한 번 가져올 때 miss가 나는데 (compulsory miss) 그걸 가져올 때 근처에 있는 것을 가져오기 때문에 그 이후에 그 주소를 가져올 때는 compulsory miss가 발생하지 않는다.
Block size Consideration
블록이 클수록 miss rate이 줄어든다
공간적 지역성으로 인해
그러나 고정된 크기의 캐시에서
더 큰 블록 => 더 적은 수의 블록
더 많은 경쟁 => miss rate 증가
더 큰 블록 => pollution
더 큰 miss penalty
miss rate 감소의 이점을 무시할 수 있음
Early restart and critical-word-first can help
이른 재시작 및 critical-word-first가 도움이 될 수 있다
Types of Misses
Compulsory: 첫 데이터 접근
Capacity: cache too small to hold all data of interest
전제적으로 cache size가 작아서 할 수 없이 생기는 miss
Conflict: 관심 있는 데이터가 캐시의 동일한 위치에 매핑됨
n-way를 조금 늘리면 괜찮아지는 miss (용량을 늘리고 tag로 확인)
Miss penalty: 하위 계층에서 블록을 검색하는 데 걸리는 시간
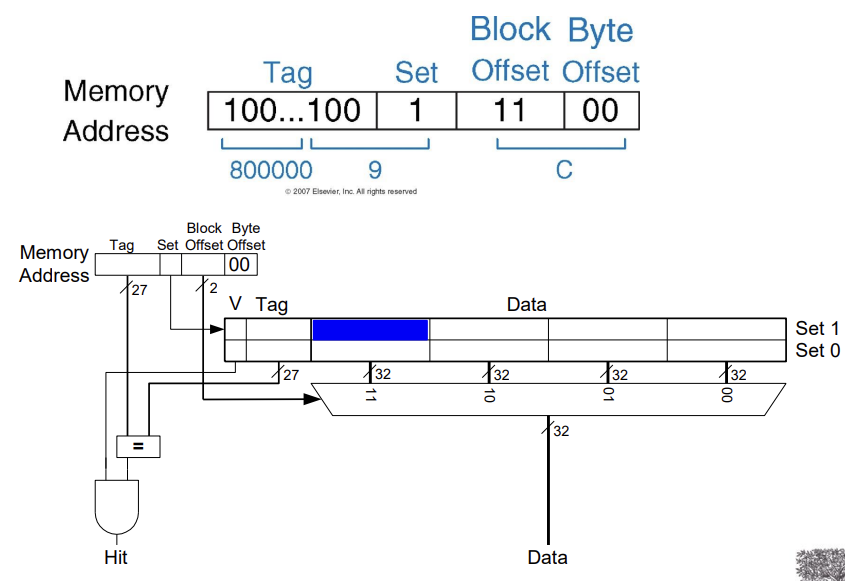
Cache Organization Recap
Capacity: C
Block size: b
Number of blocks in cache: B = C/b
Number of blocks in a set: N (direct의 경우 1)
Number of sets: S = B/N
Chapter 8: Memory Systems
Cache Replacement Policy
Replacement Policy
캐시가 너무 작아서 관심 있는 모든 데이터를 한 번에 저장할 수 없음
캐시가 가득 찬 경우: 프로그램이 데이터 X에 액세스하여 데이터 Y를 내보낸다
Y에 다시 access할 때 capacity miss
Y를 선택하여 다시 필요한 가능성을 최소화하는 방법은 무엇입니까?
Least recently used (LRU) replacement: 퇴거된 집합에서the least recently used block
cache에 데이터가 다시 들어오게 되는 경우 기존에 있던 것을 버려야 할텐데 무슨 기준으로 버려야 되는가?
LRU(Least recently used) replacement
Direct mapped: no choice
Set associative:
유효하지 않은 항목이 있는 경우 선호된다
그렇지 않으면, 세트의 항목 중에서 선택 충돌: 관 심 있는 데이터가 캐시의 동일한 위치에 매핑됨
Least-recently used (LRU)
가장 오랫동안 사용되지 않은 것을 선택합니다
Simple for 2-way, manageable for 4-way, too hard beyond that
2-way나 4-way는 managable 한데 엄청 큰 건 힘듦
Random
Gives approximately the same performance as LRU for high associativity
생각보다 성능이 높음(n이 클 때 거의 LRU와 비슷한 성능)
LRU Replacement
0x04가 들어오고 0x24가 들어왔기 때문에 더 먼저 쓰인 04번지를 밀어내고 새로 54 번지가 들어오도록 한다.
둘 중에 어떤게 더 최근에 쓰였는지 항상 tracking을 해야 함.
Cache Misses
cache hit일 때, CPU는 정상적으로 동작
cache miss일 때
Stall the CPU pipeline
access를 할 수 없기 때문에
계층의 next level로부터 블럭을 fetch
Instruction cache miss
instruction fetch 재시작
Data cache miss
Complete data access
Write-Through
data-write hit일 때, 캐시에 블럭을 곧바로 업데이트 할 수 있다.
cache에는 write이 바로 될 지라도 실질적으로 memory에 써지지는 않는다.
하지만 캐시와 메모리는 일관되지 않을 것이다.
Write through: memory에도 update
cache가 update 될 때마다 memory도 update 하도록 한다!
시간이 엄청 걸릴 것이다 -> buffer로 해결(뭉탱이로)
대신 cache와 memory의 내용이 같게 유지할 수 있다.
그러나, 쓰기 시간이 더 오래 걸립니다
e.g., 만약 base CPI = 1이고 10%의 명령어가 저장되면, 메모리에 쓰는데 100 cycles가 걸린다.
Effective CPI = 1 + 0.1×100 = 11
Solution: write buffer
메모리에 쓰이기 기다리는 데이터를 갖고 있는다.
CPU는 즉시 계속된다.
write buffer가 이미 full이라면 write할 때만 stall한다.
Write-Back
Alternative: data-write hit일 때, 캐시에 블럭을 곧바로 업데이트 할 수 있다.
각 block이 dirty인지를 추적한다.
dirty block이 대체될 때:
메모리로 다시 쓴다.
가장 먼저 읽히는 block을 교체할 수 있도록 write buffer를 사용할 수 있다.
쓰기 버퍼를 사용하여 교체 블록을 먼저 읽을 수 있습니다
또 다른 방식은 Write-back 방식이다. 이 방식은 블록이 교체될 때만 메모리의 데이터를 업데이트한다. 데이터가 변경됐는지 확인하기 위해 캐시 블록마다 dirty 비트를 추가해야 하며, 데이터가 변경되었다면 1로 바꿔준다. 이후 해당 블록이 교체될 때 dirty 비트가 1이라면 메모리의 데이터를 변경하는 것이다.
Write Miss - Write Allocation
write miss시에 무슨 일이 벌어지는가?
For, Write-through
Write allocate (or fetch-on-write): block을 fetch하여 write-hit operation을 수행한다.
Write around (or write-no-allocate): 캐시로 로드되지 않고 메모리에 직접 쓰인다.
프로그램은 종종 전체 block을 읽기 전에 쓰기 때문에 (예: initialization)
For, Write-back
대개 block을 fetch
데이터를 변경할 주소가 캐싱된 상태가 아니라면(Write miss) Write-allocate 방식을 사용한다. 당연한 얘기지만, 미스가 발생하면 해당 데이터를 캐싱하는 것이다. write-allocate를 하지 않는다면 당장은 resource를 아낄 수 있겠지만 캐시의 목적을 달성하지는 못할 것이다.
Example: Intrinsity FastMATH
Embedded MIPS processor
12-stage pipeline
Instruction and data access on each cycle
Split cache: separate I-cache and D-cache
Each 16-KB: 256 blocks * 16 Words/block
D-cache: write-through or write-back
SPEC2000 miss rate (benchmark program)
I-cache: 0.4%
D-cache: 11.4%
Weighted average: 3.2%
Example: Intrinsity FastMATH
Virtual memory와 합쳐진 processor 구조가 중요함 (추후에 배울 것)
Main Memory Supporting Caches
main memory로 DRAM을 사용
고정된 너비 (e.g., 1 word)
고정된 너비를 갖는 clocked bus에 의해 연결됨
Bus clock 은 일반적으로 CPU clock보다 더 느리다.
Example cache block read
Assume, 1 bus cycle for address transfer
15 bus cycles per DRAM access
1 bus cycle per data transfer
For 4-word block, 1-word-wide DRAM
Miss penalty = 1 + 4×15 + 4×1 = 65 bus cycles
Bandwidth = 16 bytes / 65 cycles = 0.25 B/cycle
memory에서 가져오기 위해 address를 전달하는데 한 clock 걸린다고 가정( bus를 통해 전달)
DRAM이니까 cell에 가서 메모리를 가져와서 적재하는데 15 bus cycle이 걸림.
전달하는데 1 bus cycle
그렇다면 4word(16 byte)를 가져오는데 몇 clock이 걸릴까?
Increasing Memory Bandwidth
a->b : bus가 32에서 128로 변화했다하면
4-word wide memory
Miss penalty = 1 + 15 + 1 = 17 bus cycles
Bandwidth = 16 bytes / 17 cycles = 0.94 B/cycle
address가 bus를 통해 오면, 상위 address는 똑같기 때문에 memory bank에 동시에 찾아간다.
찾아 가는데는 15clock, 하나씩 보내는데 4clock
4-bank interleaved memory
Miss penalty = 1 + 15 + 4×1 = 20 bus cycles
Bandwidth = 16 bytes / 20 cycles = 0.8 B/cycle
b의 bus는 128 bit, c의 bus는 32bit
c를 쓰는 것이 좋다.
메모리에 접근하는것은 캐시 하나 존재 > 메모리가 버스로 연결 > 메모리 구조이다. 이때, bandwidth를 늘리면 한번에 이동가능한 메모리양이 늘어난다. bus를 늘리기 위해서는 구조비용이 많이 들게 된다. 따라서 비용없이 늘리기 위해서는 bank라고 하는 개념이 도입된다.