새소식
반응형
NestJS는 기본적으로 NodeJS 기반에서 동작합니다. 그렇기에 자연스레 NodeJS의 동작 방식에 큰 영향을 받았는데요.
NestJS에서는 Express.js를 기본적으로 사용하기 때문에 이번 포스팅에서는 Node.js와 Express.js에 대해서 알아보는 시간을 가져보도록 하겠습니다.

모든 프로그래밍 플랫폼은 각자 자신들만의 철학과 각종 커뮤니티에서 관례로 따르는 일련의 원칙들과 지침을 제시하고 있습니다. Node.js에서는 이러한 원칙들 중 일부가 제작자인 Ryan Dahl에 의해서 직접 만들어졌으며, 일부는 코어모듈에 기여한 사람들, 커뮤니티에서의 카리스마 있는 인물들, JavaScript의 추세 등으로부터 생겨났습니다.
NodeJS에서는 다양한 기술과 그들만의 기준을 세운 것들이 몇가지 존재합니다.
Node.js는 확장가능하고 높은 성능을 보이는 애플리케이션을 구축하는 데 굉장히 강력한 플랫폼입니다. 특히 비동기(asynchronous) 프로그래밍은 Node.js의 핵심 기능인데, 이는 대용량의 요청이 동시다발적으로 들어왔을 때 개발자가 그것을 해결할 수 있는 non-blocking 코드를 작성하도록 해줍니다.
Node.js를 이해하기 위해 정리해야 하는 개념들인 call stack, callback queue, event loop 등에 대해서 알아봅시다.
콜 스택(Call Stack)은 함수 또는 메소드의 실행을 추적하기 위해 프로그래밍 언어에 의해 사용되는 메커니즘입니다.
어떤 함수가 호출되면, 해당 함수는 콜 스택의 top 부분에 추가되고 함수가 반환되면 그 함수는 해당 스택으로부터 제거됩니다. 콜 스택은 프로그램이 올바른 순서로 실행되고 각 함수는 다음에 실행될 함수 이전에 완료되어야 함을 보장하기 때문에 굉장히 중요합니다.
Node.js에서 콜 스택은 동기 함수(synchronous function)의 실행을 추적하는 데 사용됩니다.
어떤 함수가 동기적으로 호출되면, 그 함수는 스택의 top에 추가되고 해당 함수가 반환되면 스택으로부터 제거된다고 했었죠? 이는 어떤 함수가 만약 blocking 중이거나 완료하는데 오랜시간이 걸린다면 그 함수가 반환될 때까지 다른 함수들의 실행을 막게됨(block)을 의미합니다.
콜 스택을 이해하는 것은 우리가 stack overflow나 무한 루프와 같은 이슈를 확인하고 고치는 것을 도와줄 수 있기 때문에 중요합니다. 또한 콜 스택에 대해 잘 알고 있으면 코드 실행 순서가 성능에 어떻게 영향을 주고 그것을 어떻게 최적화 시킬 수 있을지 이해하는 데에 도움이 되기도 합니다.
콜백 함수(Callback Function)는 또 다른 함수의 인자로서 넘겨지는 함수입니다. 이는 첫 번째 함수(first function)가 완료된 이후에 실행됩니다. 즉, 첫 번째 함수가 완료될 때 두 번째 함수(콜백 함수)를 다시 호출("calls back")하는 것을 의미합니다.
콜백 함수는 Node.js에서 비동기 프로그래밍의 필수적인 요소입니다. 콜백 함수는 다수의 요청을 동시에 다룰 수 있는 non-blocking 코드를 작성할 수 있도록 해줍니다. 비동기 함수가 호출되면, 그 함수는 프로그램의 실행을 가로막지 않습니다(non-blocking). 가로막지 않는 대신, 함수가 즉시 반환되어 콜스택으로부터 제거돼 다음 줄의 코드를 이어갈 수 있게 됩니다. 그리고 비동기 작업이 완료되면, 콜백 함수가 실행을 기다리는 상태가 됩니다.
Node.js에서 사용되는 콜백 함수에 대해 흔히 사용되는 예제는 파일이나 HTTP 요청과 같은 I/O 작업을 다룰 때입니다. 그러한 작업들은 완료되기까지 오랜 시간이 걸릴 수 있기 때문에 비동기적으로 실행되는 것이고, 그 작업이 완료될 때 실행 될 함수로 콜백함수가 전달되는 것입니다.
콜백 함수는 inline 혹은 standalone 함수로 정의될 수 있습니다. Inline 콜백 함수는 호출을 한 함수에게 인자로 전달되는 익명 함수(anonymous function)로 정의됩니다. Standaone 콜백 함수는 따로 선언 및 정의되어 호출을 한 함수에게 해당하는 함수의 이름이 인수로 전달됩니다.
프로그램이 작동하다보면 비동기 작업 도중에 에러가 발생할 수 있기 때문에, Node.js에서 콜백 함수를 사용할 때는 에러를 적절히 다루는 것이 굉장히 중요한 일입니다.
에러를 다루기 위해 자주 쓰이는 패턴 중 하나는 그 콜백함수에게 첫번째 인자로 에러 객체를 넘겨주고 두 번째 인자로 성공했을 경우의 작업의 결과를 포함시키는 방식입니다.
Node.js에서는 비동기 작업이 종료될 때, 그 함수의 콜백 함수는 즉시 실행되는 것이 아닙니다. 즉시 실행되지 않는 대신, 그 콜백 함수는 콜백 큐(callback queue)라고 하는 대기열(queue)에 놓여지게 됩니다.
따라서 콜백 큐는 실행되기를 기다리는 중인 모든 완료된 비동기 함수들의 콜백 함수를 가지고 있는 큐입니다.
콜백 큐도 결국엔 큐(Queue) 자료구조이기 때문에 선입선출(FIFO) 구조를 갖고 있습니다. 이는 event loop가 큐에서 한 콜백 함수를 집을 때, 큐에 가장 먼저 추가되었던 콜백 함수가 가장 먼저 골라질 콜백 함수가 된다는 것을 의미합니다.
event loop는 콜 스택과 콜백 큐를 계속 주시하고 있다가, 콜 스택이 비었을 때 콜백 큐에서 다음 콜백함수를 골라서 해당 함수를 콜 스택에 집어 넣는 역할을 합니다.
콜백 큐는 오로지 완료된 비동기 작업의 콜백 함수만을 가진다는 점을 명심해야 합니다. 만약 비동기 작업이 완료되지 않았으면, 해당 작업의 콜백 함수는 콜백 큐에 추가되지 않을 것입니다. 대신, 아직 완료되지 않은 비동기 작업의 콜백 함수는 그 함수의 비동기 작업이 완료되고 나서 큐에 추가될 수 있을 때까지 백그라운드에서 대기하고 있습니다.
콜백 함수를 이해하는 것은 Node.js에서 효율적이고 확장가능한 코드를 작성할 수 있기 때문에 중요합니다. 콜백 함수와 콜백 큐를 사용함으로써 event loop를 blocking 하는 것을 막을 수 있고 코드가 동시에 여러 요청을 다룰 수 있음을 보장할 수 있습니다. 하지만 '콜백 지옥(callback hell)'이나 '다루기 힘든 예외(unexpected exception)'와 같은 이슈를 막기 위해선 콜백을 적절하게 사용하고 에러를 적절히 다룰 수 있어야합니다.
Event loop는 Node.js에서 사용되는 기본적인 개념인데요. 이 친구 덕에 원활한 비동기 프로그래밍이 가능해집니다. 계속 실행 중인 프로세스는 콜 스택과 콜백 큐를 모니터하며, 콜 스택이 비었을 때 본인의 업무를 수행합니다.
Node.js 애플리케이션이 시작할 때, event loop도 같이 생성되고 동시에 실행 중인 상태가 됩니다. event loop는 소수의 코어 컴포넌트만을 사용하여 작동합니다.
프로그램에서 어떠한 함수가 호출될 때, 그 함수는 콜 스택의 top 부분에 추가됩니다. 함수가 반환될 때는 콜 스택으로부터 제거됩니다. event loop는 그 콜 스택을 계속해서 감시하다가, 그 스택이 비었을 때 콜백 큐에서 실행할 task를 찾습니다.
event loop는 주기적으로 동작하는데, 그 동작은 반복적으로 콜 스택과 콜백 큐를 확인하는 일입니다. 콜 스택이 비었을 때, event loop는 콜백 큐에서 실행할 다음 함수를 찾습니다. 함수가 큐에서 골라지면, 그 함수는 콜 스택에 추가되어 실행됩니다.
event loop는 Node.js가 메인 스레드를 block하지 않고 동시에 여러 요청을 다룰 수 있음을 보장해주는 역할을 맡고 있습니다. 비동기 I/O 작업과 event loop를 사용함으로써 Node.js는 많은 동시 연결을 적은 latency(지연시간)로 처리할 수 있게됩니다.
event loop가 싱글 스레드 작업임을 명심해야 하는데, 싱글 스레드 작업이란 한 번에 하나의 task만 실행시킬 수 있음을 의미합니다. 그러나 싱글 스레드 작업은 오래 걸리는 작업 때문에 event loop가 block되어 성능 문제를 일으킨다는 의미이기도 합니다. 이를 방지하기 위해서 non-blocking I/O 작업을 사용하는 것과 오래 걸리는 task가 비동기적으로 실행될 수 있는 더 작은 하위 task 묶음으로 분할하는 것이 굉장히 중요한 작업이 됩니다.
Node.js에서 콜 스택, 콜백 큐, 이벤트 루프는 비동기 프로그래밍을 다루기 위해 같이 작동합니다. 이 요소들이 어떻게 상호작용하는지 아는 것 역시 효율적이고 확장가능한 코드를 작성함에 있어 필요합니다.
먼저, 애플리케이션이 시작할 때 event loop가 생성되고 실행 중인 상태가 됩니다. 콜 스택은 초기에 비어있죠. 애플리케이션이 실행됨에 따라 함수들이 호출되고 그들이 호출된 순서에 맞게 콜 스택에 추가됩니다. 그러한 함수들 중 동기 함수들은 그들이 완료될 때까지 콜 스택을 차지(block)하면서 실행됩니다.
반면에, 비동기 함수의 경우에는 비동기적으로 실행됩니다. 비동기 함수가 호출되면, 해당 함수가 콜 스택에 추가되지만 그 스택을 block하지 않고 즉시 반환하여 다음 줄의 코드를 이어나갑니다. 대신, 해당 비동기 작업은 백그라운드에서 수행되고 그 작업이 완료되었을 때 해당 함수의 콜백 함수가 콜백 큐에 추가됩니다.
그러고 나면 콜 스택이 비게되는 때가 오는데, 그 때 event loop가 콜백 큐로부터 실행할 작업을 찾습니다. 앞서 말했 듯, 큐에서 가장 첫번째 함수를 골라서 그 함수는 콜 스택에 추가되어 실행됩니다. 이 함수는 그 안에서 또 다른 함수들을 부를 수도 있고, 그렇게 호출된 함수들 역시 그들이 호출될 때 콜 스택에 추가됩니다. 어떤 함수가 실행이 끝나 반환되면 그 함수는 콜 스택에서 제거될 것이며, event loop는 콜 스택을 보다가 비게 되었을 때, 콜백 큐에서 다음 수행할 콜백 함수를 찾습니다.
이러한 동작의 반복은 콜백 큐에 task가 있는 한 지속됩니다. 이러한 메커니즘을 이용함으로써 Node.js는 메인 스레드를 막지않고 다수의 동시 연결을 다룰 수 있는 것입니다.
콜 스택, 콜백 큐, 그리고 이벤트 루프가 동기와 비동기 함수 둘 다 처리하기 위해 그들이 상호작용하는 방식을 아는 것은 중요합니다. 이러한 요소들이 어떻게 상호작용하는지 이해하면 Node.js에서 더욱 효율적이고 확장가능한 코드를 작성할 수 있습니다.
이렇게 Node.js가 돌아가는 방식에 대한 설명을 보다보면 이해가 가지 않는 부분이 하나가 있습니다. 비동기 함수가 호출될 때는 콜 스택에 추가되었다가 즉시 반환되었다가 비동기 작업 종료 시, 해당 함수의 콜백 함수를 콜 스택에 올려놓고 해당 비동기 작업은 따로 처리가 된다는데, 메인스레드가 콜 스택으로부터 실행하는 작업과 별개로 이 비동기 작업은 어디서 처리가 될 수 있던 것일까요?
이에 대해 이해하기 위해선 Node.js의 구조와 비동기 작업의 방식을 살펴볼 필요가 있습니다.
이전 포스팅에서 아주 잠깐 언급하고 지나갔지만 Node.js는 내부적으로 'libuv'라는 라이브러리를 사용하여 비동기 I/O작업을 처리합니다. 'libuv'는 이벤트 루프와 함께 작동하며, 자체적으로 스레드 풀(thread pool)을 관리합니다. 이 스레드 풀은 비동기 I/O 작업을 수행하기 위한 별도의 스레드들을 포함하고 있으며, Node.js의 메인 스레드와는 독립적으로 작동합니다.
비동기 작업의 처리 과정은 다음과 같습니다.
이러한 과정을 통해 Node.js는 메인 스레드를 block하지 않으면서도 비동기 작업을 효율적으로 처리할 수 있는 것입니다. 'libuv'의 스레드 풀은 자신에게 필요한 리소스를 관리하며, 메인 스레드에서는 이러한 비동기 처리 과정에 대해 신경 쓸 필요 없이 그저 비동기 작업의 결과를 기다리는 콜백 함수를 실행할 준비만 하면 됩니다.
결론적으로, 비동기 작업은 Node.js의 주로 I/O 작업을 처리하기 때문에 메인 스레드와는 독립적으로 리소스를 사용하여 'libuv'의 스레드 풀에서 처리되며, 이로인해 Node.js 애플리케이션이 비동기 작업을 효율적으로 처리하고 동시에 다른 작업을 계속 수행할 수 있는 것입니다.
위 설명을 보면 Node.js도 결국 일부 멀티 스레딩을 활용한다고 볼 수 있는 것인데 Node.js의 비동기 단일 스레딩 모델과 전통적인 멀티 스레딩은 무슨 차이가 있는 것일까요?
동시성(Concurrency)은 여러 task를 동시에 다룰 수 있는 시스템의 능력입니다. 비동기 프로그래밍은 동시성을 효율적으로 다룰 수 있도록 하는 Node.js의 핵심 요소인데요. 비동기 프로그래밍이 메인 스레드를 blocking하지 않고 동시에 여러 task가 수행되도록 해줍니다.
Node.js에서는 비동기 프로그래밍이 콜백 함수와 이벤트 루프의 사용을 통해서 이루어집니다. 비동기 함수가 호출될 때, 그 함수는 즉시 반환되어 다음 줄의 코드를 이어가면서 메인 스레드가 다른 task를 계속 실행할 수 있도록 합니다. 비동기 작업이 완료되면 해당 함수의 콜백 함수는 콜백 큐에 추가되고 이벤트 루프가 그 콜백 함수를 집어 콜백 스택에 추가해 실행 되도록 합니다.
비동기 프로그래밍을 사용함으로써 Node.js는 다수의 동시적인 연결을 적은 소요시간(latency)으로 처리할 수 있게 됩니다. 예를 들어, 웹 요청을 다루는 상황에서, Node.js는 메인 스레드를 blocking 하지 않고 동시에 많은 요청을 다룰 수 있기에 더 빠른 응답시간을 보여줍니다.
하지만 비동기 프로그래밍은 몇가지 문제를 일으킬 수 있는데요. 콜백을 적절히 처리해야 하고 에러가 올바르게 처리되는 것을 보장해야 하기 때문에 동기적인 코드보다 비동기적 코드를 작성하고 디버깅하는 것이 훨씬 더 어려울 수 있습니다. 게다가 동시성은 경쟁 상태(race condition)와 주의있게 다뤄져야만 하는 다른 문제들을 일으킬 수도 있습니다.
이러한 문제들을 해결하기 위해, Node.js는 비동기 프로그래밍을 지원하는 수많은 내장 모듈과 함수들을 제공합니다(예. Promise, async/await). 이러한 툴들을 적절히 사용함으로써 우리는 더 가독성있고 유지보수하기 쉬우며 에러가 없는 비동기 코드를 짤 수 있습니다.
전반적으로, 동시성과 비동기 프로그래밍은 대규모 트래픽을 처리하고 부하가 많은 곳에서도 잘 수행할 수 있게 해주는 Node.js의 핵심 요소입니다. 이러한 개념을 이해하고 이것들을 효율적으로 이용하면 확장 가능하고 효율적인 Node.js 애플리케이션을 작성할 수 있을 것입니다.
멀티플렉싱과 리액터 패턴을 통해, Node.js는 단일 스레드에서도 다수의 I/O 요청을 효율적으로 관리하며, 동기 이벤트 디멀티플렉서와 이벤트 통지 인터페이스를 활용하여 I/O 이벤트를 신속하게 감지하고 적절한 콜백 함수로 전달합니다. 이는 Node.js가 높은 I/O 처리 능력을 가질 수 있는 핵심적인 요소입니다.
동기 이벤트 디멀티플렉서란 이벤트 루프에서 특정 이벤트가 발생할 때까지 대기하고, 이벤트가 발생하면 이를 이벤트 큐(콜백 큐)로 전달하는 구성 요소를 말합니다. 이벤트 루프가 I/O 이벤트를 기다리고 있다가 동기 이벤트 디멀티플렉서를 통해 이벤트의 발생을 전달받으면 이벤트 큐(콜백 큐)로부터 콜백 함수를 꺼내와 콜 스택으로 옮겨 콜백을 실행합니다.
즉, 동기 이벤트 디멀티플렉서는 다양한 I/O 소스로부터 이벤트를 수신하고, 이벤트 루프에 이를 알려 적절한 콜백 함수가 이벤트 큐로 전달되어 이벤트 처리가 이루어지도록 합니다.
이벤트가 발생하는 것을 감지하는 요소는 이벤트 루프가 아니라 동기 이벤트 디멀티플렉서인 것입니다.
이벤트 통지 인터페이스는 이벤트가 발생했을 때 시스템이 이를 알리는 메커니즘입니다. 앞서 예시로 파일을 읽는 작업이 끝나면 이벤트 디멀티플렉서를 통해 이벤트를 반환한다고 했는데, 이벤트 통지 인터페이스가 운영체제 수준에서 발생하는 I/O 이벤트를 감지하고, 이러한 이벤트에 대한 알림을 제공합니다.
Node.js는 운영체제의 이벤트 통지 기능(ex. epoll, kqueue 등)을 활용하여 I/O 이벤트가 발생했을 때 알림을 받습니다. 이를 통해 디멀티플렉서가 이 정보를 기반으로 이벤트 루프에 이벤트를 전달하여 이벤트 루프가 새로운 이벤트를 신속하게 감지하고 처리할 수 있게 합니다.
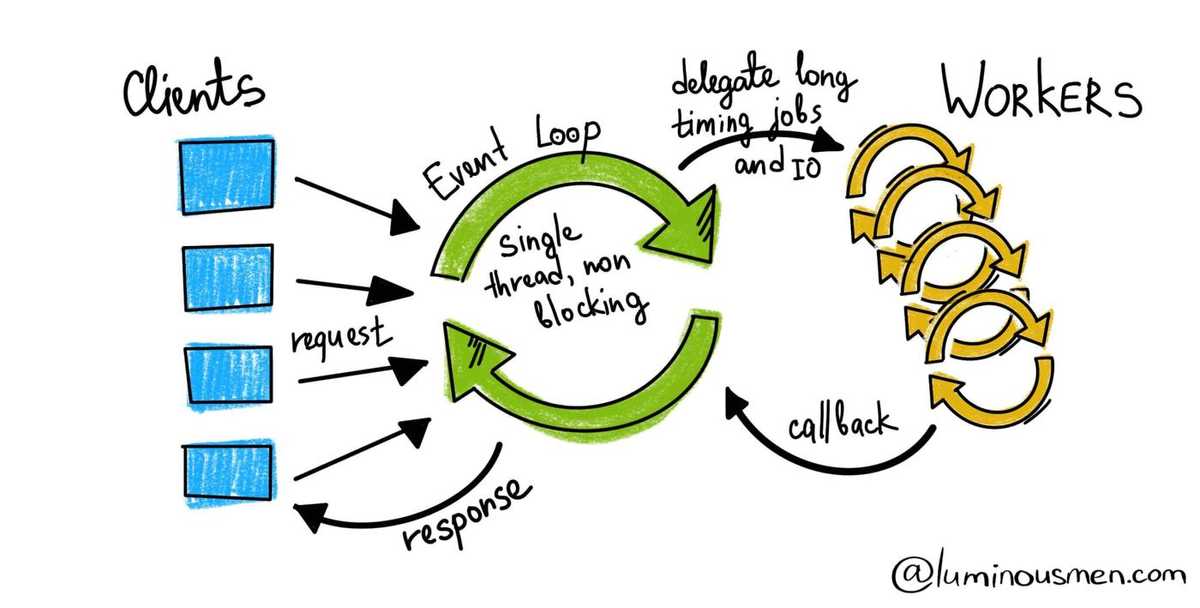
멀티플렉싱(Multiplxing)이란 네트워크에서 사용되는 기술로 하나의 통신채널을 통해 다량의 데이터를 전송하는 기술을 말합니다.
Node.js에서는 멀티 플렉싱을 여러 I/O 소스로부터 발생하는 이벤트에 대해 단일 이벤트 루프에서 모니터링하고 처리하는 방식으로 사용합니다. 그렇기에 매 요청마다 새로운 프로세스나 스레드를 생성해서 응답하도록 하는 것이 아니라, 요청이 몇 개가 동시에 막 들어오든 말든 일단 하나의 프로세스나 스레드를 이용하여 작업을 처리하는 방식인 것입니다.
Node.js는 단일 스레드에서 여러 비동기 I/O 작업을 효율적으로 관리하기 위해 멀티플렉싱 기술을 사용합니다. 이를 통해 단일 이벤트 루프가 다수의 I/O 요청을 모니터링하고 관리할 수 있습니다.
서버는 I/O 처리가 많이 발생하는데, NodeJS의 논 블로킹 방식으로 빠른 I/O처리를 할 수 있으며, 전송을 할 때도 버퍼를 활용하기 보다 데이터를 파이프라인 방식(stream)의 chunk 단위로써 보내는 경우에 특화되었기 때문에 지연 없는 전송을 할 수 있습니다.
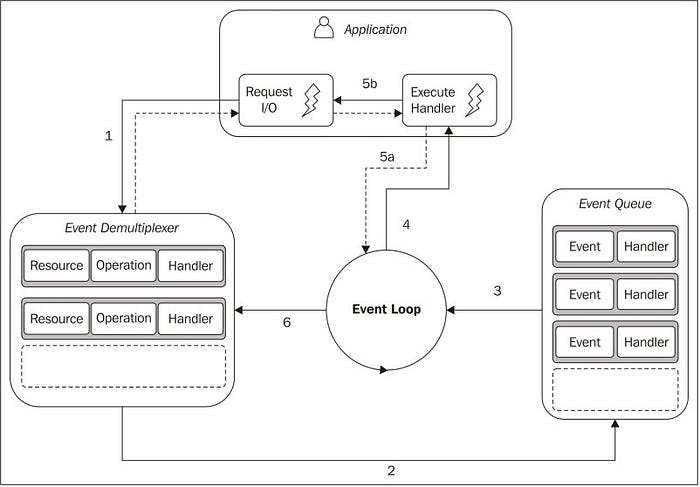
리액터 패턴(Reactor Pattern)은 이벤트가 발생할 때까지 기다리고, 이벤트가 발생하면 해당 이벤트를 처리하는 핸들러(즉, 콜백 함수)를 호출하는 비동기 I/O 패턴을 말합니다. 즉 Node.js의 동작 방식에서 살펴봤을 때 그러한 동작들이 바로 리액터 패턴에 근간하여 이루어졌던 것들입니다.
즉, Node.js의 이벤트 루프는 리액터 패턴을 따르는데, HTTP 요청이나 파일 읽기/쓰기와 같은 이벤트가 발생하면, Node.js는 등록된 콜백 함수를 호출하여 해당 이벤트를 처리하는 식입니다.
리액터 패턴의 주된 아이디어는 각각의 I/O 작업에 연관된 핸들러(콜백 함수)를 하나씩 갖는다는 점입니다. Node.js에서 핸들러는 콜백 함수에 해당하는데, 이 핸들러는 이벤트가 생성되고 이벤트 루프에 의해 처리되는 즉시 호출됩니다.
따라서 이벤트란 Node.js의 동작에서 비동기 함수의 호출로 볼 수 있고 핸들러란 해당 비동기 함수의 콜백 함수로 볼 수 있는 것입니다.
정리하면 애플리케이션은 특정 시점에 리소스로(blocking 없이) 접근하고 싶다는 요청을 하고, 그와 동시에 작업이 완료되었을 때 호출될 핸들러를 함께 제공합니다. 이로써 비동기 동작이 어떻게 이루어져야 할 지 더욱 명확해지고, 만약 이벤트 디멀티플렉서에 더 이상 보류중인 작업이 없고 이벤트 큐에 더 이상 처리 중인 작업이 없다면 Node.js 애플리케이션은 종료됩니다.
한 마디로 리액터 패턴은 일련의 관찰 대상 리소스에서 새 이벤트를 사용할 수 있을 때까지 블로킹하여 I/O를 처리하고, 각 이벤트를 관련된 핸들러에 전달함으로써 반응하는 패턴입니다.
작업이 여러 스레드에 분산되는 대신에, 시간에 따라 분산되며 오직 하나의 스레드만을 사용하는 것이 동시적인 다중 I/O 사용 작업에서 나쁜 영향을 미치지 않을 수 있습니다.
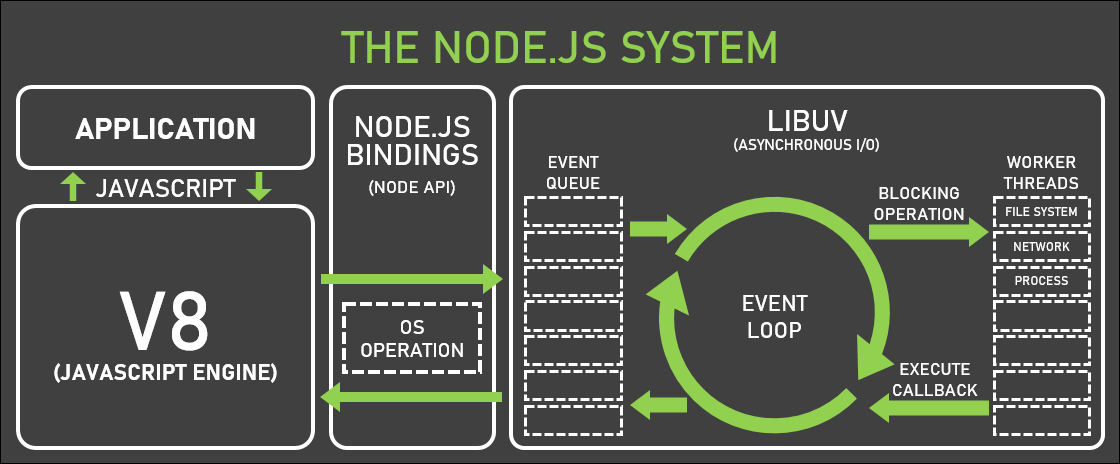
Node.js의 경우 모든 작업처리는 단일 콜 스택에서 이루어지고 비동기 처리는 콜백 큐를 이용하며 이 둘은 하나의 스레드로 이루어진 Event Loop를 통해 사용됩니다. 이벤트 루프는 비동기 I/O 작업 또는 타이머와 같은 이벤트가 발생했을 때, 해당 이벤트를 콜백 큐에 추가합니다. 이후 이벤트 루프는 순환하며 콜백 큐를 확인하고, 준비된 작업(완료된 I/O 등)을 콜스택으로 이동시킵니다.
이 때 Event Loop가 멀티 플렉싱 방식으로 동작하는데, 이는 일단 여러 개의 소켓이 동시에 연결되어 있고, 이들을 관찰하다가 들어오는 작업을 그 때 처리하는 방식입니다
기존의 웹서버에서는 요청이 들어오면 이를 처리하기 위해 프로세스나 스레드를 생성하는데 이를 대기하는 시간이 발생하고 이 과정에서 병목현상이 발생합니다(a.k.a. Thread Waiting).
하지만 Node.js의 경우에는 다량의 작업이 요청되어도 스레드 대기 상태가 발생하지 않고 작업 처리는 다른 스레드로 넘겨버리기 때문에 곧 바로 다른 작업 요청을 받을 수 있게 됩니다.
하지만 이 방식도 만능은 아닌 것이, CPU의 영향을 많이 받는 요청의 경우 한정된 스레드 내에서 I/O 작업이 처리되어야 하기 때문에, 이는 이벤트 루프를 대기시켜 발생하는 이후의 request에 대한 병목현상이 발생할 수도 있습니다.
리액터 패턴과 libuv는 Node.js의 핵심 기본 구성 요소이지만 전체 플랫폼 구축을 위해서 3개의 구성이 더 필요합니다.
이것들이 Node.js를 구성하는 구성요소가 되겠습니다.
자 그럼 이제 이 Node.js를 위한 빠르고 개방적인 간결한 웹 프레임워크 Express에 대해서 배워보도록 하겠습니다.
앞서 살펴 보았듯이, Node.js는 비동기 I/O를 지원하고, 이벤트 주도 방식으로 설계되어 빠른 성능을 제공하긴 하지만 초기의 Node.js는 웹 애플리케이션을 구축하기에는 편의성이나 고급 기능이 너무 부족했습니다.
이러한 문제를 해결하기 위해 Express.js가 등장했는데요. Express.js는 "Node.js 위에서 동작하는 웹 애플리케이션 프레임워크"로 웹 서버를 구축하고 관리하는 일을 훨씬 쉽게 만들어줍니다. 특히 라우팅, 미들웨어, 템플릿 엔진 등의 기능을 제공해 RESTful API 개발을 간편하게 만들어 주었습니다.
Express.js 애플리케이션은 기본적으로 일련의 미들웨어 함수 호출들로 구성되어 있습니다. 미들웨어는 요청 객체(req), 응답 객체(res), 그리고 다음에 실행할 미들웨어 함수(next), 이 세 가지에 접근할 수 있는 함수를 의미하는데요. 이를 통해 요청-응답 사이클 사이에서 특정 작업을 수행할 수 있습니다.
예를 들어, 클라이언트로부터 HTTP 요청이 들어오면, Express는 라우팅을 통해 해당 요청을 처리할 적절한 미들웨어나 핸들러 함수로 전달합니다. 그리고 그러한 함수들은 해당 요청을 처리하고 적절한 응답을 반환하는 역할을 합니다.
또한 템플릿 엔진을 사용하여 동적으로 HTML 페이지를 생성하거나, JSON 데이터를 처리하는 등의 기능 역시 제공합니다. (별도의 모듈 설치 필요)
express는 "프레임워크"이기 때문에 Node.js의 http 내장 모듈을 이용해서도 웹 애플리케이션 서버를 띄울 수 있습니다.
내장 모듈을 사용한 방식과 express를 사용한 방식, 두 방식의 코드를 비교해보면 그 차이를 명확히 아실 수 있습니다.
HTTP 내장 모듈
//http 내장모듈을 사용한 웹서버 띄우기
const http = require('http');
http.createServer(function(request, response){
response.writeHead(200, {'Content-Type':'text/html'});
response.write('Hello http webserver!')
response.end();
}).listen(52773, function(){
console.log("server running http://127.0.0.1:52773/");
});
express
const express = require('express')
const app = express()
const port = 3000
app.use(express.json()); // JSON 요청 본문 파싱
app.get('/', (req, res) => {
res.send('Hello express World!')
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`)
})
express 코드는 다음과 같이 구성되어 있습니다.
위에서 제시한 코드를 실행하면 서버가 다음과 같이 실행됩니다.
그러면 사용자는 특정 엔드포인트로 요청을 보내게 되고, 이를 listen하고 있던 express 인스턴스가 해당 요청을 받아 응답을 하게 됩니다.
미들웨어와 라우트 핸들러는 Express.js에서 요청을 처리하는 방식에 있어 비슷해 보일 수 있지만, 역할과 사용 방식에 차이가 있습니다.
const express = require('express');
const app = express();
// 미들웨어 예시
app.use((req, res, next) => {
console.log('Time:', Date.now());
next(); // 다음 미들웨어나 라우트 핸들러로 요청을 넘깁니다.
});위 예제는 익명함수로 실행될 미들웨어의 내용이 app.use()에 그대로 작성됩니다. 물론 미들웨어에서 실행될 내용의 함수를 따로 선언하여 해당 함수 호출을 인자에 포함시키기도 합니다.
// 라우트 핸들러 예시
app.get('/api/greeting', (req, res) => {
res.send('Hello, World!');
});
// 두 개의 콜백함수를 처리하는 라우트 메소드
app.get('/example/b', function (req, res, next) {
console.log('the response will be sent by the next function ...');
next();
}, function (req, res) {
res.send('Hello from B!');
});
다음 표에 표시된 응답 오브젝트에 대한 메소드는 res를 통해 응답을 클라이언트로 전송하고 요청-응답 주기를 종료할 수 있습니다. 라우트 핸들러로부터 다음 메소드 중 어느 하나도 호출되지 않는 경우, 클라이언트 요청은 정지된 채로 방치되기 때문에 반드시 응답 메소드 중 하나를 통해 응답을 해주어야 합니다.
| 메소드 | 설명 |
| res.download() | 파일이 다운로드되도록 프롬프트합니다. |
| res.end() | 응답 프로세스를 종료합니다. |
| res.json() | JSON 응답을 전송합니다. |
| res.jsonp() | JSONP 지원을 통해 JSON 응답을 전송합니다. |
| res.redirect() | 요청의 경로를 재지정합니다. |
| res.render() | View 템플릿을 렌더링합니다. |
| res.send() | 다양한 유형의 응답을 전송합니다. |
| res.sendFile() | 파일을 옥텟 스트림의 형태로 전송합니다. |
| res.sendStatus() | 응답 상태 코드를 설정한 후 해당 코드를 문자열로 표현한 내용을 응답 본문으로서 전송합니다. |
app.route()를 이용하면 라우트 경로에 대하여 체인 가능한(chainable) 라우트 핸들러를 작성할 수 있습니다. 경로는 한 곳에 지정되어 있으므로, 모듈식으로 라우트를 작성하면 중복성과 오타가 감소하여 도움이 됩니다.
app.route()를 사용하여 정의된 체인 라우트 핸들러의 예는 다음과 같습니다.
app.route('/book')
.get(function(req, res) {
res.send('Get a random book');
})
.post(function(req, res) {
res.send('Add a book');
})
.put(function(req, res) {
res.send('Update the book');
});
위 코드를 보면 알 수 있지만 app.route()를 통해서 하나의 경로로 그룹화하여 경로 문자열의 중복을 줄일 수 있고, 더욱 가독성 있는 코드로 만들 수 있으며, 같은 경로에 대한 모든 라우트를 한 곳에서 관리함으로써, 수정 및 유지보수가 용이해진다는 장점이 있습니다.
express.Router 클래스를 사용하면 모듈식으로 마운팅 가능한 핸들러를 작성할 수 있습니다. Router 인스턴스는 그 자체로도 완전한 미들웨어이자 라우팅 시스템이기에 “미니 앱(mini-app)”이라고 불리는 경우가 많습니다.
라우트를 모듈화하면 관련된 라우트를 하나의 그룹으로 묶어 별도의 모듈로 분리할 수 있어 애플리케이션의 구조를 더 깔끔하고 관리하기 쉽게 만들어줍니다.
아래 코드에서는 라우터를 모듈로서 작성하고, 라우터 모듈에서 미들웨어 함수를 로드한 다음, 몇몇 라우트를 정의하고, 기본 앱의 한 경로에 라우터 모듈을 마운트합니다.
// bird.js
const express = require('express');
const router = express.Router();
// middleware that is specific to this router
router.use(function timeLog(req, res, next) {
console.log('Time: ', Date.now());
next();
});
// define the home page route
router.get('/', function(req, res) {
res.send('Birds home page');
});
// define the about route
router.get('/about', function(req, res) {
res.send('About birds');
});
module.exports = router;
이후 앱 내에서 다음과 같이 라우터 모듈을 로드할 수 있습니다.
// index.js
const birds = require('./birds');
...
app.use('/birds', birds);이제 Router 덕에 메인 애플리케이션 app은 /birds와 연결되어 /birds 및 /birds/about에 대한 요청을 처리할 수 있게 되었으며, 이 때 해당 라우트에 대한해 지정된 특정한 미들웨어 함수인 timeLog가 호출되기도 합니다.
Express.js 애플리케이션에서 코드를 조직하는 방법은 크게 두 가지 접근 방식이 있습니다:
이 접근 방식은 애플리케이션을 모델, 뷰, 컨트롤러(MVC), 서비스, 유틸리티 등과 같이 기능 별로 폴더와 파일을 구분합니다.
/my-app
|-- /configs
| |-- db.config.js
| |-- general.config.js
|-- /controllers
| |-- users.controller.js
| |-- products.controller.js
|-- /models
| |-- user.model.js
| |-- product.model.js
|-- /routes
| |-- user.routes.js
| |-- product.routes.js
|-- /services
| |-- user.service.js
| |-- product.service.js
|-- /utils
| |-- some.utility.js
|-- app.js
|-- server.js
config
먼저 configs 폴더가 있는데, 이 폴더는 애플리케이션에 필요한 모든 설정 및 구성을 포함합니다. 예를 들어, 앱이 데이터베이스에 연결되면 데이터베이스에 대한 구성(DB 이름 및 user 이름 등)을 db.config.js와 같은 파일에 저장할 수 있습니다.
<파일 예시>
// database.config.js
const config = {
host: 'localhost',
user: 'your_username',
password: 'your_password',
database: 'your_database',
// 여기에 추가적인 데이터베이스 연결 설정을 넣을 수 있습니다.
// 예: port: 3306, dialect: 'mysql', pool: { max: 5, min: 0, acquire: 30000, idle: 10000 }
};
module.exports = config;
controller
다음 폴더는 응용 프로그램에 필요한 모든 컨트롤러를 수용하는 컨트롤러입니다. 이러한 컨트롤러 메소드들은 필요에 따라 미들웨어를 사용하여 루트에서 요청을 받아 HTTP 응답으로 변환합니다.
<파일 예시>
const userService = require('./user.service');
// user.controller.js
// 사용자 정보 조회 컨트롤러
const getUserById = async (req, res) => {
try {
const userId = req.params.userId;
const user = await userService.getUserById(userId);
if (!user) {
return res.status(404).send('User not found');
}
res.json(user);
} catch (error) {
res.status(500).send(error.message);
}
};
// 사용자 생성 컨트롤러
const createUser = async (req, res) => {
try {
const userData = req.body;
const newUser = await userService.createUser(userData);
res.status(201).json(newUser);
} catch (error) {
res.status(500).send(error.message);
}
};
module.exports = {
getUserById,
createUser
};
middleware
middleware 폴더는 애플리케이션에 필요한 미들웨어를 한 곳에 분리하여 저장합니다. 인증, 로깅 또는 다른 목적을 위한 미들웨어가 여기에 포함됩니다.
<파일 예시>
// auth.middleware.js
function authMiddleware(req, res, next) {
// 사용자 인증 로직 구현
const token = req.headers.authorization;
if (!token) {
return res.status(401).send('Access denied. No token provided.');
}
// 토큰 검증 로직
// ...
next();
}
module.exports = authMiddleware;
routes
routes 폴더는 각 논리적인 경로 집합에 대해 하나의 파일을 가지게 됩니다. 예를 들어, 한 종류의 리소스에 대해 경로가 있을 수 있습니다. API 버전으로 경로 파일을 분리하기 위해 v1이나 v2와 같은 버전으로 더 세분화하기도 합니다.
<파일 예시>
const express = require('express');
const router = express.Router();
const usersController = require('./usersController');
// 사용자 목록 조회
router.get('/', usersController.getUsers);
// 새로운 사용자 생성
router.post('/', usersController.createUser);
// 사용자 정보 조회
router.get('/:userId', usersController.getUserById);
// 사용자 정보 업데이트
router.put('/:userId', usersController.updateUser);
// 사용자 삭제
router.delete('/:userId', usersController.deleteUser);
module.exports = router;
model
model 폴더에는 애플리케이션에 필요한 데이터 모델이 있습니다. 또한 관계형이나 NoSQL 데이터베이스인 경우 사용되는 데이터 스토어에 따라 달라지기도 합니다. 이 폴더의 내용은 ORM 라이브러리를 사용하여 정의되기도 합니다. ORM을 사용한다면 이 폴더에는 필요에 따라 데이터 모델이 정의되게 됩니다.
<파일 예시>
// user.model.js
// 사용자 조회 함수
function getUserById(userId, callback) {
const query = 'SELECT * FROM users WHERE id = ?';
connection.query(query, [userId], (error, results) => {
if (error) throw error;
callback(null, results[0]);
});
}
// 사용자 생성 함수
function createUser(userData, callback) {
const query = 'INSERT INTO users SET ?';
connection.query(query, userData, (error, results) => {
if (error) throw error;
callback(null, { id: results.insertId, ...userData });
});
}
// 기타 사용자 관련 데이터베이스 함수...
module.exports = {
getUserById,
createUser
// 기타 함수들...
};
service
service 폴더에는 모든 비지니스 로직이 포함됩니다. 비지니스 객체를 나타내는 서비스를 가질 수 있고 데이터베이스에서 쿼리를 실행할 수 있습니다. 필요에 따라 데이터베이스와 같은 일반 서비스도 보통 여기에 배치할 수 있으나, 데이터베이스와의 상호작용이 복잡하거나 여러 데이터 소스에 접근해야 하는 경우에 DAO 폴더를 따로 마련하여 그곳에서 데이터베이스와 관련된 쿼리를 따로 처리하도록 분리를 시키기도 합니다.(유지보수에도 용이)
<파일 예시>
// user.service.js
const userModel = require('./user.model');
// 사용자 정보 조회 서비스
function getUserById(userId) {
return new Promise((resolve, reject) => {
userModel.getUserById(userId, (error, user) => {
if (error) {
reject(error);
return;
}
resolve(user);
});
});
}
// 사용자 생성 서비스
function createUser(userData) {
return new Promise((resolve, reject) => {
userModel.createUser(userData, (error, newUser) => {
if (error) {
reject(error);
return;
}
resolve(newUser);
});
});
}
module.exports = {
getUserById,
createUser
};
utils
마지막으로 utils 폴더에서는 애플리케이션에 필요한 모든 유틸리티 함수들과 helpers를 가지고 있습니다. 또한 공유되는 로직이 있다면 이 폴더는 공유 로직을 배치하는 역할을 하기도 합니다. 예를 들어, 페이지화된 SQL 쿼리의 offset을 계산하기 위한 간단한 도우미를 이 폴더의 helper.util.js 파일에 넣을 수 있습니다.
<파일 예시>
// response.util.js
// 성공 응답 포맷터
function successResponse(res, data, message = 'Success') {
res.status(200).json({
status: 'success',
message,
data,
});
}
// 오류 응답 포맷터
function errorResponse(res, message, statusCode = 500) {
res.status(statusCode).json({
status: 'error',
message,
});
}
// 데이터 없음 응답 포맷터
function notFoundResponse(res, message = 'Not Found') {
res.status(404).json({
status: 'error',
message,
});
}
module.exports = {
successResponse,
errorResponse,
notFoundResponse
};
파일 이름을 짓는 컨벤션은 여러 방식이 있는데요. 크게 세 가지 정도로 설명드릴 수 있을 것 같습니다.
/my-app
|-- /users
| |-- users.controller.js
| |-- user.model.js
| |-- user.service.js
| |-- user.routes.js
|-- /products
| |-- products.controller.js
| |-- product.model.js
| |-- product.service.js
| |-- product.routes.js
|-- /utils
| |-- some.utility.js
|-- app.js
|-- server.js
이 구조에서는 각 라우트(ex. '/users', 'products')가 자체 폴더를 갖고, 해당 폴더 내에는 그 라우트에 관련된 모든 파일(컨트롤러, 모델, 서비스, 라우트)이 포함됩니다.
두 방식 모두 장단점이 있으며, 프로젝트의 요구사항과 팀의 선호에 따라 선택할 수 있습니다.
일반적으로 기능별 분리는 코드의 재사용성과 조직화에 유리하고, 라우트별 분리는 특정 기능이나 도메인에 집중할 때 효과적입니다.
이전 포스팅에서 미들웨어에 대한 용어 정리를 하긴 했지만 Express는 미들웨어가 사실상 이 프레임워크의 전부라고 봐도 되기 때문에 Express에서 미들웨어가 어떤 식으로 활용되는지 잠깐 설명해드리도록 하겠습니다. 미들웨어에 대한 용어 설명은 아래 링크를 참주해주세요.
[NestJS] 2. NestJS와 관련된 용어 정리 (DI, IoC, AOP 등...)
응용 프로그램 패러다임(In NestJS) 용어 정리 DI(Dependency Injection) 먼저 Dependency, 즉 의존성에 대해 알아보겠습니다. 어떤 객체가 다른 객체와 직접 상호작용하거나 어떤 객체가 다른 객체를 참조하
cdragon.tistory.com
가장 흔하게 사용되는 미들웨어의 유형은 다음과 같습니다.
웹 개발에서 로깅은 애플리케이션의 건강 상태를 모니터링하고, 문제 해결을 위한 핵심적인 데이터를 제공하는 필수적인 부분입니다. 특히 서비스의 안정성과 성능, 디버깅을 유지하기 위해서는 필수라고 할 수 있는데요.
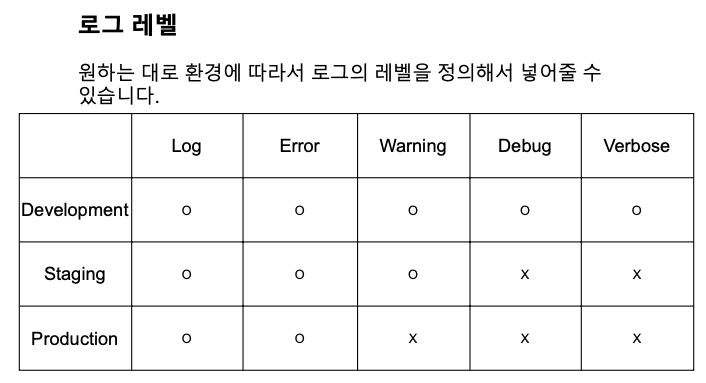
로그의 종류는 다음과 같은 것들이 있습니다.
| 종류 | 설명 |
| Log | 중요한 정보의 범용성 로그 |
| Warning | 치명적이거나 파괴적이지 않지만 처리되지 않은 문제 |
| Error | 치명적이거나 파괴적이고 처리되지 않은 문제 |
| Debug | 오류 발생 시 로직을 디버깅하는 데 도움이 되는 유용한 정보 게시 (For developer) |
| Verbose | 애플리케이션 내에서 이루어지는 동작에 대한 insight를 제공하는 정보 게시 (For operator or admin) |
log
일반적인 정보를 기록할 때 사용됩니다. 예를 들어, 애플리케이션이 시작되었을 때나 주요 작업이 완료되었을 때 사용할 수 있습니다.
logger.log('Application has started on port 3000');
error
오류가 발생했을 때 사용됩니다. 오류 메세지와 함께 스택 트레이스(trace)를 로깅할 수 있습니다.
try {
// 오류가 발생할 수 있는 코드
} catch (error) {
logger.error('Error occurred in processing', error.stack);
}
warn
잠재적인 문제를 알릴 때 사용됩니다. 예를 들어, 구현이 불완전하거나 추후 문제가 될 수 있는 부분에 대해 경고할 때 사용합니다.
logger.warn('The method deprecatedMethod is deprecated and will be removed in the next version');
debug
디버깅을 위한 상세 정보를 기록할 때 사용됩니다. 개발 단계에서 문제를 진단하는 데 도움이 됩니다.
logger.debug(`User data received: ${JSON.stringify(userData)}`);
verbose
매우 상세한 정보를 기록할 때 사용됩니다. 일반적으로 개발 과정에서 더 많은 컨텍스트나 세부 사항이 필요할 때 사용됩니다.
logger.verbose(`Connected to database with config: ${databaseConfig}`);
또한 로깅은 현재 프로그램이 띄워진 개발 환경이 어느 스테이지냐에 따라서 보도록 하는 정보가 다 다릅니다.
express에서는 다양한 로깅 라이브러리를 사용할 수 있으며 가장 널리 사용되는 라이브러리는 Morgan, Winston, Bunyan 정도가 있겠습니다.
관련 라이브러리 하나 정도를 다뤄보면 좋겠지만 NestJS에서는 기본 모듈에 Logger가 내장되어 있어 쉽게 로거를 사용할 수 있기 때문에 따로 다루지는 않겠습니다.
| [NestJS] NestJS CLI로 REST API를 사용한 CRUD 기능 만들기(5분버전 vs. 심화버전) with TypeORM & MySQL (0) | 2024.01.24 |
|---|---|
| [NestJS] NestJS에서 Swagger 사용법 (feat. API Documentation) (2) | 2024.01.23 |
| [NestJS] NestJS 시작 (설치 & 구성요소 맛보기) (3) | 2024.01.22 |
| [NestJS] NestJS와 관련된 기술 용어 정리 (DI, IoC, AOP 등...) (0) | 2024.01.19 |
| [NestJS] NestJS 시작 전에 알아야 하는 백엔드 지식 (0) | 2024.01.10 |
소중한 공감 감사합니다