Preview)

- 오른쪽 아래에 있는 내가 공부를 하는데 책상에 책 몇 권만을 두고 공부를 한다.
- 이 책들은 내가 손만 뻗으면 쉽게 available 하지만 책상에는 많은 책을 두고 공부를 할 수 없다는 단점이 있다.
- 공부를 하다가 없는 책이 있다면 바로 왼쪽에 있는 책꽂이로 가서 원하는 책을 가져온다.
- 만약 그 책꽂이에도 없다면 도서관 전체를 돌아 다니면서 찾아야 하고
- 그래도 없다면 인터넷을 통해 다른 서점에서 구하거나 해외에서 직구하거나 해야 한다.
- 이 굉장히 오랜 시간 걸릴 때 동안 숙제를 안 하고 있으면 굉장히 손해이기 때문에 그 책이 필요한 숙제는 잠시 접어두고 다른 숙제를 한다.
위의 비유에서 각각의 요소는 컴퓨터에서 무엇을 의미하는 지를 보자.
- 책상에 있는 책: register file
- 책꽂이: cache(SRAM)
- 도서관: main memory(DRAM)
- 인터넷: HDD / SSD
- 나: CPU
memory(cache)에 있는 걸 register file로 가져오는 것은 프로그래머가 하는 일
main memory에서 cache로 오는 것은 hardware 영역
main memory에 없는 걸 HDD에서 가져오는 것은 OS 담당
where to put?
how many?
가 이번 챕터에서 중요한 issue
- 들어갈 수 있는 장소가 딱 정해져 있으면 -> direct-mapped
- 아무데나 가도록 하는 것 -> fully associative
8번에 access하고 싶은데 이게 188번인지 208번인지를 모르기 때문에 앞에 18이라는 tag가 붙여져 있어서 이를 통해 찾는다.
direct-mapped와 fully associative의 절충안 -> n-way set-associative
프로그래밍을 할 때 locality를 고려하지 않고 짠다면 성능이 안 좋을 수 밖에 없다.
Cache



- Pipelined에서 hazard를 해결하기 위해 굉장히 설계를 신중하게 했지만
- Data cache에 데이터가 없었다면 (즉, cache miss) main memory가서 가져와야 하는데 이는 결국 50배 사이클 손해를 보게 된다.
- 즉 cache에 data 하나만 없어도 몇 십배의 손해를 보게 된다.(clock cycle 설계보다 훨씬 중요함.)
세 가지 MIPS 설계는 모두 데이터와 명령어 메모리를 위한 1 clock을 가정했다;
하지만 일반적인 RAM은 10~50배 느리다.
All three of our MIPS designs assumed 1- clock for data and instruction memory;
however, typical RAMs are 10-50 times slower
Cache
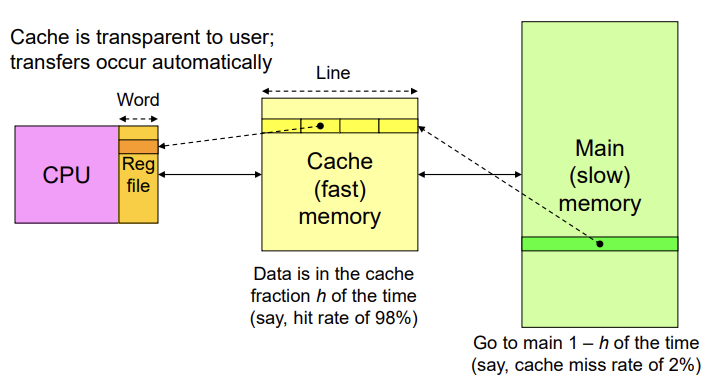
Line = Block
Cache Design Parameters
- Cache size (in bytes or words).
- 캐시가 클수록 프로그램의 유용한 데이터를 더 많이 저장할 수 있지만 비용이 많이 들고 속도가 느려질 가능성이 있습니다.
- Block or cache-line size (캐시와 main memory 사이의 데이터 이동 단위)
- 어디다 둘 것인지
- 캐시 라인이 커지면 누락될 때마다 더 많은 데이터가 캐시로 들어간다.
- 이는 적중률을 향상시킬 수 있지만, 낮은 유틸리티 데이터를 초래할 수도 있다.
- Placement policy.
- incoming 캐시 라인이 저장되는 위치를 결정합니다.
- 보다 유연한 정책은 더 높은 하드웨어 비용을 의미하며, (더 복잡한 데이터 위치로 인해) 성능 이점이 있을 수도 있고 없을 수도 있다.
- Replacement policy.
- 어떤 걸 쫓아낼지 결정
- (새 캐시 라인을 매핑할 수 있는) 기존의 여러 캐시 블록 중 어떤 것을 덮어쓰는지 결정합니다.
- Typical policies: 임의 또는 가장 최근에 사용된(LRU; least recently used) 블록 선택.
- Write policy.
- 사실상 memory에 write을 해야 하는데 시간이 매우 많이 걸리기 때문에 cache를 잘 사용하여 write하도록 하자.
- 캐시 워드에 대한 업데이트가 즉시 메인(write-through)으로 전달되는지 여부를 결정 or
- 그때 그때마다 write 하는 것 -> 엄청난 시간 소요
- 수정된 블록은 교체해야 한다면 그리고 교체해야 하는 경우 (write-back or copy-back) 메인으로 다시 복사됩니다.
- 모아놨다가 몽땅 write 하는 것 -> 효율적임
Desktop, Drawer, and File Cabinet Analogy

- 데스크톱(레지스터) 또는 서랍(캐시)에 있는 항목은 파일 캐비닛(메인 메모리)에 있는 항목보다 쉽게 액세스할 수 있다
도서관 예가 더 좋음
Temporal and Statial Localities

한 번 access 된 것은 계속해서 많이 사용되더라 + 한 번 access 되면 그 근처에 있는 것도 같이 access 되더라는 것을 경험적으로 알 수 있는 그래프
Compulsory, Capacity, and Conflict Misses
- Compulsory(강제적) misses:
- on-demad fetching을 사용하면 모든 항목에 대한 첫 번째 액세스가 miss 된다.(어쩔 수 없음)
- 일부 "compulsory" miss는 prefetching을 통해 방지할 수 있다.
- 시스템을 처음 켰을 때는 cache에 아무것도 없을 것이기 때문에 처음에 무조건 한 번은 갖다 놔야 한다.
- invalid bit이기 때문에 생기는 misses
- Capacity misses:
- 우리는 다른 사람들을 위한 자리를 마련하기 위해 일부 항목을 축출해야 합니다. 이는 무한히 큰 캐시에서 발생하지 않는 누락으로 이어집니다.
- cache 사이즈가 너무 작아서 생기는 misses
- Conflict misses:
- 때때로 불필요한 데이터가 차지하는 여유 공간 또는 공간이 있지만 매핑/배치 체계는 다른 항목을 가져오기 위해 유용한 항목을 강제로 이동시킨다.
- 이는 미래에 miss를 초래할 것이다.
- cache size는 큰데, 들어올 자리는 한정되어 들어오는 data에 대해서 충돌이 일어나서 생기는 miss
- 위 비유에서 188번과 208번 자리는 들어오는 곳이 똑같은 것과 같은 이유.
- main memory와 hard disk 간의 miss는 굉장히 큰 영향을 주기 때문에 이를 줄이기 위해선 무조건 fully associative를 사용해야 함
- virtual memory에서는 miss rate을 줄여야 함.
- 그런데 fully associative를 위해선 다 뒤져봐야 하기 때문에 이를 OS가 관리하도록 되어있다.(page table)
Cache
- 메모리 계층에서 가장 높은 level
- Fast (typically ~1 cycle access time)
- 이상적으로는 대부분의 데이터를 processor로 공급한다.
- 대개 most recently accessed data를 갖는다.(가장 최근에 접근된 데이터)

Cache Design Questions
- What data is held in the cache? (캐시에 어떤 데이터를 가질지)
- How is data found? (데이터를 어떻게 찾을 것이지)
- What data is replaced? (충돌이 나면 어떤 걸 replace 할 것인지)
우리는 데이터 로드에 집중하지만 저장도 같은 원칙을 따른다.
What data is held in the cache?
- 이상적으로, 캐시는 필요한 데이터를 예측하여 캐시에 저장합니다
- 하지만 미래를 예측하는 것은 불가능하다.
- 미래를 예측하기 위해 과거를 사용한다. - temporal and spatial locality:
- Temporal locality: 새로 접근된 데이터를 캐시로 복사
- Spatial locality: 근처 데이터를 캐시로 복사
Cache Terminology
- Capacity (C):
- 캐시 안의 데이터 bytes의 수 (전체 cache size)
- Block size (b):
- 한 번에 캐시로 가져온 데이터 바이트 수 (연속되어 있는 data를 한 번에 가져오는 크기)
- Number of blocks (B = C/b):
- Degree of associativity (N):
- 한 set에서 block의 수
- 메모리에 있는 data를 cache에 가져오는데 몇 자리에 넣을 수 있는지
- Number of sets (S = B/N):
- 각 메모리 주소는 정확히 하나의 캐시 집합에 매핑됩니다
How is data found?
- 캐시를 S 세트로 구성
- 각 메모리 주소는 정확히 하나의 캐시 집합에 매핑됩니다
- 한 세트에서 블럭의 수에 의해 카테고리화 된 캐시
- Direct mapped: 1 block per set
- N-way set associative: N blocks per set
- Fully associative: all cache blocks in 1 set
- 다음을 통해 각 조직에서 캐시를 검사한다:
- Capacity (C = 8 words)
- Block size (b = 1 word)
- So, number of blocks (B = 8)
Example Cache Parameters
- C = 8 words (capacity)
- b = 1 word (block size)
- So, B = 8 (# of blocks)
터무니없이 작지만 조직을 보여줄 것이다
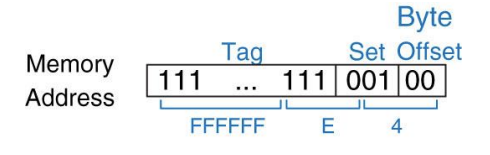
Direct Mapped Cache

- 들어갈 수 있는 자리는 8자리이므로 3 bit로 표현을 하고 이를 set number라고 한다.
- word address의 맨 마지막 3 bit를 보고 들어갈지 말 지를 결정한다.
- 뒤의 00(Byte offset)을 제외하고 마지막 3 bit
- 메모리가 들어갈 곳(번지)이 하나하나 다 정해져 있는 (associative) direct mapped and 1-way
- 그렇기 때문에 다른 메모리여도 같은 번지수를 가질 수 있기 때문에 같은 번지에 계속 접근하면 그 때마다 miss가 발생할 수 밖에 없다.
Cache fields
- 많은 주소가 단일 집합에 매핑된다
- 각 세트에 포함된 데이터를 계속 추적해야 함
- 주소의 LSB(least significant bits)를 어느 세트인지 명시한다.
- 남아있는 MSB 비트(tag라고 함)는 가능한 많은 주소 중에서 어느 것을 가리킨다
Direct Mapped Cache Hardware

- set을 토대로 cache에 access하여 그곳의 data를 바로 가져가는 것이 아니라 tag를 확인 비교해서 맞는 지를 확인하고 데이터 read를 하고 있는 중임을 나타내는 Validation bit와 AND 연산을 통해 Hit이 결정된다.
- 초기에는 0이고 데이터가 load가 되었다라는 것을 알려주기 위한 validation bit
- Hit이면 data 부분을 쫙 가져가서 사용한다.
- cache memory의 size
- 1+27+32 =60 bit
- total size = 60 x 8 = 480

# MIPS assembly code
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw $t2, 0xC($0)
lw $t3, 0x8($0)
addi $t0, $t0, -1
j loop
done:
0x4: 0100 -> ...0000100
0x8: 1000 -> . ..0001000
0xC: 1100 -> ...0001100
- MMM HHH HHH HHH HHH
- 처음에는 miss가 날 수 밖에 없음(compulsory misses)
MIPS Rate = 3/15 =20 % =0.2
- Temporal Locality
- Compulsory Misses(처음에 어쩔 수 없이 생기는 miss)
Direct Mapped Cache: Conflict

- 4번지와 24번지에 access하는 상황 -> 계속해서 싸운다.
- 0x04: 0000100
- 0x24: 0100100
- 001(1)에 access 하려고 하기 때문에 miss 발생.
- 4번지를 넣고 tag를 확인하려 하는데 tag가 다름
- 24번지를 넣고 tag를 확인하려 하는데 tag가 다름
- 위 과정이 무한 반복되어 계속해서 miss가 발생
그럼 들어갈 수 있는 곳을 한 군데 말고 두 군데로 만들어 보자 라는 idea 도입 -> 2-way set associative
N-Way Set Associative Cache

- set이 지정하는 2 bit으로 줄었다. set의 갯수가 4개로 줄었기 때문에.(way가 두 개가 되면서)
- 전체 set의 갯수는 줄어들지만 어떤 set에서 들어갈 수 있는 자리가 2개가 마련되어 있는 것이다.
- 두 경우를 모두 check하여 hit인 경우의 data를 뽑아온다.


0x04: 00000100
0x24: 00100100
- 이제는 싸우지 않고 다른 곳에 저장
- 처음만 miss고 나머지는 계속 Hit
- compulsory miss
- 2-way associativity로 conflict misses를 줄였다.
Miss Rate = 2/10 = 20%
- (2-way) Associativity reduces conflict misses
Fully Associative Cache

- 8-way
- 들어갈 수 있는 자리(set)을 쫙 일렬로 풀어서 아무데나 다 들어갈 수 있게 하면 몇 개가 중복이 되더라도 위처럼 계속 넣을 수 있지만 tag를 일일히 다 보면서 비교해야 하기 때문에 오히려 시간이 더 많이 걸리 수도 있기 때문에 너무 늘릴 수는 없다.
- 그렇기 때문에 conflict miss는 확실히 줄인다. (2-way에서는 한계가 있었기 때문에)
- Reduces conflict misses
- 가져올 때(read), Expensive to build (tag 비교하는 횟수가 너무 많아 그 만큼의 시간이 소모 된다.)
지금까지는 block size를 1로 생각해서 어디에 저장할 지를 중점으로 알아보았다.
Q) set과 associative의 차이
A)

- 몇 번지를 나타내는 것이 set
- set 안에 저장할 수 있는 공간이 몇 개 있는지를 나타내는 것이 n-Way
- set = cache의 address라고 생각하면 된다.
- hardware가 굉장히 커져서 delay가 길어지기 때문에 cache에서는 잘 사용하지 않는다.
- 하지만 VM에서는 한 번 갔다오는 시간이 엄청 걸리기 때문에 comflict miss을 줄이는 것이 관건이기 때문에 VM에서는 fully associative를 사용한단.