새소식
반응형
의존성 주입을 알아보기 전에 먼저 Dependency, 즉 "의존성"이라는 것이 무엇을 말하는지 알아보겠습니다.
어떤 객체가 다른 객체와 직접 상호작용하거나, 어떤 객체가 다른 객체를 참조하고 있다면 '그 객체는 다른 객체에 의존성을 갖는다'고 말합니다. 또한 그러한 의존성을 직접 갖도록 하는 것이 아니라 제 3자로부터 주입 받는 것을 의존성 주입이라고 합니다.
이렇게만 들으면 이해하기 어려우니 위키피디아에 나와있는 5살에게 DI 설명하기를 한 번 볼까요?
위와 같은 비유 속에서 의존성이란 '아이'가 냉장고에 있는 음식이 먹고 싶을 때 '냉장고'에 직접 접근하도록 하는 것이 아니라 '부모님'이 대신 그 냉장고에 접근하여 필요한 음식을 가져다주는 경우 '냉장고에 대한 아이의 직접적인 접근'으로 생각할 수 있습니다.
만약 부모님이 대신 가져다 준다면 그러한 냉장고에 직접 접근해야 하는 의존성의 주체가 아이에서 부모님으로 역전되게 되는 것이죠.
즉, 의존성 주입이란 어떤 객체가 다른 객체를 필요로 할 때, 직접 그 객체를 가져오는 것이 아니라 필요하다고 말(선언)만 하면 프로그램이 그것을 대신 가져다 주는 역할을 하는데, "의존성을 다른 제3자가 대신 주입해준다." 정도로 생각하면 될 것 같습니다.
일반적으로 프로그램에게 어떠한 객체를 사용하겠다는 요청을 하면 프로그램이 그 객체를 대신 생성해서 주입해주기 때문에 객체 간의 의존성을 낮출 수 있는 것입니다.
의존성 주입은 중요한 개념인만큼 매우 간단한 코드로 의존성을 다시 설명해 보도록 하겠습니다.
class Dog {
walk(): void {
console.log('산책');
}
}
class PetOwner {
private animal: Dog;
constructor() {
this.animal = new Dog();
this.animal.walk();
}
}
위 코드에서 PetOwner라는 객체는 내부에서 Dog라는 객체를 직접 new 키워드로 생성하여 사용하게 됩니다. 이렇게 되면 앞서 말했던 의존 관계가 성립하게 되고, 이러한 의존 관계가 이어지면 안되는 이유는 Dog의 구현체가 변경될 경우 PetOwner는 Dog를 직접 참조하고 있기 때문에 Dog가 변경될 때마다 PetOwner까지 바꿔주어야 하는 문제가 생깁니다.
즉, PetOwner와 Dog사이에는 강한 결합(Tight coupling)이 생기게 되는 것인데요.(하나를 변경하면 다른 하나도 같이 변경됨) 이는 PetOwner를 단독으로 테스트를 하려해도 그 안에서 Dog 인스턴스를 생성하기 때문에 Dog가 잘 작동함이 보장되어야 PetOwner의 동작이 보장되어 단독 테스트가 불가능하다는 단점도 있습니다.
그렇다면 어떻게 해야지 이러한 요소들 사이의 결합을 약하게 할 수 있을까요?
interface Animal {
walk(): void;
}객체지향 프로그래밍에서는 위와 같이 인터페이스를 선언하여 해당 인터페이스를 implements하는 클래스를 가져오는 식으로 하면 됩니다. 이 인터페이스는 walk 메서드를 선언함으로써 모든 구현 클래스가 walk 메서드를 구현하도록 강제합니다.
class Dog implements Animal {
walk(): void {
console.log('산책');
}
}
class PetOwner {
private animal: Animal;
constructor(animal: Animal) {
this.animal = animal;
}
takeForWalk(): void {
this.animal.walk();
}
}
const myDog = new Dog();
const petOwner = new petOwner(myDog);
이 코드는 DI 원칙에 따라 PetOwner는 Animal 타입의 객체에 의존하는데, 이 의존성은 생성자를 통해 주입됩니다. 생성자에서 Animal 타입의 객체를 받아 내부 속성으로 할당함으로써, PetOwner의 인스턴스는 어떤 종류의 Animal과도 연결될 수 있습니다. 이런 방식은 PetOwner 클래스가 Dog 클래스의 구체적인 구현에 의존하지 않도록 합니다.
위와 같이 코드를 작성하면 이제 PetOwner는 Dog가 변화하더라도 영향을 받지 않고 Cat이나 Bird와 같이 다른 Animal을 implements하는 클래스 역시 가질 수 있게 되어 더욱 느슨한 결합(Loosely coupling)을 가질 수 있게 되는 것입니다.
이로써 PetOwner라는 고수준 모듈이 Dog라는 저수준 모듈에 의존하는 형태에서 Dog라는 저수준 모듈이 Animal이라는 고수준 모듈에 의존하는 형태가 되며 '의존 관계가 역전되었다'라고 합니다.
그렇다면 이러한 의존성을 "주입"한다는 것은 정확히 무슨 의미일까요?
여기서 주입은 전달로 해석하면 이해하기 쉬울 것입니다. 즉, 의존성 주입은 '필요한 것을 전달한다'의 의미인 것입니다.
위의 예로 외부에서 생성된 'Dog' 객체는 'PetOwner'의 생성자나 메소드를 통해 'PetOwner'에 전달되는 것을 의미합니다.
또한 Nest에서 말하는 의존성 주입은 객체 자체가 아니라 Framework에 의해 직접 객체의 의존성이 주입되는 설계 패턴을 의미합니다.
일반적으로 프로그래밍에서는 우리가 직접 코드를 작성하여 프로그램의 흐름을 제어합니다. 예를 들어, 어떤 작업을 수행할 객체를 만들고, 이 객체가 언제 어떻게 동작할지 결정합니다. 하지만 IoC에서는 이런 흐름이 뒤집혀 있습니다.
IoC에서는 프로그램의 흐름을 외부의 프레임워크나 라이브러리가 관리합니다. 여기서 '외부'란 우리가 작성한 코드가 아닌, 일반적으로 프로그래밍 언어나 라이브러리 제작자에 의해 제공되는 코드를 의미합니다. 이 프레임워크나 라이브러리는 특정 인터페이스를 제공하고, 개발자는 이 인터페이스에 맞추어 우선 구현을 합니다. 구현된 객체는 프레임워크에 전달되고, 프레임워크는 이 객체들을 사용하여 필요한 시점에 적절한 작업을 수행합니다.
특정 인터페이스를 제공하고 해당 인터페이스를 구현한다는 점에서 우리는 위의 예제로 IoC를 생각해 볼 수 있습니다. 'PetOwner'라는 클래스가 'Dog' 객체를 직접 생성하고 관리하는 대신, 'Animal'이라는 인터페이스를 구현하는 'Dog' 객체를 외부에서 받아 사용합니다. 이 경우, 'Dog' 객체의 생성과 관리는 외부에서 하며, 'PetOwner'는 단지 필요한 'Animal' 객체를 주입받아 사용하기만 합니다. 이렇게 외부에서 객체를 받아 사용하는 것을 '의존성 주입(DI)'이라고 하며, 이는 IoC의 한 예시입니다.
NestJS에서, IoC는 프로그램의 제어 흐름을 개발자에서 프레임워크로 옮기는 개념이며, 이를 통해 코드의 유연성과 재사용성이 향상됩니다. 의존성 주입(DI)은 이런 IoC의 원칙을 실제로 적용하는 한 방법으로, 객체의 생성과 관리를 프레임워크에 위임하여 코드의 결합도를 낮추고 유지보수를 용이하게 합니다.
Provider는 Nest에서 사용되는 가장 기본 개념 중에 하나입니다. 대부분의 기본 Nest 클래스(services, repositories, factories, helpers 등)는 모두 provider로 취급됩니다.
이름에서 알 수 있듯이 Provider는 무언갈 공급해주는 친구인데 공급되는 대상이 데이터베이스 접근, 로깅 서비스, 값 계산 과 같은 것으로, 쉽게 말해 일종의 '서비스'나 '기능'을 제공하기 때문에 Provider라는 이름이 붙여진 것으로 생각됩니다.
provider의 핵심 아이디어는 의존성(dependencies)을 주입할 수 있다는 점입니다. Provider는 특정 기능이나 서비스를 제공하는데, provider 자기 자신이 해당 기능이나 서비스를 필요로 하는 다른 곳(클래스나 모듈)에 '주입'될 수가 있는 것이죠.
'의존성 주입(Dependency Injection)'이라는 개념이 바로 이것을 의미합니다. 이는 객체가 다양한 관계를 서로 만들수 있고 이러한 객체들이 유기적으로 연결되도록 하는 기능을 Nest 런타임 환경에 위임합니다.
의존성 주입을 통해, 예를 들어 어떤 클래스 'A'에서 데이터베이스 접근 기능이 필요하다고 할 때, 필요한 데이터베이스 접근 기능을 가진 Provider 'B'를 그 클래스에 '주입'할 수 있습니다. 이렇게 하면, 그 클래스 'A'는 데이터베이스 접근 기능을 직접 만들거나 관리할 필요 없이, 주입된 Provider 'B'를 사용하여 필요한 기능을 사용할 수 있게 되는 것이죠.
공식문서에 따르면 Controller는 HTTP 요청을 집중적으로 다루고 더 복잡한 task들은 provider에게 위임해야 한다고 합니다.
정리하면 provider는 의존성 주입을 통해 다른 클래스에 서비스를 제공하는 객체로 애플리케이션 여러 부분에서 객체의 생성 및 공유를 관리하는 데 사용할 수 있습니다. 예를 들어, provider를 통해 데이터베이스 연결을 관리하거나 타사 api에 대한 접근을 구현할 수 있게되죠.
provider에 대한 자세한 설명과 사용법은 아래 링크를 참고하세요.
[NestJS] Provider 개념 정리 (+ Custom Provider)
1. Provider란? Providers는 Nest에서 기본을 구성하는 요소 중 하나입니다. Nest에서는 사용되는 대부분의 기본 클래스를 Provider로 취급합니다. Nest에서 클래스는 services, repositories, factories, helpers, 등의
cdragon.tistory.com
IoC 컨테이너는 이러한 Provider를 등록하고 관리하는 객체입니다. 즉, 프로그램이 필요로 하는 다양한 객체를 관리하고 객체의 생성을 책임지며, 그러한 객체들의 의존성까지 관리해주는 아주 훌륭한 친구이죠.
이로써 프로그래머는 코드 내에서 객체를 직접 만들고 관리할 필요 없이, IoC 컨테이너에게 필요한 객체를 요청하기만 하면 됩니다.
NestJS에서 사용되는 방식으로 설명을 드리겠습니다. 우리가 service 클래스를 만들고 이를 모듈(*.module.ts)의 providers 배열에 추가하면, NestJS의 IoC 컨테이너가 이 서비스의 인스턴스를 대신 생성 및 관리하고 해당 인스턴스를 필요한 곳에 직접 주입해줍니다. 그리고 Provider는 Nest의 라이프 사이클(생명주기)과 동기화된 Scope을 가지며 프로그램이 시작될 때 모든 의존성을 처리합니다.
또한 의존성 주입을 통해서 다른 클래스와 관계를 맺는 경우 IoC 컨테이너는 Provider의 메타데이터만을 분석하여 의존성 그래프를 생성합니다.
IoC 컨테이너는 그러한 의존성 그래프에 따라 필요한 provider를 인스턴스화하고 주입하는데, 이 과정에서 나중에 배우게될 @Injectable 데코레이터가 사용되고, 또한 인스턴스화된 Provider를 저장하고 참조할 수 있게 하는 데코레이터로써 @Inject을 사용합니다.
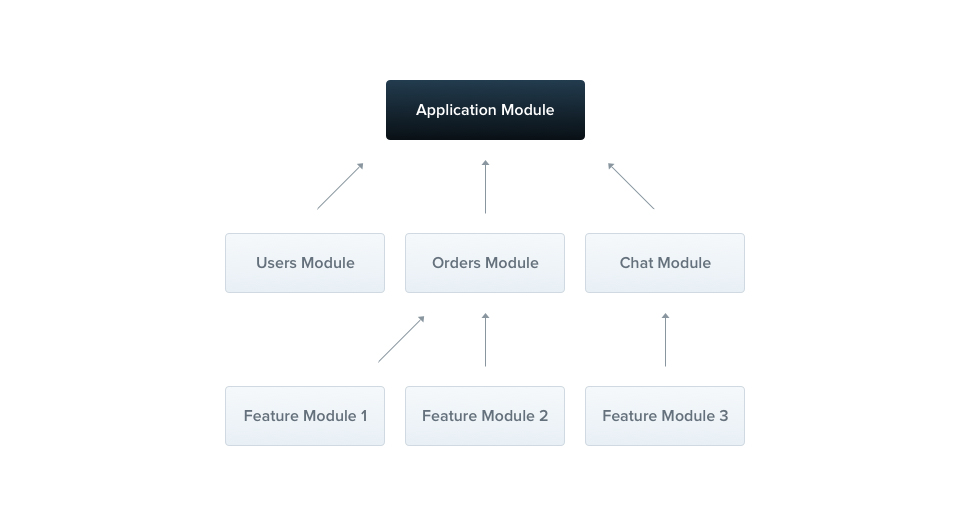
NestJS의 모듈은 애플리케이션의 일부분입니다. 모듈 내에서 providers를 선언하고, 이것들이 어떻게 서로 연결되고 외부에서 사용될 수 있는지 정의합니다. 즉, 모듈은 IoC 컨테이너에 의해 관리되는 provider들의 집합이라고 볼 수 있겠네요.
각 애플리케이션은 적어도 하나의 모듈(root module)을 갖습니다. 이 루트 모듈은 Nest에서 애플리케이션 그래프를 빌드하는데 사용하는 시작 지점입니다(통상적으로 AppModule). 즉, Nest가 model, provider관계 및 의존성을 관리하기 위해 사용하는 내부 자료 구조를 모듈이라고 할 수 있습니다.
Nest에서 @Module() 데코레이터가 달린 클래스이며 이는 Nest가 애플리케이션 구조를 만들 때 사용할 수 있는 메타데이터를 제공해주는 역할을 합니다.
뒤에서 나올 개념들의 설명을 위해서 한 가지 용어를 배우고 가겠습니다.
바로 관점 지향 프로그래밍인데요. AOP는 쉽게 말해 어떤 로직을 기준으로 핵심적인 관점, 부가적인 관점으로 나누어서 보고 그 관점을 기준으로 각각을 모듈화하겠다는 의미입니다.
우리가 개발을 하다보면 반복되는 작업들이 있습니다. 객체지향 프로그래밍에서는 관심사에 따라 단일 책임을 지도록 클래스를 분리하지만 특정 클래스에서는 "로깅"과 같이 여러 곳에서 사용되는 공통적인 기능이 있을 수 있습니다. 이처럼 AOP는 공통되는 작업들을 모아서 하나의 책임을 지는 기능으로 묶고 필요한 적절한 시기에 적용하는 개념입니다. 따로 코드 밖에서 개발을 해두고 프록시 개념으로 메서드가 실행되기 전, 실행된 직후, 실행시점에 따라 따로 기능을 적용시키는 것입니다.
여기서 이런 파편화된 관심사를 모은 것을 Aspects라고 부릅니다.
관점은 크게 두 가지로 나눠질 수 있는데, 핵심적인 관점은 결국 우리가 서비스에 적용하고자 하는 핵심 비지니스 로직이 되고, 부가적인 관점은 그러한 핵심 로직들을 실행하기 위하여 행해지는 데이터베이스 연결, 로깅, 파일 입출력 등의 작업들을 예시로 들 수 있습니다.
한 가지 비유를 통해 이해해 볼까요?

우리가 큰 연극을 준비한다고 생각해봅시다. 연극에는 많은 배우들과 장면들이 있고 각 배우는 자신의 역할을 하며, 각 장면은 연극의 다른 부분을 보여주게 되죠. 이 모든 것들이 연극 전체의 이야기를 만들어 냅니다.
그런데 연극에서 중요한 부분 중 하나는 '무대 뒤'에서 일어나는 일들입니다. 예들 들어, 무대 조명, 소리 효과, 배우들의 의상 변경 등이 있겠죠. 이런 일들은 관객들에게 직접 보이지는 않지만, 연극이 잘 진행되기 위해선 꼭 필요합니다. 이러한 '무대 뒤' 작업들은 연극의 모든 장면과 배우들에게 영향을 미치지만, 각 배우나 장면에 직접적으로 속하지는 않기 때문에 배우들은 오로지 연기에만 집중할 수 있게 됩니다.
AOP에서 '관점'이라는 용어는 연극의 '무대 뒤' 작업들과 비슷합니다. 프로그래밍에서 각 클래스나 함수는 자신의 역할(배우의 역할이나 장면)을 하지만, 로깅, 보안 검사, 데이터베이스 트랜잭션 관리 같은 공통 기능들(조명 작업, 마이스 세팅 ...)은 이들 모두에게 영향을 미칠 수 있습니다.
따라서 이런 공통 기능들은 '관점'으로 따로 정의해서 필요할 때마다 쉽게 적용할 수 있게 프로그래밍 하는 것이 AOP인 것입니다. 이렇게 함으로써, 각 클래스나 함수는 자신의 주된 역할에 집중할 수 있고, 공통 기능은 따로 빼서 별도로 관리할 수 있습니다.
AOP에서 각 관점을 기준으로 로직을 모듈화한다는 것은 코드들을 부분적으로 나누어서 모듈화하겠다는 의미이기도 합니다. 이때 소스 코드 상에서 다른 부분에 게속 반복해서 쓰는 코드가 있다면 이를 흩어진 관심사(Crosscutting Concerns)라고 부르게 됩니다.
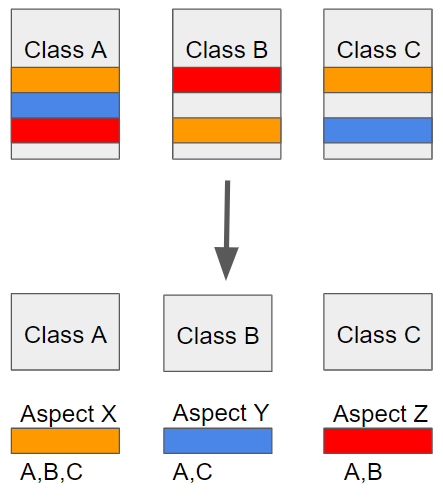
위 그림과 같이 흩어진 관심사를 Aspect로 모듈화하고 핵심적인 비지니스 로직에서 분리시켜 재사용하겠다는 것이 AOP의 취지입니다.
간단한 요약을 하자면 다음과 같습니다.
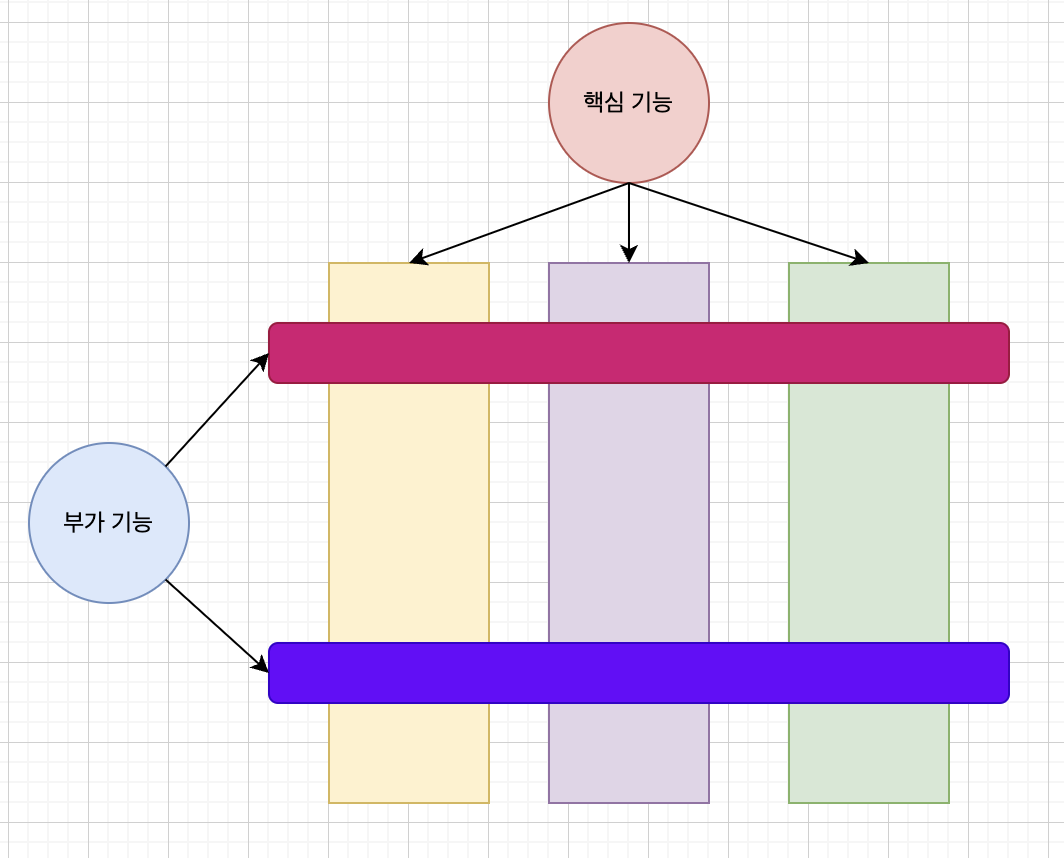
실제 사례로는 클라이언트가 서버에게 어떤 요청을 보냈는지에 대한 정보를 출력하는 Logging 기능이 위 그림의 보라색 부분처럼 모든 컨트롤러에 공통적으로 존재한다고 하면, 이 기능을 수평적으로 묶어 모듈화를 한 것이라고 보면 되겠습니다.
Nest에서는 Interceptor를 AOP에서 영감을 받아 만들어졌다고 합니다.

Interceptor라는 용어는 '가로채다'라는 뜻의 Intercept에서 파생되어 나오게 되었습니다. 즉, Interceptor는 데이터나 요청이 애플리케이션의 특정 부분을 통과할 때 '가로채는' 역할을 하게 되는데요. 주로 네트워크 요청을 처리할 때 사용됩니다. 예를 들어, 사용자가 웹사이트에 로그인을 하려고 할 때, Interceptor는 이 로그인 요청을 가로채서 사용자의 정보가 올바른지 확인하고 필요한 작업을 수행합니다. 일종의 교통 흐름을 제어하는 교통 경찰의 역할이라고 할 수 있겠네요.
Interceptor의 기능은 다음과 같습니다.
위처럼 각 항목은 공통된 관심사의 성질을 띠며, 이런 관심사들을 들어오고 나가는 요청 및 응답을 처리하는 controller 클래스에 적용할 수 있습니다.
주로 로깅, 데이터 변환, 요청 timeout을 할 때 자주 사용됩니다.
컨트롤러는 앞서(MVC, layered architecture, ...) 많이 등장하고 정리한 단어이지만 Nest에서의 Controller를 다시 정리해보도록 하겠습니다.
Nest에서 Controller는 MVC에서 설명드린 Controller의 기능을 동일하게 합니다. 들어오는 request를 다루어 클라이언트에게 response를 반환하는 책임을 갖고있죠.
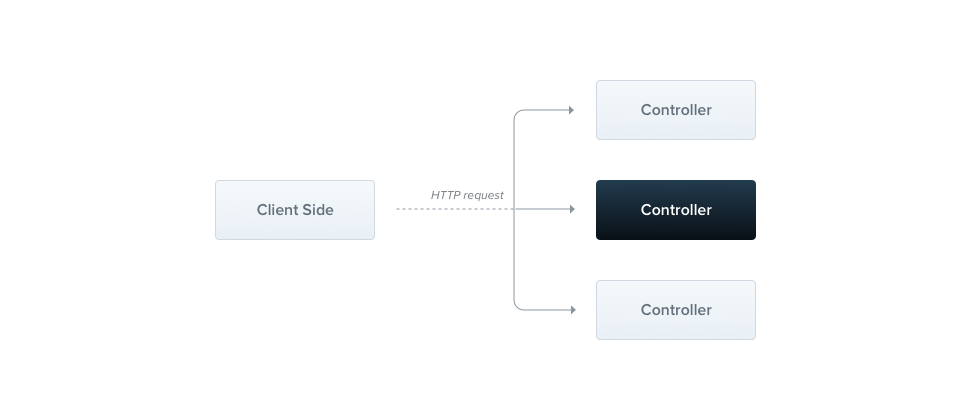
컨트롤러의 목적은 애플리케이션의 특정 요청을 받는 행위에 집중하는 것입니다. 그리고 routing이라는 메커니즘은 어느 controller가 어느 request를 받도록 할지를 컨트롤하는 것입니다. (말 그대로 경로를 지정해주는 것이죠.)
대체로 각 컨트롤러는 하나 이상의 route를 갖고있고 또 다른 route들은 각기 다른 actions을 수행할 수 있습니다.
controller를 만들기 위해서 Nest에서는 클래스와 decorator라는 것을 사용합니다.
Decorator: 일종의 함수로 단어 의미 그대로 코드 블럭을 한 층 더 장식해 주는 역할을 합니다. 메서드/클래스/프로퍼티/파라미터 위에 '@' 기호를 붙여 사용합니다.
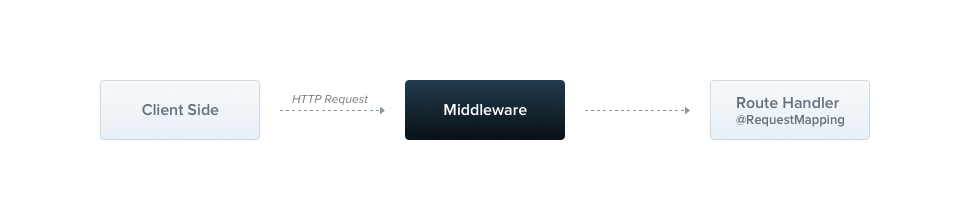
미들웨어는 route handler 전에 호출되는 함수입니다. 미들웨어 함수는 request와 response 객체, 그리고 next()라는 미들웨어 함수(애플리케이션의 request-response 사이클 안에 존재하는)에 대한 접근을 갖습니다.
이러한 next 미들웨어 함수는 일반적으로 'next'라는 변수로 표시가 됩니다.
기본적으로 nest의 미들웨어는 express에서 사용하는 미들웨어의 개념과 동일한데요. express에서 설명하는 미들웨어의 범위는 다음과 같습니다.
겉보기에는 앞에서 다룬 Interceptor와 중간에 코드를 실행한다는 점에서 크게 다를 것이 없어보이는데요. 둘의 차이는 다음과 같습니다.
Middleware는 HTTP 요청 처리 과정에서 가장 먼저 실행됩니다.(Guard보다도 먼저) 주로 요청(req), 응답(res), 그리고 다음 미들웨어로 넘어가는 함수(next) 이렇게 세 가지 파라미터를 사용합니다. 그리고 특정 클래스나 메소드가 실행되기 전에 동작하기 때문에, 어떤 클래스나 메소드가 실행될지를 정확히 알 수 없습니다. 심지어는 라우트 핸들러에 아직 동작하기 전이기에 존재하지 않는 경로에 대해서도 동작할 수 있죠.
Interceptor는 가드(Guards)보다 이후에, 파이프(Pipes)보다는 이전에 동작하는데, 'next.handle()'을 호출하기 전과, 컨트롤러 로직이 'next.handle()'에 연결된 '.pipe()'안에서 실행되는 로직 사이에서 동작합니다. 그리고 중요한 점은 Middleware와는 다르게 실행 컨텍스트(ExecutionContext)를 가지고 있어서 클래스나 route handler(컨트롤러 메서드)에 대한 메타데이터를 읽을 수 있습니다. 또한, Reflector를 사용하면 추가적인 메타데이터를 주입할 수도 있죠.
정리하자면 Middleware는 HTTP 요청의 가장 앞단에서 동작하며 주로 요청과 응답을 처리하는 데 사용되고, Interceptor는 보다 세부적인 요청 처리 단계에서 실행되며, 다양한 정보에 접근하고 조작할 수 있는 더 많은 기능을 제공합니다.
하지만 NestJS는 인터셉터, 가드, 파이프와 같은 다른 확장 기능들을 제공합니다. 이들은 더 세부적인 요청 처리, 데이터 변환, 예외 처리 등에 사용되며, 미들웨어보다 더 많은 컨텍스트 정보에 접근할 수 있기 때문에 미들웨어를 잘 사용하지는 않습니다.
Nest에는 애플리케이션 전체에서 처리되지 않은 모든 예외를 처리하는 exception layer가 내장되어 있습니다. 애플리케이션 코드에서 처리되지 않은 예외가 발생하면 이 계층에서 이를 포착하여 적절한 user-friendly 한 응답을 자동으로 전송합니다.
기본적으로 이 작업은 내장된 전역 예외 필터(global exception filter)에 의해 수행되며, 이 필터는 HttpException 유형(및 하위 클래스)의 예외를 처리해줍니다. 예외로 인식되지 않는 경우에, 기본으로 제공하는 exception filter는 다음과 같은 JSON response를 내뱉습니다.
{
"statusCode": 500,
"message": "Internal server error"
}
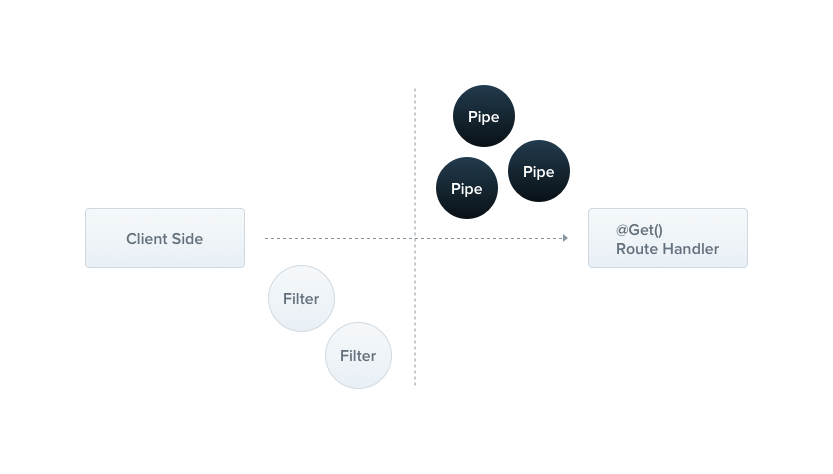
Pipe는 들어오는 요청의 데이터를 라우트 핸들러에 넘기기 전에 처리하고, 변환하고, 유효성을 검사하는 역할을 합니다. 예를 들어, 사용자가 양식을 제출할 때, Pipe는 사용자가 입력한 데이터가 올바른 형식인지, 올바른 값인지 확인하는 경우가 있습니다.
Pipe 역시 Nest에서 @Injectable 데코레이터가 붙여진 클래스로 구현되며, PipeTransform 인터페이스를 implements하여 사용됩니다.
Pipe는 일반적으로 다음 두 use cases를 갖습니다.
위 설명을 보니 어디서 많이 본 느낌이 나지 않나요? 맞습니다! 지난 포스팅 데이터 파트에서 다루었던 validation과 transformation을 Nest에서는 Pipe를 사용하여 처리해 주는 것입니다.
두 경우에 pipe는 controller가 route handler를 매핑할 때 사용하는 argument(인자)로써 동작합니다. Nest는 라우트 메서드가 호출되기 직전에 Pipe를 삽입하고, Pipe는 메서드에 전달되는 argument를 받아 이를 처리하는데요. 이때 모든 transformation 혹은 validation 검사 작업이 수행되고, 그 이후가 돼서야 route handler가 임의의 (잠재적으로) 변환된 인수를 받으면서 호출됩니다.
Nest에서는 바로 사용할 수 있는 여러 가지 기본 제공 Pipe가 있습니다. 물론 그러한 기본 제공 Pipe와 더불어 자신만의 커스텀 Pipe를 만들수도 있습니다.
한 가지 유의해야할 점은 Pipe가 exception 영역 내에서 실행된다는 것입니다. 즉, Pipe가 예외를 던지면 예외 계층(global exceptions filter 및 현재 컨텍스트에 적용되는 모든 exceptions filters)에서 처리됩니다.
위의 내용을 고려할 때, 파이프에서 예외가 발생하면 이후에 Controller 메서드가 실행되지 않는다는 것을 분명히 알 수 있고, 이는 시스템 경계(system boundary)에서 외부 소스로부터 애플리케이션으로 들어오는 데이터의 validation을 검사하는 모범적 테크닉 사례를 제공합니다.
Guard는 경비원과 같은 역할을 합니다. 들어오는 요청을 검사하고, 그 요청이 특정 조건을 충족하는지 결정하는 역할을 하죠. 예를 들어, 사용자가 로그인을 하지 않았다면, 특정 기능을 사용할 수 없도록 막는 기능을 만들어줍니다.
Guard도 NestJS에서는 @Injectable() 데코레이터가 붙은 클래스로 구현되며, 이는 CanActivate 인터페이스를 implements합니다.
Guard는 단일 책임을 갖습니다(SOLID의 S). 이 친구는 런타임 시 발생하는 특정 조건에 의존하여 request가 왔을 때 이 요청이 다음 단계인 route handler에 의해 처리될지 아닐지를 결정합니다(permissions, roles, ACLs 등).
이러한 행위는 종종 authorization(인증)에서 고려되는데요.
Authorization은 일반적으로 전통적인 Express에서 미들웨어에 의해 다루어졌습니다. token validation 및 request 객체에 속성을 부여하는 것과 같은 작업은 특정 route context(및 해당 메타데이터)와 강력하게 연결되어 있지 않기 때문에 미들웨어는 authorization을 위해 좋은 선택지입니다.
하지만 위에서 봤듯이 미들웨어는 본질적으로 쓰레기입니다. 미들웨어는 next() 함수가 호출된 후에 어느 handler가 실행될지를 모르기 때문이죠. 반면 Guards는 ExecutionContext(실행맥락) 인스턴스에 대한 접근권을 갖기에 다음에 무엇을 실행할지를 정확히 알고 있습니다.
Guard는 exception filter, pipes, 그리고 interceptors와 마찬가지로 request/response 주기 동안 정확한 지점에 처리 로직을 삽입할 수 있도록 설계되었으며, 이를 선언적으로 수행할 수 있습니다. 이를 통해 더욱 코드를 간결하고 선언적으로 유지하는 데 도움이 됩니다.
Guard는 모든 미들웨어가 실행 된 이후에 실행되고, interceptor나 pipe보다는 앞서 실행됩니다.
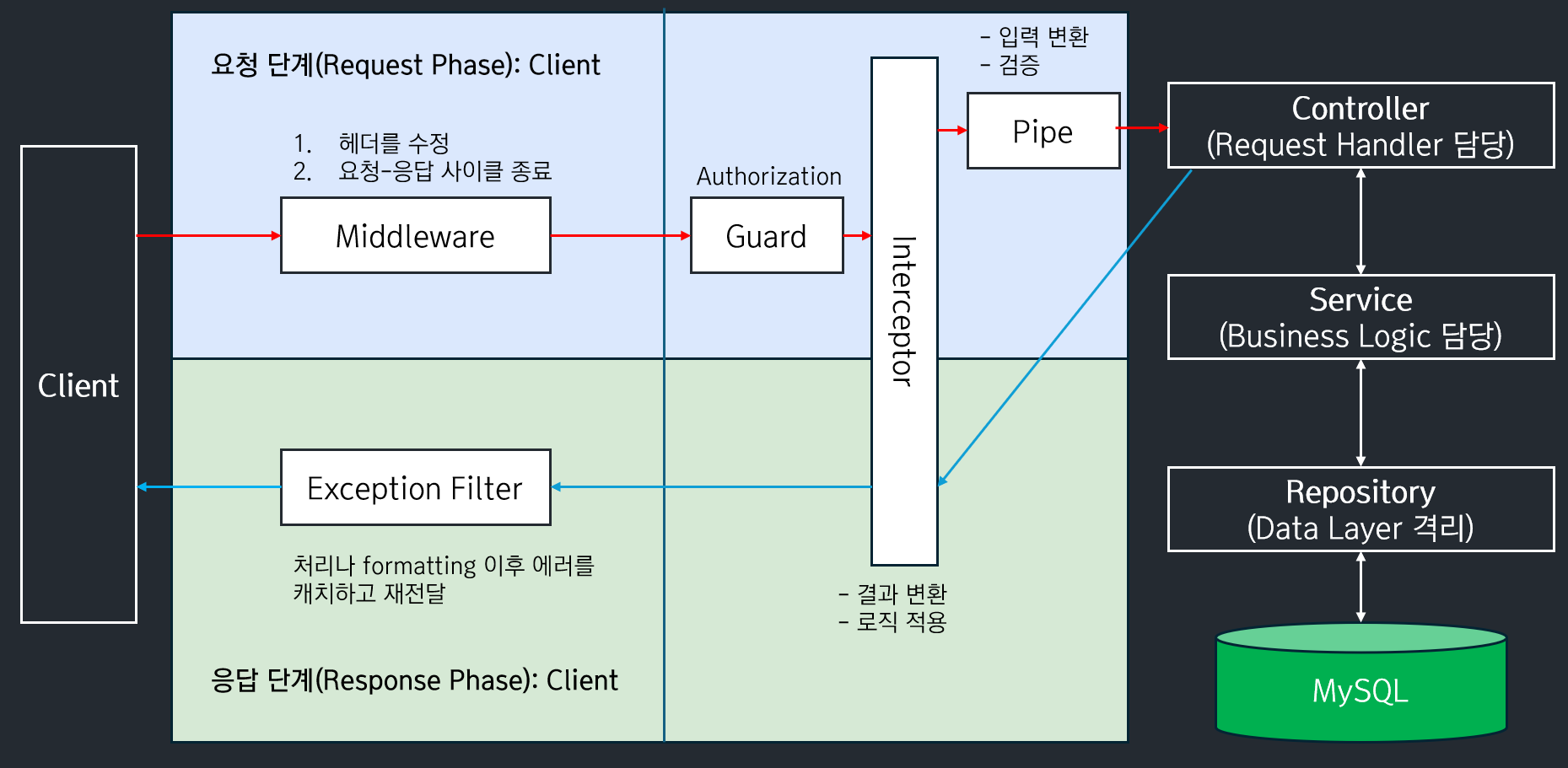
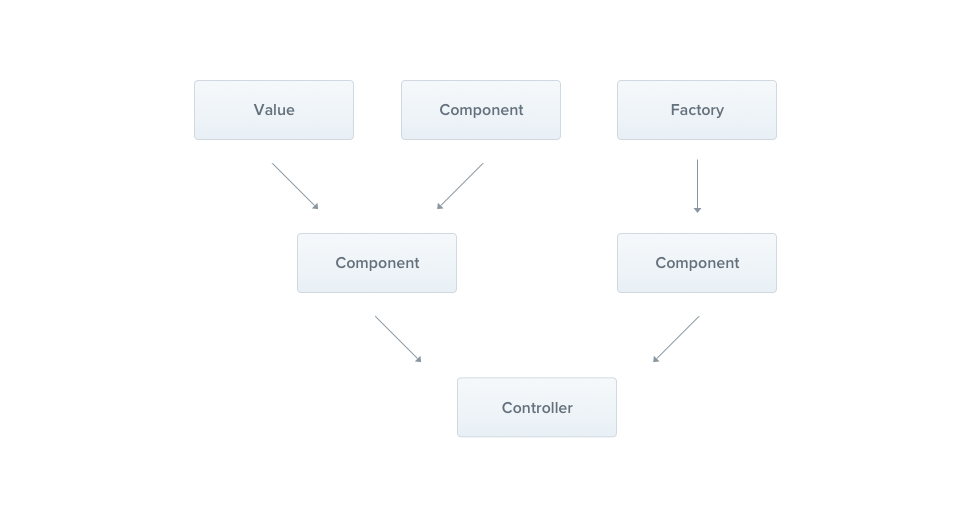
위의 개념들의 흐름을 도식화해 보면 위의 이미지와 같습니다.
Factory라는 개념은 원래 백엔드 디자인 패턴에서도 쓰이는 개념으로 NestJS에서는 이 개념을 이용한 커스텀 provider의 일부로 사용할 수 있도록 마련한 기법입니다.
Factory 패턴은 객체 지향 프로그래밍에서 객체 생성 로직을 캡슐화하는 디자인 패턴 중 하나입니다.
DI 개념으로 인해 상위 클래스에서 하위 클래스의 인스턴스를 생성하기 위한 인터페이스가 제공되는데 생성할 인스턴스의 유형을 변경할 수 있도록 하는 생성 패턴입니다. 이 패턴은 느슨한 결합을 만들어주고 객체 생성의 유연성을 높여줍니다.
프로젝트가 진행됨에 따라 인스턴스화되는 클래스를 동적으로 변경하거나 기존 코드를 수정하지 않고 새로운 클래스를 도입해야 하는 경우가 있습니다. Factory 디자인 패턴은 객체 생성 로직을 캡슐화하여 클라이언트와 실제 객체 생성 사이의 명확한 분리를 제공함으로써 이러한 문제를 해결합니다.
그렇기 때문에 NestJS에서 사용되는 커스텀 provider 중 useFactory는 Factory 패턴의 원리를 활용한 것이라고 볼 수 있지만 NestJS에서는 해당 구문을 조금 더 넓은 범위에서 사용합니다.
NestJS에서 팩토리는 특히 의존성 주입과 관련하여 중요한 역할을 하는 특정 구문을 의미합니다(useFactory).
팩토리를 사용하는 경우는 의존성을 동적으로 생성하거나 복잡한 초기화 로직이 필요한 경우입니다. 팩토리는 클래스의 인스턴스를 생성하고, 필요에 따라 해당 인스턴스에 특정 로직을 적용한 후 이를 반환합니다. 이렇게 함으로써 생성 과정의 복잡성을 호출자로부터 숨길 수 있습니다.
즉, Nest에서 Class(일반 provider)와 Factory(custom provider)는 모두 컴포넌트를 정의하는 방법 중 하나입니다.
클래스는 한 번 정의되면 프로그램 전체에서 공유되며, 필요한 곳에서 인스턴스화 됩니다. 또한 컴포넌트가 필요한 모든 곳에서 동일한 인스턴스를 공유해야 하는 경우에 사용되죠(Singleton 객체). 생성자 인자(constructor argument)를 통해 의존성을 주입받고 생성자에서 인스턴스화되는 서비스에 대한 참조를 쉽게 얻을 수 있으며, 코드의 가독성과 유지관리가 용이합니다.
Factory는 클래스와는 다르게 컴포넌트를 동적으로 생성할 수 있습니다. 팩토리는 컴포넌트가 필요한 시점에 호출되어 해당 컴포넌트를 생성하고 반환할 수 있습니다. 이렇게 생성된 컴포넌트는 해당 컴포넌트를 사용하는 모듈이나 컨트롤러 등에서 사용될 수 있습니다.
그렇기에 동적으로 컴포넌트를 생성해야 하는 경우 사용되며, 그 예로 DB 연결 등의 리소스가 필요한 경우 팩토리를 사용하여 컴포넌트를 생성하는 경우, 컨트롤러에서 해당 컴포넌트를 사용하는 경우 등이 있습니다.(데이터베이스 연결 설정을 동적으로 구성하는 Factory)
즉, 생성자 대신 팩토리 메서드를 사용해 객체를 생성합니다. 팩토리를 사용하면 생성 로직을 더 잘 제어할 수 있으며, 클래스 내부에서 작동하지 않는 기능을 제공할 수 있습니다.
Nest에서는 useFactory 구문을 사용하면 provider를 동적으로 생성할 수 있습니다. 실제 provider 리스트에는 factory 함수에서 반환된 값으로 제공됩니다. useFactory는 주로 모듈 설정에서 사용되며, 의존성 주입 시 특정 조건이나 구성에 따라 다른 인스턴스를 제공할 수 있습니다.
factory 함수는 필요에 따라 단순하거나 복잡할 수 있는데요. 단순한 factory는 다른 provider에 의존하지 않을 수 있지만 복잡한 factory는 결과를 계산하는 데 필요한 다른 provider를 자체적으로 주입할 수 있습니다. 후자의 경우, factory provider 구문에는 한 쌍의 관련된 메커니즘이 존재합니다.
팩토리를 사용하면 생성 로직을 더욱 세부적으로 제어할 수 있으므로 필요한 경우에 적절하게 사용하는 것이 좋습니다.
그래서 custom provider와 같은 고급 기능을 구현해야 하는 경우 팩토리를 사용하는 것이 좋은데, 그것이 아닌 일반적인 경우에는 그냥 클래스를 의존성 주입과 함께 사용하는 것이 더 효율적이라고 합니다.
일반 클래스에서 객체를 동적으로 생성하려 하는 경우, 예를 들어 클래스 내에서 조건문이나 설정 값을 기반으로 다른 객체를 생성하는 경우에 클래스가 여러 역할을 하게 되기 때문에 단일 책임 원칙을 위반하고, 객체 생성 로직이 클래스에 굉장히 강력하게 결합되어 있기 때문에 유지보수와 확장성에 어려움을 줄 수 있게됩니다.
따라서 팩토리 패턴은 의존성 주입의 한 형태로 볼 수 있으며, 객체 생성 과정에 더 많은 제어를 필요로 하는 상황에서 사용됩니다.
NestJS의 'useFactory' & 일반적인 Factory
두 개념 모두 객체 생성의 유연성과 코드의 관리 용이성을 향상시키는 데 기여하지만, 사용되는 상황과 방식, 범위가 다르다는 점을 유의해야 합니다.
한 문장 정리: Factory는 객체를 생성하는 과정이 단순하지 않고 여러 단계의 설정이나 초기화가 필요한 경우, 이러한 로직을 팩토리 안에 넣어 관리할 수 있으며, [실행 환경, 설정 또는 입력 값]에 따라 다른 종류의 객체를 생성하는 경우(조건적 의존성)에도 사용하며, 마지막으로 NestJS의 의존성 주입 시스템과 결합되어 DI 컨테이너에 객체를 동적으로 제공하는 경우에도 사용됩니다.
앞서서 계속 나왔지만 Nest는 데코레이터라는 언어 기능을 중심으로 구축되었습니다. 데코레이터는 일반적으로 사용되는 많은 프로그래밍 언어에서 잘 알려진 개념이지만 JavaScript 세계에서는 아직 비교적 새로운 개념입니다.
데코레이터 앞에 '@' 문자를 붙이고 데코레이션하려는 항목의 맨 위에 배치하여 적용합니다. 그로인해 클래스, 메서드 또는 프로퍼티에 대해 정의할 수 있게 됩니다.

우리가 아는 데코레이션처럼 이 Decorator도 결국 무언가 치장을하고 꾸며준다는 의미를 갖고 있게 됩니다. 그 무언가가 NestJS에서는 클래스, 메서드, 프로퍼티가 되는 것이죠. 이러한것들의 내부를 수정하지 않고 기능에 변화를 주는 것은 굉장히 강력한 기능입니다.
ES2016 데코레이터는 함수를 반환하는 표현식으로 target, name, property descriptor를 데코레이터의 argument로 사용할 수 있습니다.
추가적으로 소프트웨어 개발 프로세스에서 알아두면 좋은 개념들에 대해 소개를 해드리겠습니다.
DDD란 비지니스 도메인 별로 나누어 설계하는 방식을 말합니다.
기존의 애플리케이션 설계가 비지니스 Domain에 대한 이해가 부족한 상태에서 설계 및 개발되었다는 반성에서 출발하게 된 디자인 패턴입니다. DDD에서는 기존의 현업에서 IT로의 일방향 소통구조로부터 탈피하여 현업과 IT의 쌍방향 커뮤니케이션을 매우 중요시 합니다.
DDD의 핵심 목표는 Loosely coupling, High cohesion입니다. 이것들의 의미는 애플리케이션 또는 그 안의 모듈간 의존성은 최소화하고, 응집성은 최대화하는 것을 말하죠.
테스트는 프로그램이 의도한대로 작동하는지 보여주고 사용하기 전에 프로그램 결함을 발견하는 것을 목적으로 합니다.
보통 인공적으로 만든 데이터(mocking data)를 사용하여 프로그램을 실행하게 됩니다.
첫 번째 목표는 검증 테스트입니다.
두 번째 목표는 결함 테스트입니다.
Testing은 세 가지 단계로 구성될 수 있습니다. Development testing(개발 테스팅), Release testing(배포 테스팅), User testing(유저 테스팅)
이 중 우리가 주로 관심을 갖게될 부분은 development testing과 release testing입니다.
development testing에는 다시 또 세 가지의 testing 방식이 존재하는데요. 그 종류는 다음과 같습니다:
unit testing은 개별 구성 요소를 격리하여 테스트하는 과정이며, 결함 테스트 과정의 일종입니다.
Unit은 다음과 같은 것들일 수 있습니다.
통합 테스트는 시스템의 여러 단위 또는 구성 요소 간의 상호 작용을 검증하는 테스트 유형입니다. 서로 다른 단위가 함께 동작하면서 흐름에 맞게 잘 동작하고, 예상된 결과를 생성하는지를 테스트합니다.
E2E 테스트는 시스템의 시작부터 끝까지 전체 흐름을 확인하는 테스트 유형입니다. 시스템이 예상대로 작동하고 사용자의 요구사항을 충족하는지 확인하기 위해 모든 구성 요소와 해당 구성 요소의 상호 작용을 테스트하는 것이 포함됩니다.
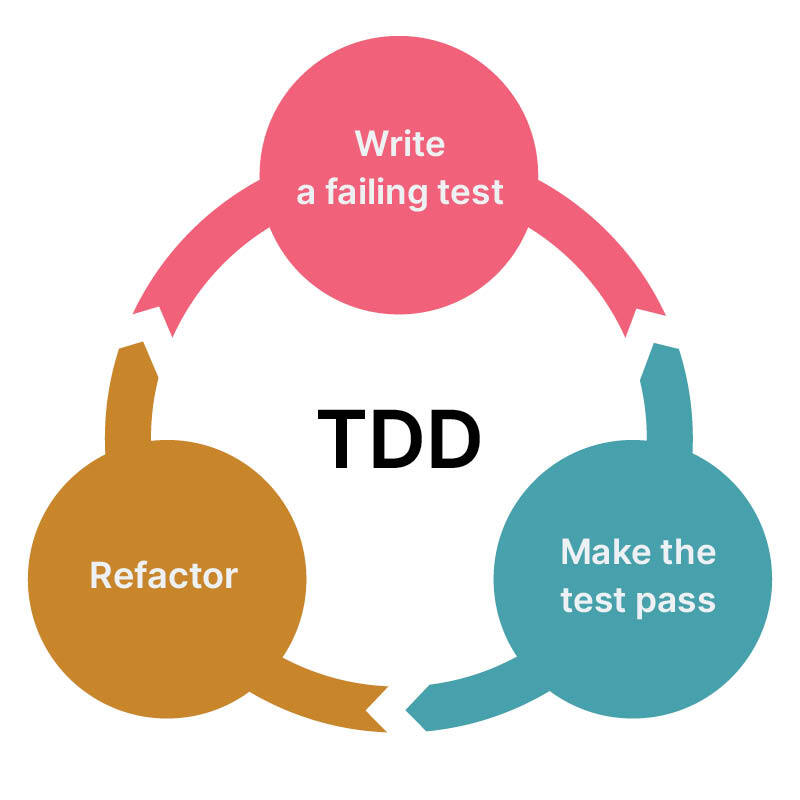
TDD는 테스트와 코드 개발을 서로 분리하여 진행하는 프로그램 개발 방식입니다.
테스트는 코드보다 먼저 작성되며, 테스트를 '통과'하는 것이 개발의 핵심 동인이 됩니다. 코드를 점진적으로 개발할 때 해당 incremental(개발 단위)에 대한 테스트도 함께 진행합니다. 개발한 코드가 테스트를 통과할 때까지는 다음 단계로 넘어가지 않으며 테스트가 통과하면 테스트의 범위를 다시 넓혀가며 해당 테스트를 통과하도록 개발하는 것을 반복하는 과정을 거칩니다.
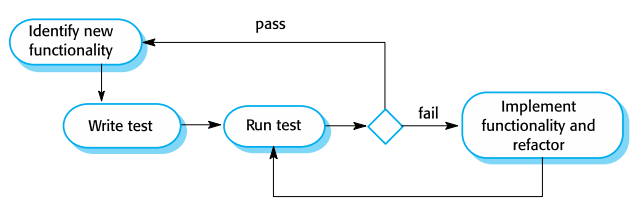
TDD는 다음 과정으로 진행됩니다.
여기서 중요한 점은 의도적으로 실패하는 테스트를 작성한다는 것인데요. 일례로 없는 함수를 불러와서는 '해당 함수의 반환값이 이러이러할 것이다'라고 테스트를 먼저 작성하면, 테스트를 돌렸을 때는 당연히 함수가 존재하지도 않고 어떠한 값도 반환할 수 없기에 테스트가 실패를 할 것입니다. 그치만 이렇게 되면 저희가 다음에 해야 할 일은 너무나 명확하게 정해지게 됩니다.
그 구현되지 않은 함수를 구현하는 일 말이죠.
TDD를 함으로써 얻을 수 있는 이점은 다음과 같습니다.
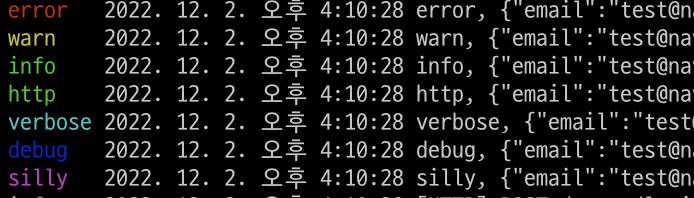
Logger는 시스템 운영에 대한 기록인 로그(log)를 남기는 툴입니다. 로그를 잘 남기게 되면 오류가 발생했을 때, 디버깅이 용이해지고, 시스템 에러가 어떤 부분에서 발생했는지를 추적해서 확인할 수 있게 됩니다.
Nest에는 내장된 텍스트 기반 logger를 갖고 있는데. 이는 애플리케이션 bootstraping(부팅)과 몇몇 다른 환경(예외 발생을 보여주는) 에서 사용됩니다.
이 기능은 @nestjs/common 패키지의 Logger 클래스를 통해 제공되며 다음과 같은 기능을 사용하여 로깅 시스템을 완전히 제어할 수 있게 됩니다.
cross-origin에서 origin, 즉 출처가 의미하는 것은 무엇일까요?

우리는 앞서 서버의 위치를 의미하는 https://www.naver.com 과 같은 URL들은 마치 하나의 문자열처럼 보여도 사실은 여러 구성 요소로 이루어져있다는 것을 확인했습니다.
이때, 출처란 Protocol과 Host, 그리고 위에는 생략되었지만 :80, :443과 같은 포트 번호까지 모두 합친 것을 의미합니다.
CORS에 대해 알기 위해선 SOP, 동일 출처 정책에 대해서 먼저 알 필요가 있습니다.
SOP는 JavaScript 엔진 표준 스펙의 보안 규칙으로, 하나의 출처(Origin)에서 로드된 리소스(문서, 스크립트 등)가 Host, Protocol, Port가 일치하지 않는 리소스는 상호작용 하지 못하도록 요청 발생을 제한하고, 오로지 동일 출처에서만 접근이 가능하도록 만든 정책을 의미합니다.
CORS는 SOP 규칙을 벗어난 리소스가 다른 도메인으로부터 요청되는 것을 허용하는 메커니즘입니다.

웹 페이지를 돌아다니다 보면 f12를 눌러 개발자 도구를 켰을 때, 크롬 브라우저에서는 보안적 이유로 cross-origin HTTP 요청들을 제한하는 것을 심심찮게 보실 수 있습니다.
만약 브라우저가 서버에게 리소스 요청 여부를 물어봤는데 서버가 동의한다면 브라우저에서는 해당 요청을 막지 않지만, 동의하지 않는다면 브라우저에서 그 요청을 거절합니다.
이러한 허락을 구하고 거절하는 메커니즘을 HTTP-header를 통해서 제어할 수 있습니다. 즉, CORS는 브라우저에서 cross-origin 요청을 안전하게 할 수 있도록 헤더를 통해 그 허락 여부를 결정하는 메커니즘입니다.
CORS가 필요한 이유는 만약 CORS가 없이 모든 곳에서 데이터를 요청할 수 있게 되면, 다른 사이트에서 원래 사이트를 그대로 흉내낼 수 있기 때문입니다. 예를 들어, 어떤 사이트와 완전히 동일하게 동작하도록 해서 그 사이트를 이용하는 사용자가 똑같이 로그인도 할 수 있게 하고, 그 로그인을 했던 세션 정보도 탈취하여 악의적으로 정보를 추출해내거나 다른 사람의 정보를 입력하는 등 공격을 할 수 있다면 굉장히 위험할 것입니다.
두 개의 출처가 같은지 다른지는 위에서 말했듯 딱 3가지만 보면 됩니다. Scheme, Host, Port가 같으면 두 개의 출처가 같다고 할 수 있습니다.
1. Simple request인 경우
바로 서버에게 본 요청을 날려 서버가 이에 대한 응답 헤더에 'Access-Control-Allow-Origin' 값을 포함하여 보내주면, 그 때 브라우저가 CORS 정책 위반 여부를 검사하는 방식입니다.
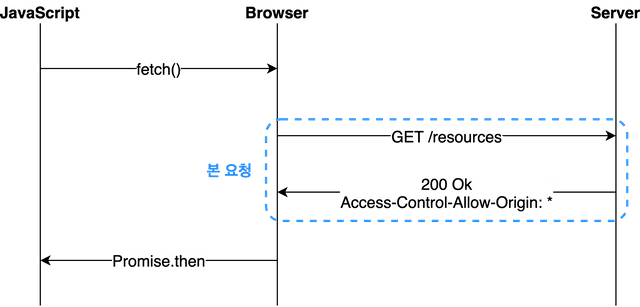
여기서 Simple Request가 되기 위한 조건은 다음과 같습니다.
이러한 요청은 추가적으로 확인 과정없이 바로 본 요청이 보내집니다.
2. Preflight 요청일 경우
Preflight 요청은 보통 simple requests가 아닌 모든 cross-origin 요청들이 preflight 요청으로 보내게 됩니다.
이러한 경우는 일반적으로 우리가 웹 애플리케이션을 개발할 때 가장 자주 마주칠 수 있는 시나리오 입니다.
이 시나리오에 해당하는 상황의 경우 브라우저는 요청을 한 번에 보내지 않고 예비 요청과 본 요청으로 나누어서 서버로 전송합니다.
이때 브라우저가 본 요청을 보내기 전에 보내는 예비 요청을 Preflight라고 부르는 것이며, 이 예비 요청에는 HTTP 메서드 중 OPTIONS 메소드가 사용됩니다.(접두사 pre에서 그 의미를 유추할 수 있을 것입니다.)
이 과정을 플로우 차트로 나타내보면 다음과 같습니다.
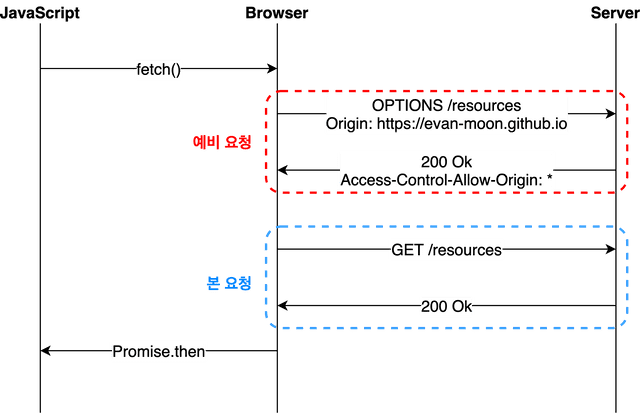
fetch와 같은 API를 사용해서 다른 도메인으로부터 브라우저에게 리소스를 받아오라는 명령을 내리면 브라우저는 서버에게 예비 요청을 먼저 보낸다음, 서버가 이 예비 요청에 대한 응답으로써 현재 본인 서버에서 어떤 리소스들을 허용하고 있고 어떤 것들을 금지하고 있는지에 대한 정보를 응답 헤더에 담아서 브라우저에게 다시 보내주게 됩니다.
이후 브라우저는 자신이 보낸 예비 요청의 내용과 서버가 응답 헤더에 담아준 허용 정책을 비교한 후에 '이 요청을 보내도 되겠다' 라고 판단되는 경우에만 같은 엔드포인트로 이번엔 본 요청을 보내게 됩니다. 이후 서버가 이 본 요청에 대한 응답을 하면 이제서야 브라우저는 최종적으로 이 응답 데이터를 자바스크립트에게 넘겨주게 되는 것입니다.
실제로 http://cdragon.tistory.com/rss에 예비 요청을 보내보면 다음과 같은 응답을 보내주는 것을 확인할 수 있습니다.
OPTIONS https://cdragon.tistory.com/rss 200 OK
Access-Control-Allow-Origin: https://cdragon.tistory.com
Content-Encoding: gzip
Content-Length: 699
Content-Type: text/xml; charset=utf-8
Date: Sun, 24 May 2020 11:52:33 GMT
P3P: CP='ALL DSP COR MON LAW OUR LEG DEL'
Server: Apache
Vary: Accept-Encoding
X-UA-Compatible: IE=Edge여기서 눈여겨 봐야할 점은 응답 헤더에 포함된 'Access-Control-Allow-Origin'에 대한 부분인데, 이것의 의미는 티스토리 측 서버가 이 리소스에 접근이 가능한 출처는 오직 'https://cdragon.tistory.com' 뿐이라고 브라우저에게 이야기 해주는 것이고, 만약 제가 이 요청을 보낸 출처가 서버가 허용해준 출처와는 다른 출처인 경우에 브라우저는 이 요청이 CORS 정책을 위반했다고 판단하고 에러를 출력하게 됩니다.
정리하자면 웹사이트에서 다른 출처의 리소스를 가져오는 기능이 없다면 CORS 설정을 할 필요가 없습니다. CORS는 주로 웹 브라우저에서 실행되는 클라이언트 사이드 코드가 다른 출처의 리소스에 접근할 때는 이를 반드시 설정해주는 과정이 필요합니다. (그래야 브라우저에서 리소스를 활용해 화면을 구성할 수 있습니다.)
CI(Continuous Integration)는 지속적인 통합이라는 뜻으로 애플리케이션의 새로운 코드 변경 사항이 정기적으로 빌드 빛 테스트 되어 공유 레포지토리에 통합하는 것을 의미합니다.
지속적으로 서비스해야 하는 애플리케이션이나 현재 진행 중인 프로젝트는 기능을 추가할 때마다 git과 같은 형상 관리 저장소에 commit 등을 날려 레파지토리에 버전 업데이트를 하게되는데요. 다수의 개발자들이 한 팀으로 작업하는 경우, 이 공유 레파지토리에는 어쩔 수 없이 수많은 commit들이 쌓이게 될 것입니다.
그럴 때마다 기능별로 빌드/테스트/병합까지 하려면 상당히 번거로운데, 이런 상황에서 자동화된 빌드와 테스트는 원천 소스코드의 충돌 등을 방어하는 이점을 제공할 수 있습니다.
CD(Continuous Deployment)는 지속적인 배포라는 뜻으로 공유 레파지토리에 자동으로 release하는 것을 의미합니다. 이는 production 레벨까지 자동으로 deploy 하는 것을 의미합니다.
앞서 CI가 새로운 소스코드의 빌드, 테스트, 병합까지를 의미했다면 CD는 개발자의 변경 사항들이 레파지토리 울타리 밖의 실제 고객이 사용하는 production 레벨까지 릴리즈 되게끔 하는 것을 의미합니다.
이는 서비스의 개발팀과 비지니스(영업, CS팀 등) 간의 커뮤니케이션 부족 문제를 해결하여 배포에 이르는 과정을 간소화시켜주는 이점을 제공합니다.
실제 서비스에서 회원을 인증하는 과정은 거의 필수라고 할 수 있습니다. 이러한 인증 및 인가에는 어떤 방식들이 사용되는지 알아보겠습니다.
먼저 인증과 인가의 차이는 다음과 같습니다.
인증 & 인가가 필요한 이유
웹 애플리케이션은 일반적으로 서버-클라이언트 모델로 HTTP 프로토콜을 이용하여 통신한다고 앞에서 배웠습니다. 이러한 통신에는 Connectionless, Stateless 라는 특성이 존재하는데요.
두 특성은 불편해보이지만 모두 서버의 비용과 부담을 줄이기 위해 사용되는 방식입니다.
이러한 방식 속에서 사용자가 로그인을 통해 인증을 거쳐도 이후 요청에 대해서는 상태가 저장되지 않기에 다시 까먹는 상황이 벌어질 수도 있습니다. 그렇다는 말은 최초 로그인 이후에도 매 요청마다 반복적으로 ID, PW를 입력하여 페이지 접근 인가를 받아야 한다는 의미가 됩니다.
하지만 실제로 우리가 사이트를 이용할 때는 단 한 번의 로그인으로 여러 회원 기능을 이용할 수가 있습니다. 이것이 가능하기 위해서 여기에는 세 가지 기술들이 일반적으로 사용될 수 있습니다.
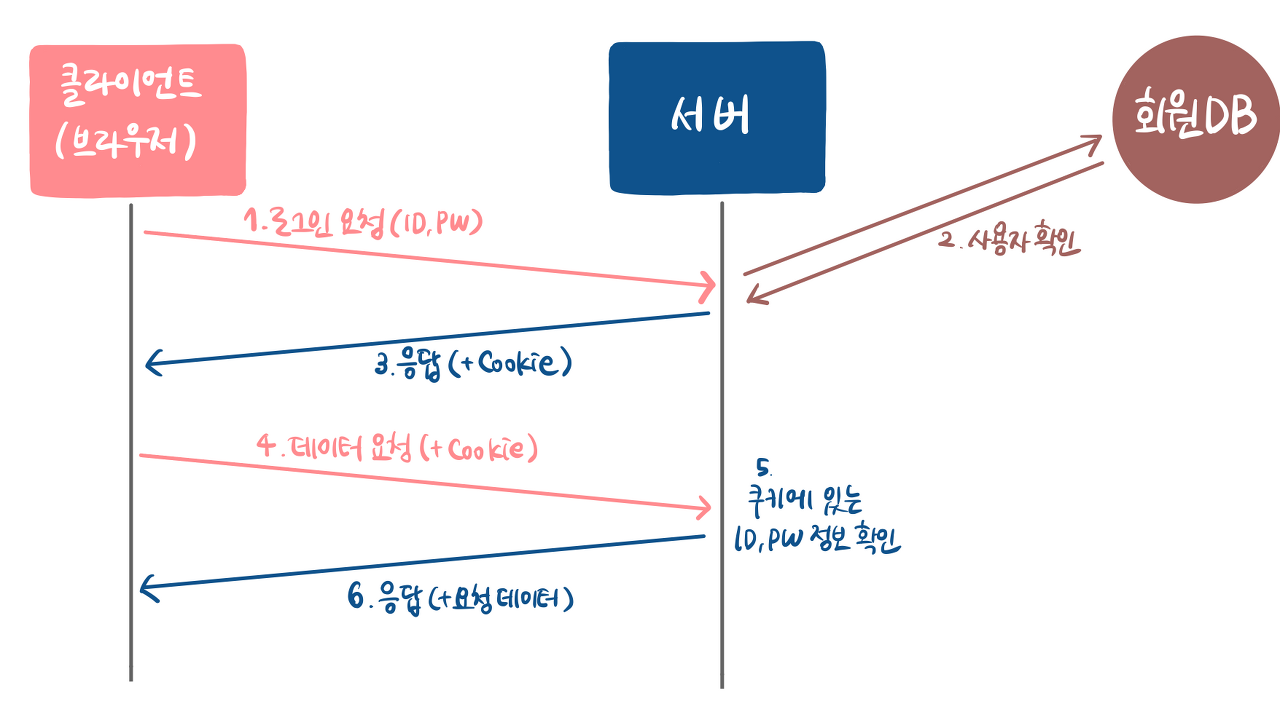
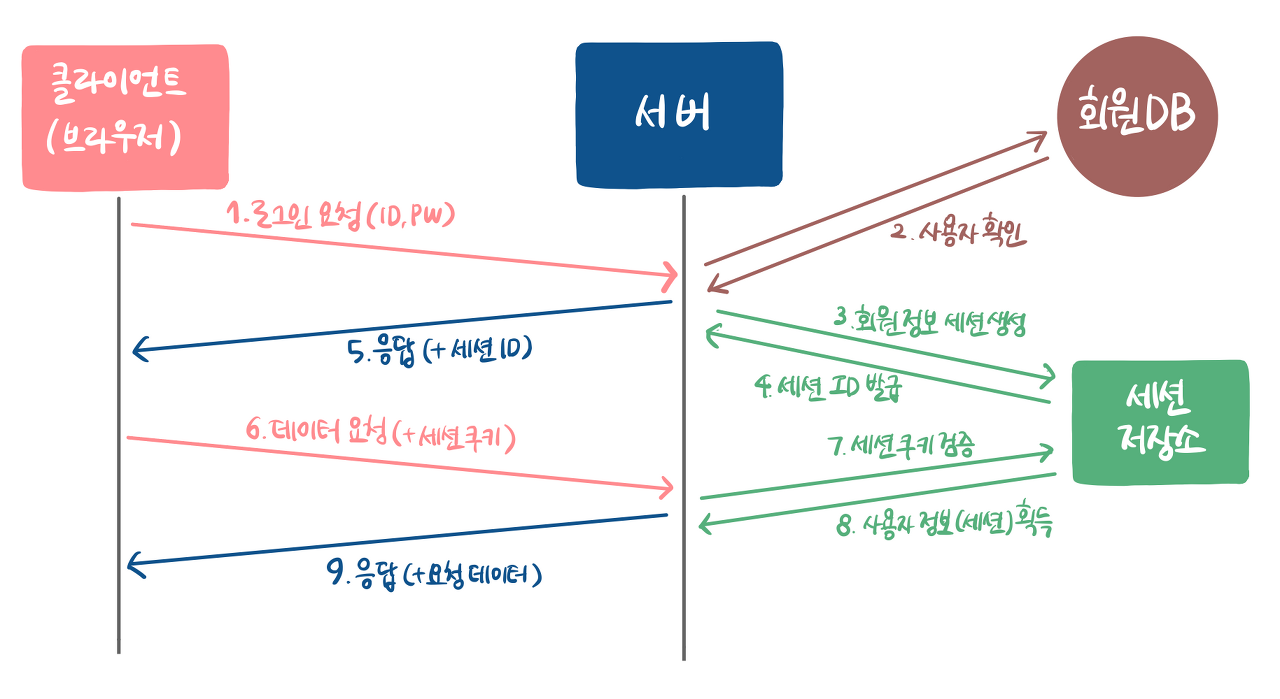
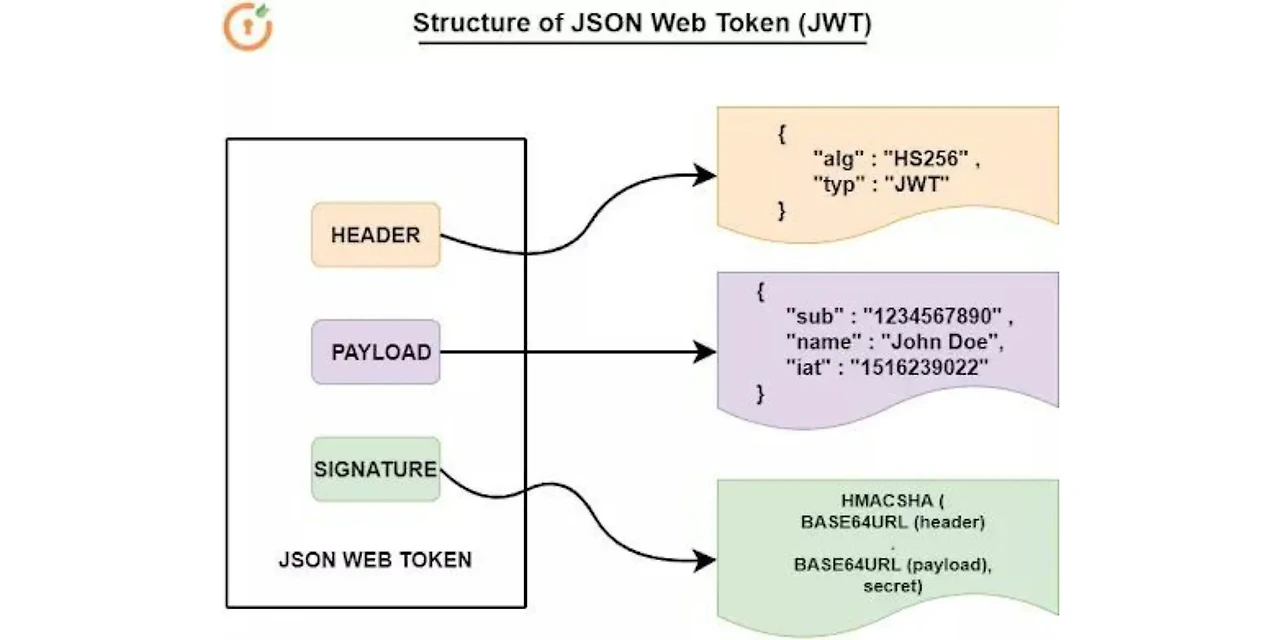
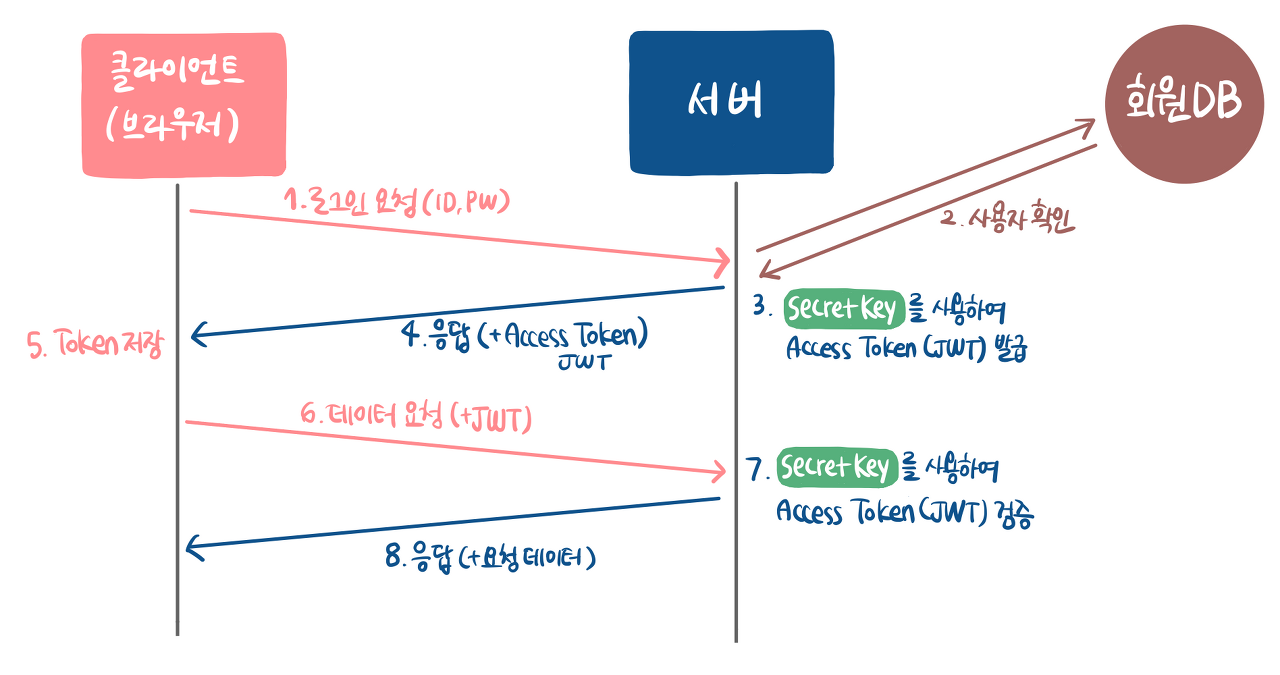
JWT의 동작 방식은 다음과 같습니다.
전체적인 흐름을 봤을 때 Session 방식과 JWT 방식이 크게 차이가 없어보이지만 실제 사용함에 있어서 큰 차이가 존재합니다.
| [NestJS] NestJS CLI로 REST API를 사용한 CRUD 기능 만들기(5분버전 vs. 심화버전) with TypeORM & MySQL (0) | 2024.01.24 |
|---|---|
| [NestJS] NestJS에서 Swagger 사용법 (feat. API Documentation) (2) | 2024.01.23 |
| [NestJS] NestJS 시작 (설치 & 구성요소 맛보기) (3) | 2024.01.22 |
| [NestJS] NestJS를 위한 선수지식 Node.js & Express.js 이해 (feat. Logging, 폴더 구조) (0) | 2024.01.21 |
| [NestJS] NestJS 시작 전에 알아야 하는 백엔드 지식 (0) | 2024.01.10 |
소중한 공감 감사합니다