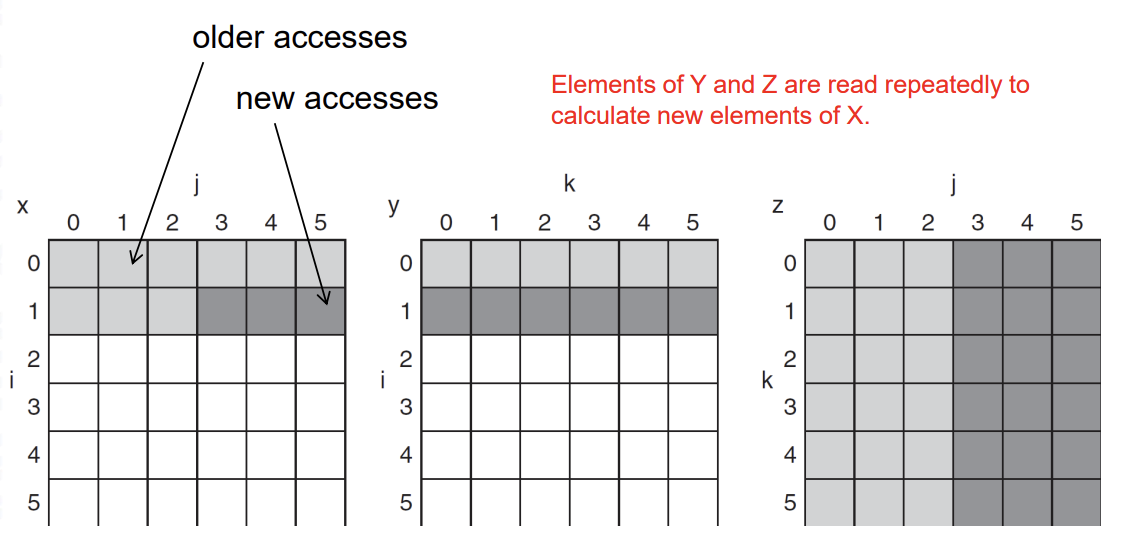
after와 같이 되어있어야 데이터가 저장되어 있는 순서대로 access하기 때문에 cache를 잘 사용하는 것이다.
before 방식처럼 사용하게 되면 access를 세로로 하기 때문에 데이터 access를 계속 jump를 해 가면서 하기 때문에 locality를 완전히 무시하게 된다.
Software optimization via Blocking
목표: 데이터가 교체되기 전에 데이터에 대한 접근을 최대화시키는 것
Consider the loops of DGEMM (double precision general matrix multiplication): X = YZ
for ( i = 0; i < n, ++i)
for ( j = 0; j < n; ++j)
{
r = 0;
for( k = 0; k < n; k++ )
r += Y[i][k] * Z[k][j];
X[i][j] = r;
}
n by n이 size가 작으면 상관 없는데 크면 문제가 된다.
두 개의 내부 루프는 모든 N을 Z의 N개 원소로 읽고, 같은 N개 원소를 Y의 행으로 반복해서 읽고, X의 N개 원소 중 한 행을 write한다.
Software optimization via Blocking
X, Y and Z arrays
column을 가져와야 하는 j는 부담이 너무 크다.
Software optimization via Blocking
/* after */for (jj=0, jj < n, jj = jj+B)
for (kk=0, kk < n, kk = kk+B)
for ( i =0; i < n, ++i)
for ( j = jj; j <min(jj+B, n); ++j)
{
r =0;
for( k = kk; k <min(kk+B, n); k++ )
r +=Y[i][k] *Z[k][j];
X[i][j] =X[i][j] + r;
}
그래서 한 번에 쭉 다 계산하는 것이 아니라 적당한 block을 나누면 충분히 cache에 올라올 수 있기 때문에 그것에 대해서 계산을 진행하고 Block pointer를 옮겨가면서 Block 마다 matrix 계산을 쭉 이어 나간다.
이제 두 내부 루프는 X와 Z의 전체 길이가 아니라 크기 B의 단계로 계산됩니다. (X는 0으로 초기화된다고 가정합니다.)
Example (n=4, B=2)
두번째 퍼즐 그림 잘못됨
Software optimization via Blocking
GFLOPS - 초당 몇 기가의 floating point 계산을 할 수 있는지
blocked는 새로 block이 올라올 때만 바꾸면 되기 때문에 초당 연산량이 거의 감소하지 않는다.
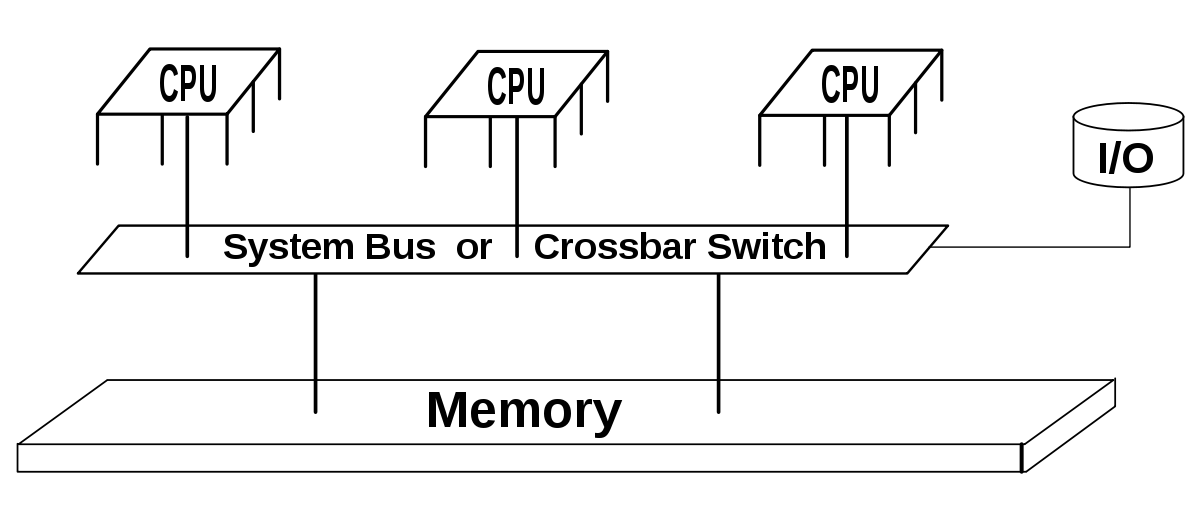
Cache Coherence Problem
Shared memory
두 개의 CPU cores가 물리적인 주소 공간을 공유한다고 가정
Write-through caches
처음에는 memory에 0이 들어있었다.
cache A가 이를 read 하면 A cache에는 0이 써질 것이다.
cache B가 또 read하면 B에도 0이 써질 것이다.
CPU A가 데이터 0을 1로 바꾸면 그 즉시 메모리 X에도 반영되어 write한다.
그러면 cache와 memory에 값들이 전부 다 다른 문제가 발생한다. -> cache coherence
두 CPU의 각 cache(즉, 클라이언트) 에서 접근한다고 했을 때 캐시의 갱신으로 인한 데이터 불일치가 생기는데 예를 들어, 쉽게 말해서 변수 x가 있는데 이 값은 0이다.
그런데 A에서 이 값을 1로 바꾸었고 B에서 x값을 읽는 상황을 가정해 보면, CPU B는 A가 수정한 값 1을 읽는 것이 아니라 현재 자신의 로컬 캐시인 0을 읽을 수 밖에 없다. 따라서 캐시 1, 2는 같은 X라는 변수에 대해 다른 값을 가지게 되므로 데이터 불일치 문제가 발생한다.
Cache Coherence Protocols
일관성( coherence )을 보장하기 위해 multiprocessors에서 캐시가 수행하는 연산
local caches로 데이터의 migration
shared memory에 대한 bandwidth를 감소시킨다.
read-shared 데이터의 복제(replication)
Reduces contention for access
접근에 대한 경쟁을 감소시킨다.
Snooping protocols (snoop: 돌아다니면서 몰래 살펴보는)
각 cache는 bus reads/writes을 모니터한다.
bus를 통해 누가 쓰고 있는지 아닌지를 모니터한다.
Directory-based protocols
어느 cache가 사용했는지 전부 기록하는 방식
caches와 메모리가 directory에 block의 상태를 공유하는 것을 기록한다.
Invalidating Snooping Protocols
Cache는 block을 기록할 때 block에 대한 독점적인 접근 권한을 갖는다
bus에서 유효하지 않은 메시지를 broadcast 한다
Subsequent read in another cache misses
또 다른 cache에서 후속 읽기가 miss된다.
cache 소유를 통해 업데이트된 가치 제공
A가 memory X에 1을 write하는 경우 다른 CPU는 bus를 사용하지 못하도록 bus activity에 대해서 Invalidate for X를 알려주는 것이다.
그렇기 때문에 이 때 B의 cache에는 데이터가 없을 것이고 그 후에 memory를 read하게 되면 memory 대신 A가 write한 값을 B에게 주게 된다.
Q) 어떻게 A가 B한테 주는 거지? monitor를 통해 x는 invalidate하다고 되었기 때문에 A가 주는 건가?