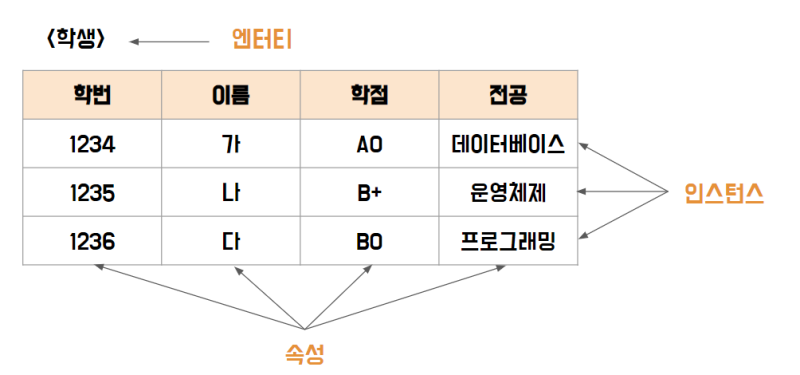
예를 들어, 데이터베이스에 Student라는 Entity(개체)가 있다면 해당 Entity는 이름, 나이 등 여러 컬럼(필드)들을 가질 수 있습니다. 각 학생들은 모든 속성이 같은 경우가 당연히도 발생할 수 있기 때문에 (동명이인 등) 식별 가능한 identifier(ex. id)로 구분되도록 해야 합니다.
NestJS에서 사용되는 Entity
NestJS에서 역시 이를 사용할 때는 실제 데이터베이스의 테이블과 직접적으로 연결되어 있는 클래스로써 활용됩니다.
NestJS와 TypeORM을 사용하는 프로젝트에서는 일반적으로 Entity 클래스를 먼저 정의하여 데이터베이스 테이블을 생성합니다. 이러한 접근 방식을 "Code-First" 접근 방식이라고 불리며 DDL(Data Definition language)을 통해 데이터베이스의 스키마를 생성하는 "Schema-First" 방식과는 차이가 있습니다.
따라서 Entity 클래스는 데이터베이스와 매핑되어 있는 핵심 클래스로 데이터베이스의 영속성 목적으로 사용되기 때문에, 요청이나 응답 값을 전달하는 클래스로 사용하는 것에는 맞지 않습니다.
Entity 클래스를 기준으로 테이블이 생성되고 스키마가 변경되기 때문에 Entity는 데이터 교환용으로 절대 사용하면 안되는데, 만약 많은 서비스 클래스나 비지니스 로직들이 Entity 클래스를 기준으로 동작할 때, 혹은 View가 변경될 때마다 Entity 클래스에 같이 변경을 가하게 되면 데이터베이스 구성 자체에 영향이 가기때문에 이와 연관된 다른 여러 클래스에도 의존하여 영향을 줄 수 있게 되기 때문입니다.
그럼 Entity를 그렇게 소중히 다뤄야 하면 데이터는 누가 도대체 어떻게 보내죠...?
DTO는 그러한 Entity의 성질을 보완하기 위해 Entity의 변경을 최소화하기 위한 목적으로 탄생했습니다.
그렇기에 요청이나 응답 값을 전달하는 클래스로는 다른 클래스에 영향을 끼치지 않고 자유롭게 변경이 가능한 DTO를 사용하게 되는 것이죠.
DTO는 말 그대로 "데이터.전달.객체", 즉 프로세스 간에 데이터를 전달할 때 사용하는 객체입니다. 더 정확히는 아래에서 배우게 될 '계층 간'에 데이터를 교환하기 위해서 객체에 데이터를 담아 전달할 수 있도록 고안된 바구니라고 생각하시면 됩니다.
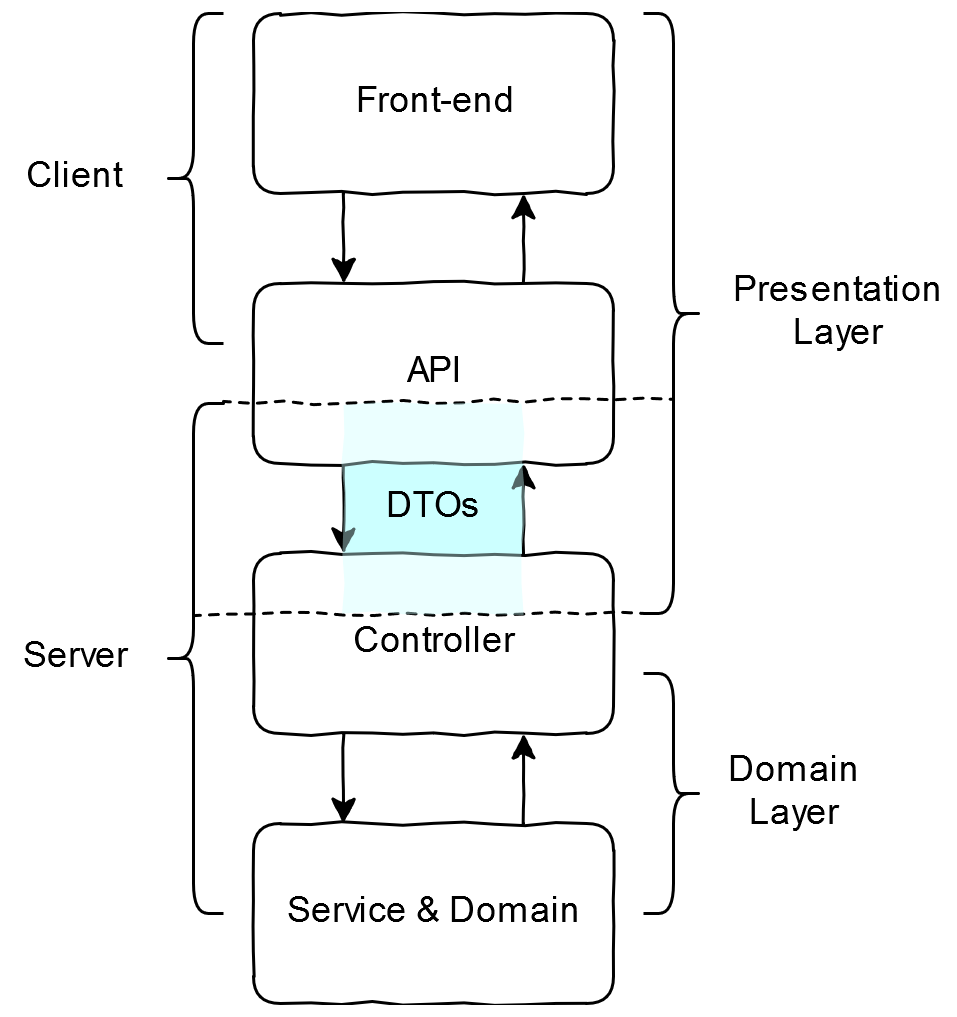
소프트웨어는 보통 여러 계층으로 나뉘어져 있으며, 각 계층에서는 독립적인 역할과 책임을 가지게 됩니다. 이때 계층 간 데이터를 전달해야 하는 경우가 생기게 되는데 굳이 객체로 변환해야 하는 이유는 여러 데이터 필드를 하나의 객체에 캡슐화할 수 있기 때문입니다.

앞서 설명드렸듯이 데이터베이스에 있는 데이터는 굉장히 중요한 자원이고 그러한 데이터를 의미하는 Entity를 보낼 수는 없으니, 그러한 데이터 중에서 필요한 데이터만 보낼 수 있도록 바구니에 담아서 보내는 것인데 이 바구니가 바로 DTO인 것입니다.
우리가 객체지향에서 말하는 캡슐화(Encapsulation)를 이용하면 데이터를 전달할 때 일관성을 유지하고, 오류 가능성을 줄여주며, 필요한 데이터만을 포함시켜 민감한 데이터를 숨기거나 특정 데이터만을 전송하는 것이 가능해지기 때문에 이를 도와주는 DTO를 사용하는 것이죠.
즉, 주된 목적은 네트워크를 통해 데이터를 전송할 때 다양한 계층(ex. 데이터베이스, 서버, 클라이언트) 간 필요한 데이터만을 담아 효율적으로 전송하기 위함입니다. 시스템 내부에서 사용되는 복잡한 객체를 외부에 전달하기 적합한 형태로 변환하는 것이죠.
주로 API 응답으로써 클라이언트에 데이터를 전송할 때 사용되며 시스템의 내부 구조를 숨기면서도(도메인 Model 캡슐화) 필요한 데이터만을 전달하고자 할 때 사용합니다.
NestJS에서의 DTO
일반적으로 DTO는 순수하게 변수를 저장하고, 그 변수에 대한 getter, setter만을 가져야 그 역할을 제대로 할 수 있다고 합니다. 이는 사실 이것은 변수는 숨기고 그 변수를 조작하는 메소드만 접근가능하도록 하는 캡슐화의 근본적인 개념을 사용한 것인데요. 하지만 NestJS에서의 DTO는 주로 데이터 전송을 위한 객체로 클래스 내부에 주로 변수(데이터 필드)만을 포함하고 관련 메서드(행동)은 포함하지 않습니다.
그렇기에 DTO는 어떠한 비지니스 로직(길이를 제한하는 기능을 넣는다던가, 이메일 형식을 확인한다던가 하는...)을 가져서는 안되며, 단순한 검색, 저장, 직렬화, 역직렬화 로직만을 가져야 한다고 되어있습니다.(by 위키피디아)
추가적으로 NestJS에서는 DTO를 통해서 다음 세 가지의 기능을 할 수 있습니다.
한 문장 정리: DTO(Data Transfer Object)는 서로 다른 소프트웨어 계층 간에 데이터를 보다 효율적이고 안전하게 전달하기 위해 사용하는, 구조화된 데이터의 '컨테이너(바구니)'입니다.
DAO는 데이터베이스와의 상호작용을 담당하는 객체로써 데이터의 영속성을 관리하며 데이터베이스의 CRUD 작업을 수행합니다.
말이 어려워보이는데 단어 의미 그대로 해석하자면 '데이터 접근 객체'인데요. 우리가 데이터를 결국 가져오긴 가져와야 하는데 그 데이터를 어떤 방식으로 접근해서 가져올지에 대한 의문이 있을 것입니다.
그 의문에 대한 정답이 바로 DAO입니다.
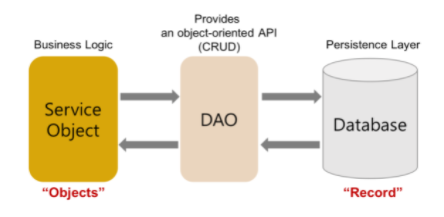
애플리케이션의 호출들을 persistence layer(아래에서 배우게 됩니다.)에 매핑시킴으로써 DAO는 데이터베이스의 상세한 사항을 노출하지 않고(이 또한 캡슐화...) 특정 데이터의 일부 동작을 제공하게 됩니다. 우리는 이 '동작'이라는 단어에 집중해야 합니다. 왜 비지니스 로직(a.k.a Service)에 데이터를 가져오는 동작을 넣지 않고 따로 분리를 시킨 것일까요?
이러한 분리는 SOLID 원칙의 S인 "단일 책임 원칙"을 지원하기 때문이며, 도메인 특화 객체(DSL, ex. SQL) 및 자료형 관점에서 애플리케이션이 필요로 하는 데이터 접근 방식이 무엇이고 이러한 요구사항 속에서 특정 DBMS의 요구를 만족시킬 수 있는지와 분리시킬 수 있기 때문이라는 이유가 존재합니다.
정리하면, DAO는 데이터베이스의 상세한 사항을 노출시키지 않고(캡슐화), 특정 데이터의 일부 동작을 제공해주는 추상 인터페이스 객체이며, 실제 DB에 접근하는 프로세스인 Repository에서 사용하는 ORM을 동작시킬 때 주로 사용되는 개체라고 생각하면 됩니다.
즉, 데이터베이스에 접근하여 데이터를 조회, 추가, 수정, 삭제하는 등의 작업을 수행하는데 이를 통해 비지니스 로직과 데이터베이스 간의 상호작용을 분리하는 역할을 합니다. 일반적으로 애플리케이션의 나머지 부분이 데이터베이스의 구체적인 구현 세부사항을 몰라도 된다는 장점이 있으며, 데이터베이스 관련 코드를 한 곳에 모아 유지보수를 용이하게 해줍니다.
이러한 이유로 우리가 ORM을 사용하지 않는다면 DAO에는 데이터베이스에서 데이터를 꺼내오기 위해 특화되어 마련된 SQL 쿼리문(SELECT * FROM USER)을 보실 수 있게 됩니다.
우리가 흔히 DTO와 용어가 비슷하여 많이 헷갈리는데 DTO는 데이터의 구조를 정의하는 반면, DAO는 데이터의 접근 및 조작을 담당한다는 점을 잊지맙시다.
(이름에 정답이 있으니 헷갈리지 맙시다!)
한 문장 정리: DAO(Data Access Object)는 데이터베이스에 접근(access)하여 데이터를 조회하거나 조작하는 로직을 캡슐화하는 객체입니다.
좀 더 쉬운 이해를 위해 Nest에서 사용되는 Entity, DTO, DAO를 살펴보겠습니다. 실제 구현과 관련된 내용은 이후의 포스팅에서 나오기 때문에 여기서는 가볍게 아 이렇게 사용되는구나 정도만 보시면 되겠습니다.
Entity
// item.entity.ts
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm';
@Entity()
export class Item {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@Column()
description: string;
@Column()
quantity: number;
}
DTO
// create-item.dto.ts
export class CreateItemDto {
readonly name: string;
readonly description: string;
readonly quantity: number;
}
DAO
// items.service.ts
import { Injectable } from '@nestjs/common';
import { InjectRepository } from '@nestjs/typeorm';
import { Repository } from 'typeorm';
import { Item } from './item.entity';
import { CreateItemDto } from './create-item.dto';
@Injectable()
export class ItemsService {
constructor(
@InjectRepository(Item)
private itemsRepository: Repository<Item>,
) {}
async create(createItemDto: CreateItemDto): Promise<Item> {
const item = this.itemsRepository.create(createItemDto);
return this.itemsRepository.save(item);
}
async findAll(): Promise<Item[]> {
return this.itemsRepository.find();
}
// 기타 메서드...
}
DAO 코드를 보시면 아시겠지만 Nest에서는 보통 Service 계층에서 ORM을 이용해 데이터베이스로부터 데이터를 가져오는 DAO의 역할을 대신하게 됩니다.
단순하게 페이지를 불러오고 DB 정보를 한 번에 불러오는 간단한 프로젝트의 경우 Service와 DAO를 구분하지 않지만 구분하여 사용할 때, Service는 사용자가 요청한 작업을 처리하는 과정을 하나의 작업으로 묶은 것이고, DAO는 service에서 사용하는 데이터를 가져오는 역할로, 좀 더 데이터베이스에 집중하여 CRUD(Create-Read-Update-Delete) 작업을 하나씩 분할해 놓은 것으로 사용됩니다.
사용자가 한 번의 요청으로 단순히 페이지 이동이 필요하다면 서비스 내에서는 select와 같은 단순히 하나의 DAO만 작동할 것이기 때문에 Service와 DAO가 나뉠 필요가 없어보이지만, 사용자가 글을 작성한다거나 수정하는 것과 동시에 페이지가 이동한다면 update, select 등이 작동하기 때문에 여러 DAO를 수반하게 되고 이를 Service 안에 조립하는 로직으로 구현하는 것입니다.
추가적으로 VO라는 객체도 존재하는데 VO는 값 그 자체를 표현하는 객체입니다. 객체의 정보가 변경되지 않는 '불변성'(read-only)을 보장하는 친구이죠.
VO 내부에 선언된 속성(필드)은 VO 객체마다의 모든 값들이 같아야 똑같은 객체로 판별되며, 반대로 서로 다른 이름을 갖는 VO 인스턴스라도 모든 속성 값이 같은 경우에 두 인스턴스는 같은 객체로 인식됩니다.
VO에서 객체를 속성 값만으로 비교하도록 여러 알고리즘들이 구현되어 있습니다.
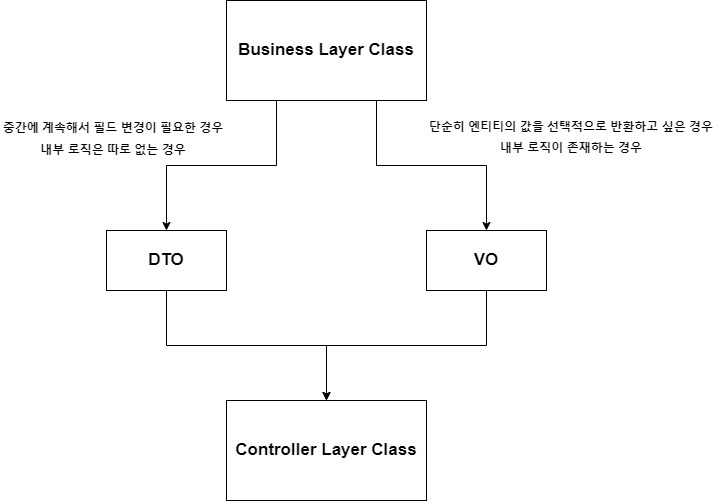
VO의 경우 Read Only의 목적이 강하고 데이터 자체가 불변하도록 설계하는 것이 원칙인 반면, DTO는 주로 데이터 수집의 용도가 더 강하다고 볼 수 있습니다.
NestJS와 같은 현대적인 백엔드 프레임워크에서는 VO 개념을 명시적으로 사용하지 않는 경우가 많습니다. 이는 주로 NestJS가 DDD(Domain-Driven Design) 패턴을 엄격하게 따르지 않기 때문이라고 합니다.
심심찮게 나오는 '도메인'이라는 용어에 대해서 알아보도록 하겠습니다.
위키피디아에 따르면 Domain Model의 정의는 다음과 같습니다.
아키텍처에서 도메인 레이어(Domain Layer)의 결과물을 도메인 모델이라고 부르기도 하며, 아래에서 배울 4-tier architecture와 같은 아키텍처에서 도메인 레이어는 도메인의 개념, 도메인 정보, 도메인 규칙을 표현하는 책임을 집니다.
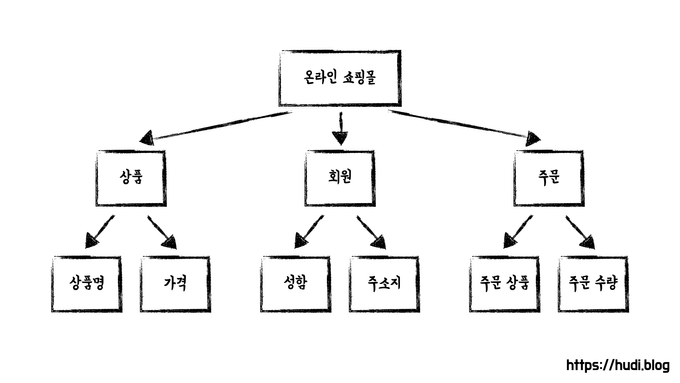
우리가 도메인이라고 한다면 프로그래밍으로 해결하고자 하는 주제에 대한 영역과 핵심 비지니스 요구사항을 의미하는 단어로 볼 수 있고 도메인은 다시 그 아래의 하위 도메인으로 나누어질 수 있습니다.
예를 들어, 위와 같이 '온라인 쇼핑몰' 개발 시 그 자체를 도메인이라고 부를 수 있고 그로부터 나누어지는 '상품', '회원' 등의 하위 도메인이 있는 것입니다.
이러한 도메인에 대한 지식을 선택적으로 단순화하고 의식적으로 구조화 한 것이 도메인 모델이 됩니다.
그렇기에 사실상 도메인 모델이란 좀 더 광범위한 개념에서 사용되며 사실상 Entity가 Domain으로부터 만들어지는 것이라고 봐도 무방합니다.
자, 이처럼 클라이언트와 서버는 위와 같은 여러 객체를 통해서 데이터를 주고 받게 됩니다. 그러나 사용자가 제공하는 데이터가 백엔드의 비지니스 로직에서 사용될 때 올바른 데이터로써 사용되기는 힘든 일입니다.
그렇기에 데이터의 유효성 검증은 오래전부터 반드시 필요한 기능이었고, 특정 언어나 프레임워크에서 제공하는 유효성 검증 도구들이 점차 널리 보급되기 시작했습니다.
NestJS에서의 class validator 역시 객체지향 프로그래밍에서 타입 안전성과 데이터 무결성을 강화하기 위해 도입된 개념으로 그 목적은 클라이언트로부터 받은 데이터가 비지니스 규칙 및 로직을 만족하는지 검증하기 위해 사용합니다.
데이터 유효성 검증 부분을 비지니스 로직에 포함시키는 것이 아니라 따로 검증을 자동화하는 코드로 분리하면, 코드의 재사용성을 높이고 에러를 줄여준다는 장점이 있습니다.
NestJS의 class validator에서는 이 부분이 사용자 입력이나 API 요청을 처리할 때 데이터의 유효성을 검증하는 시점에서 사용되기 때문에 DTO 클래스를 정의할 때 각 필드에 데코레이터를 붙여줌으로써 검증이 자동으로 되도록 합니다.
Transfomation는 객체지향 프로그래밍의 다형성(polymorphism)과 캡슐화(encapsulation)를 촉진하는 도구로서 나오게 된 개념입니다. 이는 복잡한 데이터 구조를 특정 형태로 변환해야 하는 필요성에서 출발했습니다.
일반적으로 클라이언트에게 데이터를 응답할 때, 우리가 정의한 내부 모델을 클라이언트에 적합한 형태(DTO를 사용하여)로 변환하는 데 사용됩니다.
즉, 시스템 간 데이터 교환 시 다른 시스템이 이해할 수 있는 형태로 데이터를 변환하는 것이죠.
하지만 응답을 위해 만든 데이터를 적합한 형태로 만드는 것이 쉬운 일은 아니다보니 이를 분리하여 따로 마련한 기능이 transformation인 것입니다.
쉽게 말하자면 클라이언트로부터 넘어온 JSON 객체는 literal 객체이지 우리가 코드 내에서 정의한 클래스의 인스턴스는 아닙니다. 똑같은 속성들과 타입을 가졌을지라도 말이죠. Axios를 비롯해서 NestJS에서 자주 사용되는 HTTP API 중 어느 것도 클래스의 인스턴스 자체를 응답을 넘겨줄 수 없습니다.
[
{
"id": 1,
"firstName": "Johny",
"lastName": "Cage",
"age": 27
},
{
"id": 2,
"firstName": "Ismoil",
"lastName": "Somoni",
"age": 50
},
{
"id": 3,
"firstName": "Luke",
"lastName": "Dacascos",
"age": 12
}
]외부 API를 통해 위와 같은 JSON 리터럴 객체를 받았다고 가정해 보겠습니다. 클라이언트에 서버로 데이터 요청을 보낼 때는 보통 JSON 객체가 들어오기 때문에 무조건 스트링 타입으로 이를 받아야 합니다.
이 값을 그대로 사용한다면야 좋겠지만, 실제 개발을 하다보면 문자열을 정수형으로 변환해야 한다거나 우리가 만든 DTO에 맞게, 각 타입에 맞게 잘 가공해야 하는 경우가 반드시 있는데 그러기 위해서는 이러한 JSON 객체를 클래스의 인스턴스로 바꿔 전달받을 수 있어야 합니다.
그러면 위 JSON처럼 값만 있는 리터럴 객체라면 추가 가공은 별도의 함수에서 처리해 주어야 하는데, 그렇게 되면 상태와 행위가 따로 노는, 즉 응집력 떨어지는 코드가 되기 때문에 그렇게 좋은 상황은 아닙니다.
이를 NestJS에서는 class-transformer가 해결해줍니다.
NestJS에서는 class-validator를 통해 많은 기능을 사용할 수 있습니다.(제네릭을 활용한 HTTP API 함수, 카멜케이스 <-> 스네이크, 특정 필드 제외, 중첩 객체 반환 등등..) 이에 대한 자세한 설명은 이후 포스팅에서 다루도록 하겠습니다.
앞서 말했듯 JSON과 같은 리터럴 객체를 클래스의 인스턴스로 바꾸는 것을 역직렬화라고 하고 그 반대로 클래스 인스턴스를 JSON 객체로 바꾸는 것을 직렬화라고 합니다. 우리가 쿼리 결과와 같은 것을 그대로 클라이언트에게 보내주면 DB 구조가 노출될 가능성이 있기 때문에 잠재적인 Injection 위험을 갖게 되어 이를 가공해야 할 필요가 있는 것입니다.
또한 JavaScript로 백엔드를 좀 짜봤다 하시는 분들은 아시겠지만 더 이상 JSON.stringify()를 따로 해주지 않아도 된다는 엄청난 장점이 있습니다..
Eric Evans의 Domain-Driven Design에 따르면 Repository는 객체의 collection을 저장, 검색하는 등의 동작을 캡슐화한다고 합니다. 여기서 Collection은 저장, 검색 등이 가능한 객체의 모임입니다.
마찬가지로 Patterns Of Enterprise Application Architecture에 따르면 "Domain 객체에 접근하기 위해 Collection과 같은 인터페이스를 사용하며, 도메인과 data mapping layer 사이를 중재한다"고 정의하고 있습니다.
얼핏 보면 Repository는 data를 다루는 것이고 내부적으로 sql을 감추고 있다는 점에서 DAO와 별반 다를 것 없어보이지만 Repository는 객체의 collection을 다루기 때문에 캡슐화, 즉 인터페이스를 제공한다는 점에서 DB 테이블보다는 객체 중심의 Layer라고 할 수 있습니다.
따라서 Repository로 다루는 객체를 다루기 위해서 여러 테이블에 접근해야 한다면, 여러 DAO를 사용할 수 있는 것입니다.
(Repository: 객체 중심 | DAO: 데이터 저장소(DB 테이블) 중심)
Nest에서 Repository는 일반적으로 ORM(Object-Relational Mapping) 프레임워크에서 제공하는 클래스나 인터페이스로, 앞선 데이터베이스 Entity와 직접적으로 상호작용하는 메서드들을 캡슐화합니다. 그렇기에 Repostiory는 데이터베이스의 CRUD 작업을 추상화한 것이라고 할 수 있겠습니다.
한 문장 정리: Repository는 데이터베이스 작업을 추상화하여 데이터베이스 엔티티와의 상호작용을 간소화하는 객체입니다. (NestJS에서는 ORM을 사용할 때 사용되는 개념입니다!)
<흐름으로 보는 용어 정리>
Controller가 사용자의 요청을 받아 그것에 상응하는 서비스를 매핑하는 route를 담당하여 클라이언트로부터 요청과 함께 데이터를 받으면 어떤 비지니스 로직을 수행하는 Service로 매핑해주는데 이 Service 함수의 내용에 데이터베이스에 변경을 가하는 내용이 있다고 가정하면, 우선은 데이터베이스에 접근하기 위해서 DAO를 통해야한다. 그런데 이 DAO에 접근을 할 때는 그냥 데이터를 넣어주면 안되고 DTO라는 단위로 변환하여 DAO의 어떤 동작을 호출하게 된다. 그러면 이제 DAO를 통해 실제 데이터베이스에서 데이터를 가져오게 되는데, 이 때 실제 데이터베이스 와 1대1로 매핑되어 있는 Entity를 활용하여 가져올 수 있는 것이고 우리는 'SELECT * FROM USER' 와 같은 쿼리문을 직접 보내서 가져오는 것이 아닌 ORM을 통해서 가져오는 것이기 때문에 Repository 개념이 사용되어 repository가 Entity를 통해 데이터베이스에 데이터를 넣게 되는 것이다.
아키텍처와 디자인 패턴은 소프트웨어 설계에서 효율성을 증가시키는 중요한 요소이며 이들은 모두 객체지향의 5가지 원칙인 SOLID를 준수하도록 노력하는데요. SOLID는 무엇을 말하는 것일까요?
소프트웨어 아키텍처는 소프트웨어 시스템의 고수준 구조를 설계하는 체계적인 방법입니다. 이는 시스템 구성 요소들이 어떻게 상호 작용하고 관련되는지를 정의하는 것입니다.
소프트웨어 아키텍처는 시스템의 설계도 역할을 하며 개발 프로세스를 안내합니다. 소프트웨어 시스템이 요구 사항을 충족시키면서도 유지보수가 용이하고, 확장 가능하며, 복원력이 있는지 확인하는 데 중요합니다.
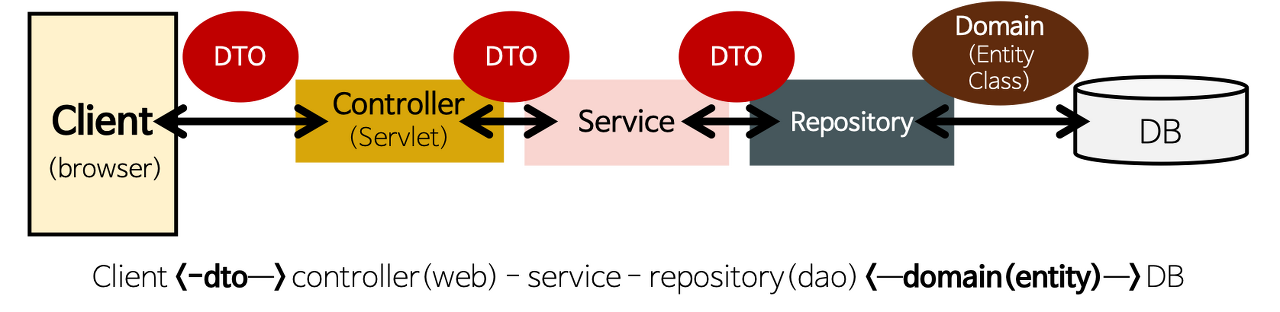
우리가 백엔드 개발을 하다보면 위와 같이 프로젝트 구조를 잡는 경우를 많이 보셨을 것입니다.
보시면 알겠지만 DTO 단위로 데이터가 이동하게 되는 것을 볼 수 있는데 이 역시 객체지향 패러다임을 고려하여 설계되었기 때문입니다.
이와 같이 데이터를 효율적으로 서버와 클라이언트 사이에 전달하기 위해 설계한 아키텍처는 여러가지가 있는데요. 그 중 몇 가지를 소개해드리겠습니다.
소프트웨어 아키텍처 패턴의 종류
소프트웨어 개발 역사 수십년간 발전한 수많은 아키텍처와 패턴들이 존재합니다. 그리고 그 중에서 우리 프로젝트에 맞는 아키텍처를 선정하는 것은 굉장히 중요한 일이죠.

<Monolithic Architecture>
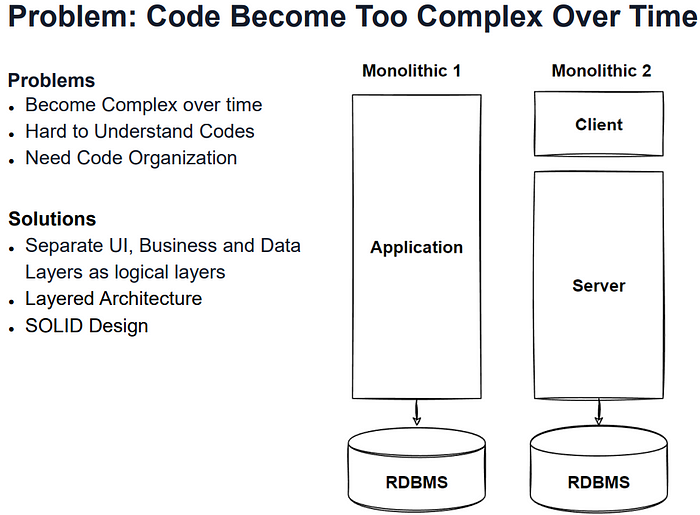
모든 종류의 서비스가 하나의 애플리케이션으로 구성되어 있는 아키텍처를 의미합니다.
해당 아키텍처의 특징으로는 하나의 주요 프로세스가 구성되고 모든 서비스가 하나의 DB endpoint를 사용한다는 점에 있습니다.
이 아키텍처는 단 한줄만 코드가 수정이 되더라도, 애플리케이션 전체의 재배포가 필요하며 싱글 혹은 멀티 모듈로 구성할 수도 있지만 CI(코드 통합)의 단위가 달라지는 것일뿐 여전 CD(배포)의 범위는 그대로라는 특징을 갖습니다.
어쨌든 이 방식은 개발하고 빌드하여 나온 결과를 서버에서 실행시키기만 하면 되기 때문에 굉장히 이해하기 쉬운 방식이기도 하고, 고려할 것이 그리 많지 않아 서버 리소스의 효율적인 활용이 가능하여 일반적으로 많이 사용되는 방식입니다.
그렇기에 소수의 팀원으로 빠르게 오픈을 해야 하는 스타트업이나 개발자들의 역량이 낮은 환경, DevOps등의 전문 인력이 부족할 경우 사용될 수 있는 아키텍처라고 할 수 있습니다.
하지만 이 아키텍처는 단일 DB에 대한 의존성이 크기에 수평 확장(Scale Out)이 어렵고 프로젝트의 규모가 커질수록 복잡성이 증가하여 유지보수에 대한 부담이 증가합니다. 또한 배포 시간도 오래걸리고, 서버에 장애가 발생했을 때 전체 애플리케이션에 영향을 준다는 단점이 존재했습니다.
<Layered Architecture>
Layered Architecture는 오늘날 가장 일반적으로 널리 사용되는 아키텍처입니다. 구성되는 계층의 숫자에 따라 N 계층 아키텍처(N-tier Architecture)라고도 합니다.
애플리케이션이 레이어로 구분되어 각 레이어에서 특정 역할과 관심사가 할당되게 됩니다.(화면 표시, 비지니스 로직, DB 작업 등). 이는 객체 지향에서 강조하는 관심사의 분리를 가져올 수 있게 되죠. 특정 레이어의 구성요소는 그 레이어에 관련된 기능만 수행한다가 원칙인 것입니다.
이러한 특징으로 Layerd Architecture는 높은 유지보수성과 쉬운 테스트라는 장점을 갖고 있습니다.
1) 4-Tier Layered Architecture
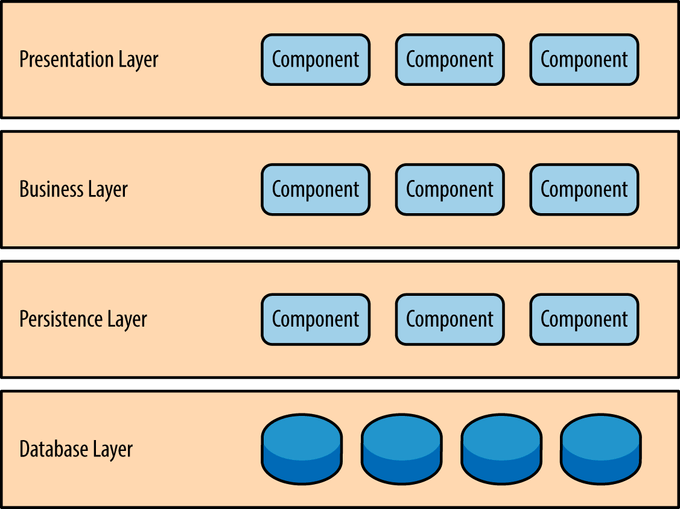
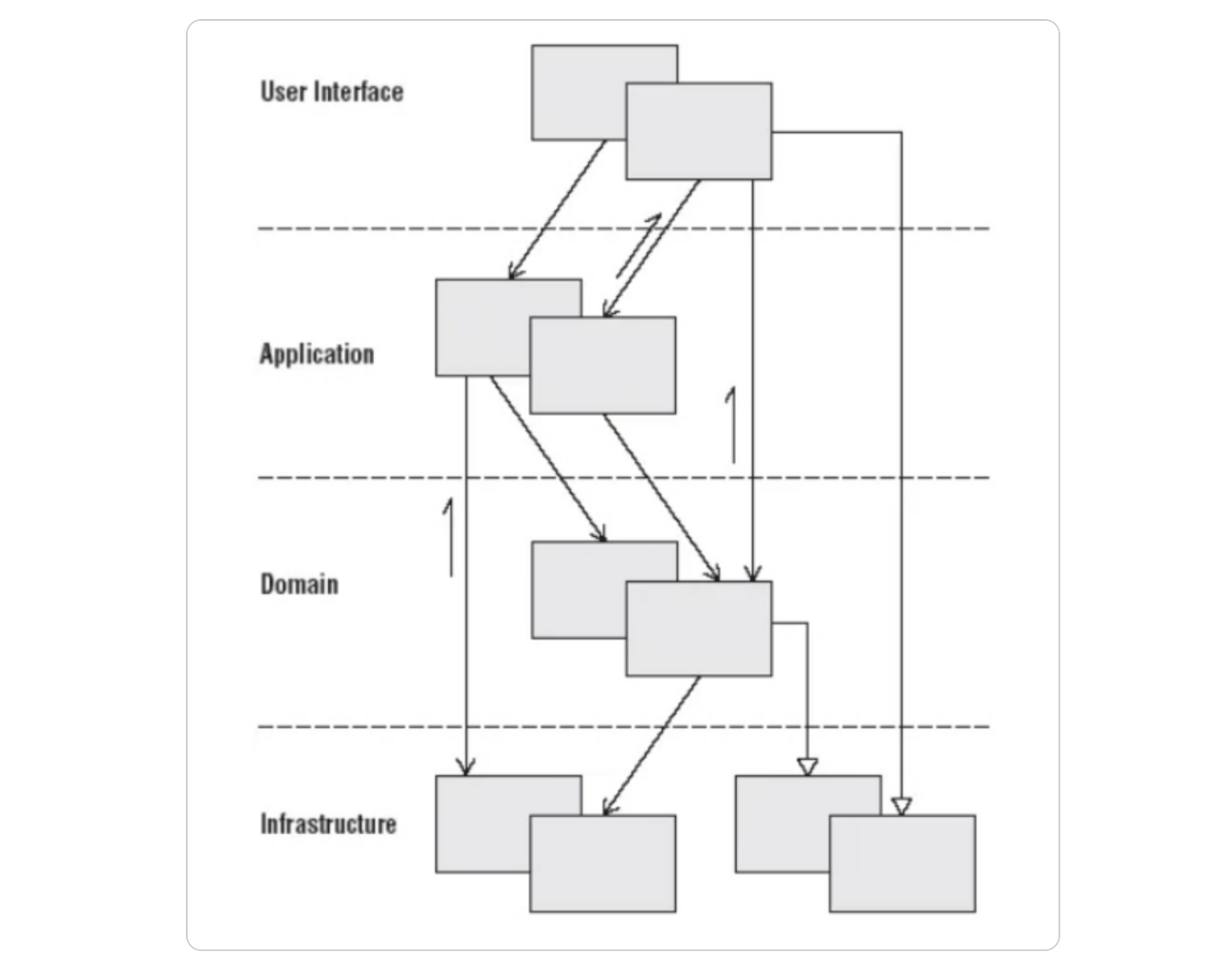
그 중 '4계층 아키텍처'는 위와 같은 두 가지 방식으로 설명될 수 있습니다. 두 방식은 4계층으로 나뉘었다는 점에서 구조적으로는 유사하다고 할 수 있지만, 계층간 명칭과 특정 측면에서의 초점이 약간 다릅니다.
왼쪽 그림은 보다 전통적인 계층 구조를 나타낸 모습이고 오른쪽 그림은 주로 도메인 주도 설계(Domain-Driven Design, DDD)에서 사용되는 계층 구조를 따릅니다.
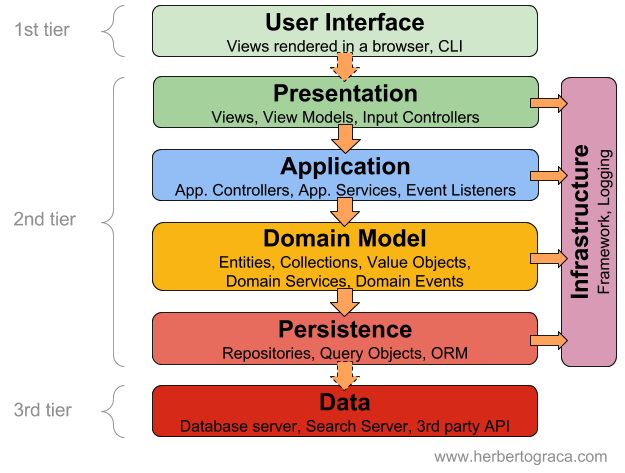

위와 같은 계층 속에서 상위 계층은 하위 계층에서 의존하며, 상위 계층은 하위 계층을 몰라도 된다 라는 것이 원칙입니다. 이로써 각 계층은 독립적으로 개발되고 테스트할 수 있으며, 변경이 필요한 경우 다른 계층에게 영향을 미치지 않게 됩니다.
2) 3-tier architecture
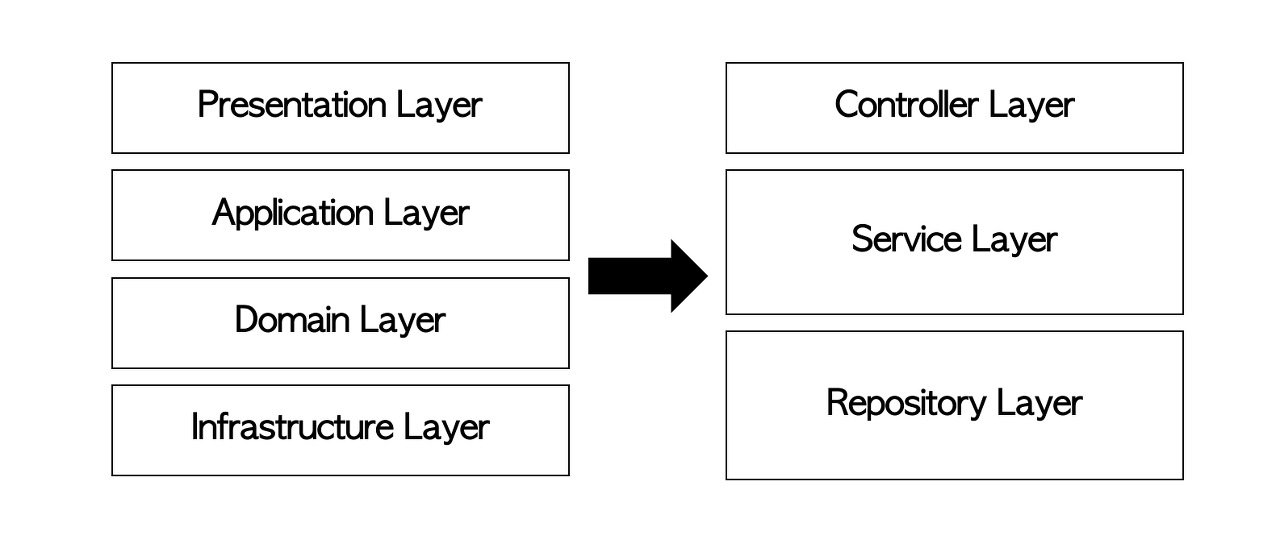
백엔드 개발을 할 때 많은 프로젝트에서는 3-tier architecture를 사용하게 되는데요. 일반적으로는 Presentation Tier - Application Tier - Data Tier와 같이 3계층으로 분리하고 이러한 각 계층을 대부분의 프레임워크에서는 Controller-Service-Repository(or DAO)라는 용어로써 더욱 추상화된 개념으로 사용됩니다.
3) Event-Driven Architecture
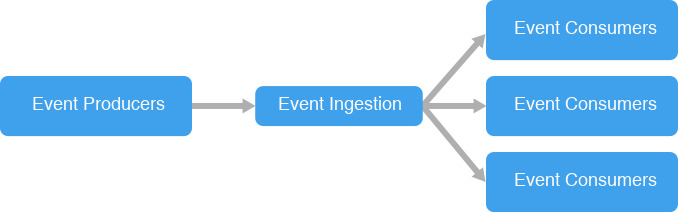
이벤트 기반 아키텍처는 MSA가 적용된 시스템을 보완하는 아키텍처로 이벤트의 제작, 감지, 소비, 반응을 제고하는 소프트웨어 아키텍처 패턴입니다. 여기서 이벤트는 상태의 상당한 변화로 정의할 수 있는데, 예를 들어, 소비자가 자동차를 구매할 때 자동차의 상태는 "판매중"에서 "판매완료"로 바뀌는 것을 말할 수 있습니다.
분산 아키텍처 환경에서 이벤트를 생성하고 발행된 이벤트를 수신자에게 전송하는 구조로 수신자는 그 이벤트를 처리하는 방식으로, 상호 간 결합도를 낮추기 위해 비동기 방식으로 메시지를 전달하는 패턴입니다.
각 마이크로서비스는 함께 작동하지만 서로 다른 비즈니스 로직을 적용하고 자체 출력 이벤트를 보낼 수 있으며 주로 Message Broker ( Kafka, RabbitMQ) 와 결합하여 구성됩니다.
어떤 서비스에서 유저를 생성하고 생성된 유저에게 이메일을 발송하거나 포인트를 지급하는 로직을 구현해야 한다고 합시다. 이 경우 이벤트를 적용하기 전에는 service에서 유저를 생성하는 데이터베이스 생성 이후에 추가적인 로직을 작성해야 할 것입니다(이메일 발송 기능, 포인트 지급 기능 등).
그러나 이벤트를 적용하면 그러한 로직을 EventEmitter라는 발신자를 통해 특정 이름의 이벤트를 발생시키고 외부의 EventListener라는 수신자와 연결되어 이벤트 발생시 발동할 로직을 해당 함수에 분리하여 구현함으로써 더 유지보수가 쉽게 만들어 줍니다.
이외에 다른 추가적인 로직을 넣어야 한다면 service 로직을 변경시키지 않고도 새로운 비지니스 로직을 추가할 수 있게 됩니다.
+) clean architecture
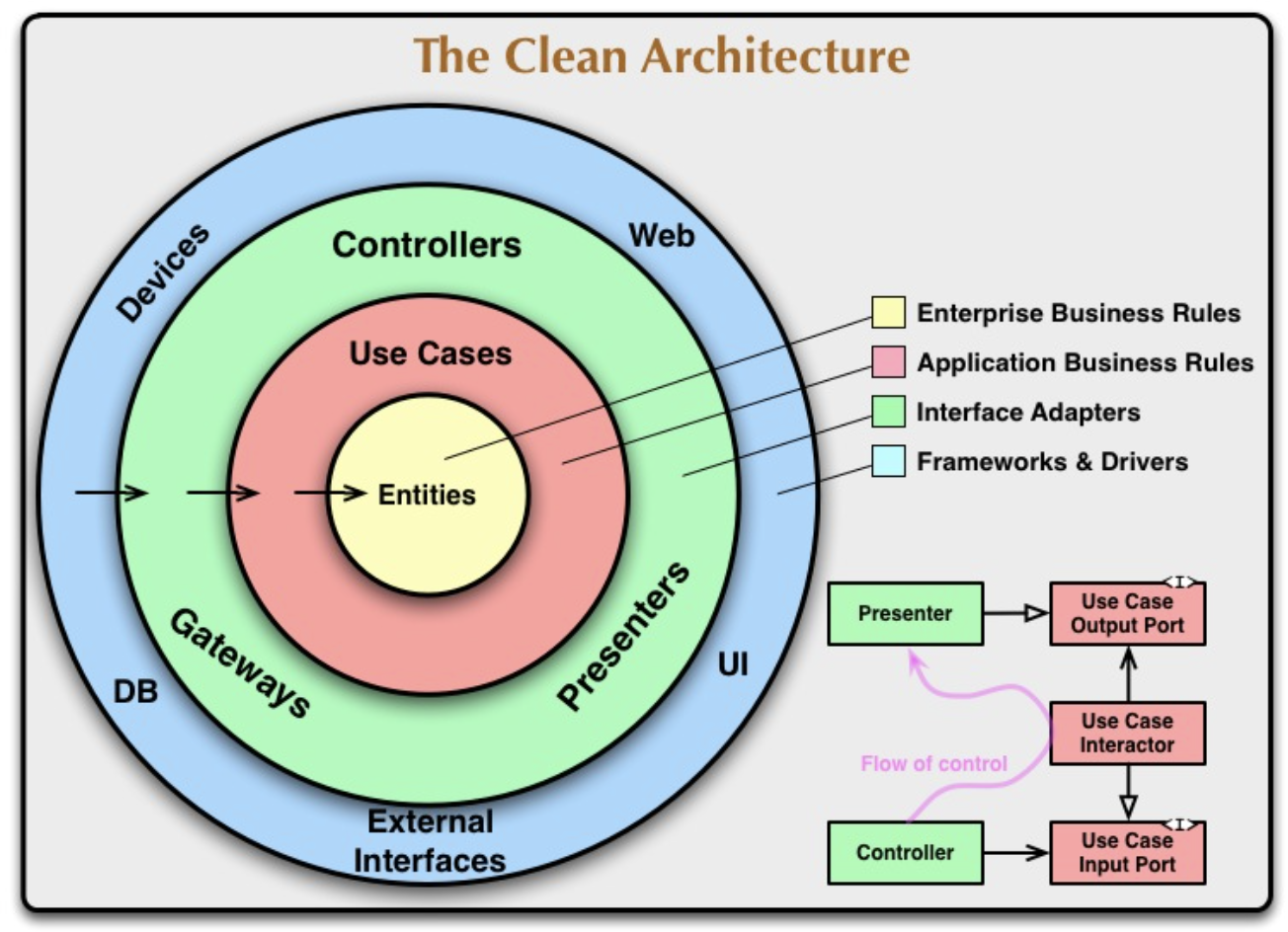
클린 아키텍처는 Robert C.Martin에 의해 제안된 소프트웨어 아키텍처 원칙으로 애플리케이션을 여러 동심원의 레이어로 나누고 각 레이어에 있는 컴포넌트가 안쪽 원에 있는 컴포넌트에만 의존성을 갖도록 하는 것입니다.
Layered Architecture의 한 형태로도 볼 수 있지만 그보다 더 확장된 개념이라고 할 수 있습니다.
바깥쪽 계층으로 갈수록 고수준의 정책을 포함하고, 안쪽 계층은 저수준의 구체적인 구현을 다룹니다. 중요한 것은 바깥쪽 계층이 안쪽 계층의 구체적인 구현에 의존하지 않고, 안쪽 계층만이 바깥쪽 계층의 인터페이스에 의존하는 "의존성 역전 원칙"을 갖습니다.

상상해볼까요? 우리가 도서관 관리 시스템을 만들고 있다고 해봅시다. 이 시스템에는 두 가지 주요 계층이 있습니다. 하나는 사용자 인터페이스(UI)계층이고, 다른 하나는 데이터 저장 계층일 것입니다.
"의존성 역전 원칙"에 따르면, 고수준의 사용자 인터페이스 계층은 저수준의 데이터 저장 계층의 구체적인 구현에 직접 의존하지 않습니다. 대신, 두 계층 사이에 추상화된 인터페이스를 두어, 고수준 계층이 이 추상화된 인터페이스에만 의존하게 됩니다. 이렇게 함으로써, 데이터 저장 방식이 변경되더라도 사용자 인터페이스 계층에는 영향을 주지 않고, 시스템의 유연성과 확장성을 향상시킬 수 있습니다.
바깥쪽 레이어부터 infrastructure layer, interface layer, application layer, domain layer로 보겠습니다.
CQRS란 데이터 저장소로부터 읽기와 업데이트 작업을 분리하는 패턴을 말합니다.
전통적인 아키텍쳐에서는, 데이터베이스에서 데이터를 조회하고 업데이트할 때 같은 데이터 모델이 사용되었습니다. 간단한 CRUD(Create-Read-Update-Delete) 작업에 대해서라면, 물론 이것은 문제없이 동작하겠지만 좀 더 복잡한 애플리케이션에서 이러한 접근 방식은 유지 보수를 어렵게 만든다는 요소가 될 것입니다.
예를 들어, 애플리케이션이 데이터를 조회할 때, 각기 다른 형태의 DTO를 반환하는 방식으로 매우 다양한 쿼리들을 수행할 수 있는데 각각 다른 형태의 DTO들에 대해서 일일히 객체 매핑을 해야하는 것은 코드가 굉장히 복잡해질 수 있습니다. 또한 데이터를 쓰거나 업데이트할 때는 복잡한 유효성 검사와 비지니스 로직이 수행되어야 하기도 하죠.
결과적으로 이 모든 행위를 하나의 데이터 모델이 하려한다면 너무 많은 것을 수행하는 복잡한 모델이 될 것입니다.
그래서 CQRS는 읽기와 쓰기를 각각 다른 모델로 분리합니다. 명령(Command)를 통해 데이터를 쓰고, 쿼리(Query)를 통해 데이터를 읽습니다.
요구사항이 복잡해질수록 도메인 모델도 복잡해지는데 데이터를 조회한 쪽에서는 현재의 복잡한 모델 구조의 데이터가 필요하지 않은 경우가 대부분이므로 조회 시의 모델과 데이터 변경 시의 모델을 다르게 가져가는 방식이라고 정리할 수 있겠네요.
CQRS를 사용하면 애플리케이션의 퍼포먼스, 확장성, 보안성을 극대화할 수 있습니다. 또한 CQRS 패턴을 통해 만들어진 시스템의 유연성을 바탕으로, 시간이 지나면서 지속적으로 시스템을 발전시켜 나갈 수 있으며, 여러 요청으로부터 들어온 복수의 업데이트 명령들에 대한 충돌도 방지할 수 있습니다.
CQRS를 사용하는 경우는 다음과 같겠습니다.
즉, 복잡한 도메인을 다루는 상황이고, DDD를 적용한다면 CQRS가 적합한 것입니다.
소프트웨어 디자인 패턴은 소프트웨어 디자인에서 공통적으로 발생하는 문제에 대해 재사용 가능한 해결책을 의미합니다. 상황에 맞게 사용될 수 있는 문제들을 해결하는데에 쓰이는 템플릿을 의미하는 것이죠. 프로그래머가 애플리케이션이나 시스템을 디자인할 때 공통된 문제들을 해결하는데 쓰이는 형식화된 가장 좋은 기술입니다.
쉽게 말해서 일종의 가이드라인을 만들어 놓고 그것대로 개발을 하면 개발자들이 더욱 원활한 소통을 할 수 있도록 만든 것인데, 이러한 가이드라인을 여러 개 만들어 놓고 상황에 맞는 가이드를 통해 개발할 수 있도록 한 것입니다. 여기서 가이드라인 하나하나를 '싱글톤 패턴', '어댑터 패턴'과 같은 디자인 패턴이라고 할 수 있는 것이죠.
| 생성 패턴 | 구조 패턴 | 행동 패턴 |
| 싱글톤 (Singleton) 팩토리 메소드 (Factory Method) 추상 팩토리 (Abstract Factory) 의존성 주입(Dependency Injection) 빌더 (Builder) 프로토타입 (Prototype) |
어댑터 (Adapter) 브릿지 (Bridge) 컴포짓 (Composite) 데코레이터 (Decorator) 퍼사드 (Facade) 플라이웨이트 (Flyweight) 프록시 (Proxy) |
책임 연쇄 (Chain-of-Responsibility) 커맨드 (Command) 인터프리터 (Interpreter) 이터레이터 (Iterator) 중재자 (Mediator) 메멘토 (Memento) 옵저버 (Observer) 상태 (State) 전략 (Strategy) 템플릿 메소드 (Template Method) 비지터 (Visitor) |
이외에 아키텍처 패턴으로 MVC 패턴이 존재하는데 이 패턴은 굉장히 자주 사용되는 패턴이기 때문에 따로 설명을 해드리도록 하겠습니다.
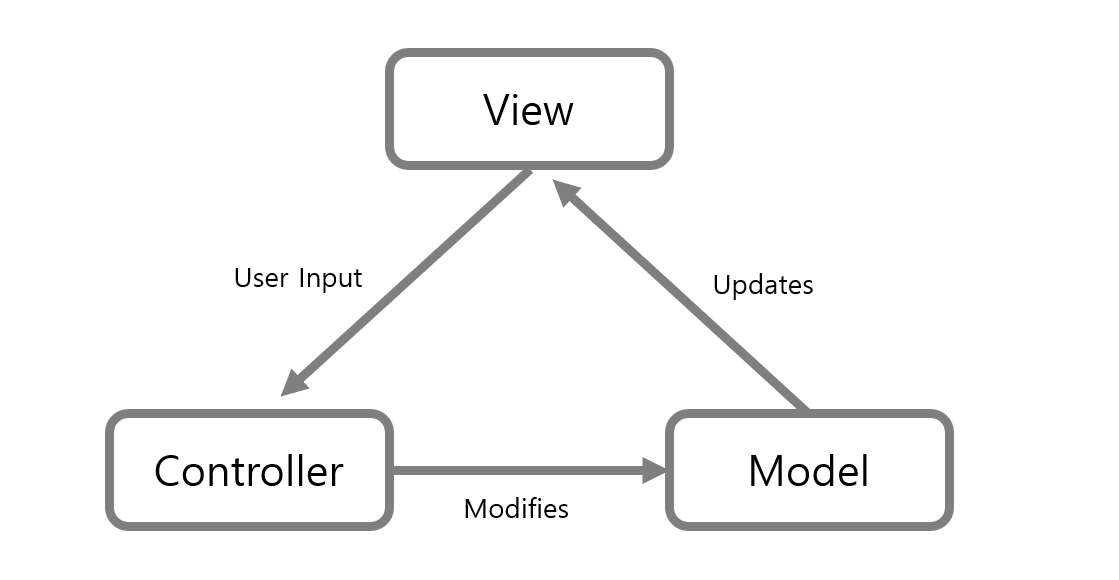
MVC(Model-View-Controller) 패턴은 애플리케이션을 개발할 때 사용자 인터페이스와 그 이외의 구성 요소를 Model과 View 및 Controller 등 세가지 역할로 구분하는 디자인 패턴을 말합니다.
사용자 인터페이스로부터 비지니스 로직을 분리하여 애플리케이션의 시각적 요소나 그 이면에서 실행되는 비지니스 로직을 서로 영향 없이 쉽게 고칠 수 있다는 핵심 내용입니다.
NestJS는 기본 defalt로 Express를 사용하기 때문에 컨트롤러와 provider를 다루는 방식에서 MVC를 사용하는 모든 기법들이 Express에서 사용되는 것처럼 Nest에서도 똑같이 사용될 수 있습니다.
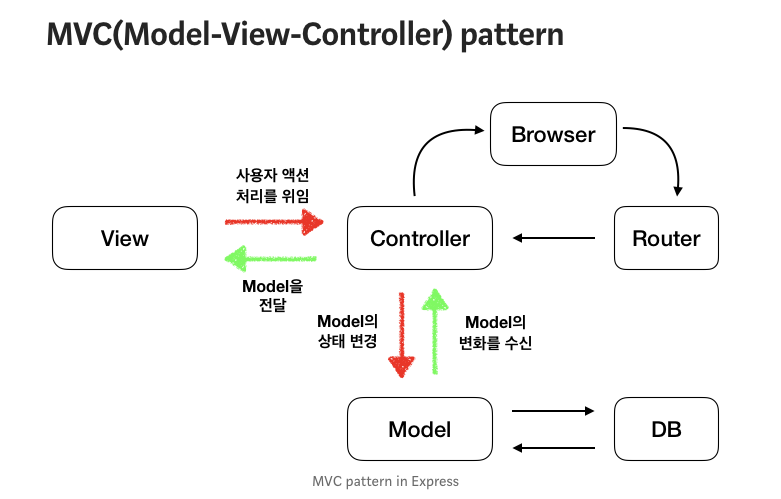
그림을 통해 보면 알 수 있듯이 비지니스 처리 로직(Model)과 UI 영역(View)은 서로의 존재를 인지하지 못하고 Controller가 이를 중간에서 Model과 View의 매끄러운 연결을 도와주게 됩니다.
NestJS는 주로 Model과 Controller 부분에 초점을 맞춘 프레임워크이며, View 부분은 주로 다른 프론트엔드 프레임워크(React, Vue, Angular 등)이 도맡아 처리합니다.
| Layer | Decorator |
| Presentation Layer | @Controller |
| Business Logic Layer(Service Layer, Domain Layer) | @Service |
| Data Layer | @Repository |
엄청난 양의 글이었지만 두고두고 헷갈리는 개념이 있을 때 와서 볼 수 있을 정도로 많은 개념을 정리한 글이었습니다. 막 여러 개의 개념을 하나씩 포스팅 되어 있는 것을 별로 좋아하지 않아 한 포스팅에 전부를 담으려고 해봤는데 분량이 넘치긴 하네요....ㅎㅎ
읽어주셔서 감사합니다!
| [NestJS] NestJS CLI로 REST API를 사용한 CRUD 기능 만들기(5분버전 vs. 심화버전) with TypeORM & MySQL (0) | 2024.01.24 |
|---|---|
| [NestJS] NestJS에서 Swagger 사용법 (feat. API Documentation) (2) | 2024.01.23 |
| [NestJS] NestJS 시작 (설치 & 구성요소 맛보기) (3) | 2024.01.22 |
| [NestJS] NestJS를 위한 선수지식 Node.js & Express.js 이해 (feat. Logging, 폴더 구조) (0) | 2024.01.21 |
| [NestJS] NestJS와 관련된 기술 용어 정리 (DI, IoC, AOP 등...) (0) | 2024.01.19 |
소중한 공감 감사합니다