새소식
반응형
이번 시간에는 해시에 대해 배워보겠습니다.(내용이 상당히 많으니 정말 알찬 포스팅이 될 것 입니다 ^.^)
해시 자체는 어려운 개념이 아니나 이를 구현할 때는 노드와 LinkedList를 이용하여 구현하기 때문에 이전 과정이 복습이 잘 된 상태여야 이해가 더 잘 될 것입니다.
LinkedList를 참고하기 위해서는 아래 링크를 참조하세요.
[CS 지식/자료구조와 알고리즘(Java)] - [자료구조] LinkedList(연결 리스트) 이론 및 구현
[자료구조] LinkedList(연결 리스트) 이론 및 구현
이번 포스팅은 지난 포스팅에 이어 ArrayList에서 했던 것과 마찬가지로 LinkedList에서의 데이터 삽입, 데이터 삭제, 리스트 검색 등의 기능에 대해서 다뤄보도록 하겠습니다. LinkedList는 Node라는 객
cdragon.tistory.com
여러분이 컴퓨터와 전혀 상관없는 곳에서 아르바이트를 하고 있다고 가정해 봅시다.
그런데 만약 여러분이 맡은 일이 첫 방문한 새로운 회원을 받으면 그 회원의 신상 정보를 등록하는 것과 재방문 시 얼굴을 확인하여 방문 정보를 기록하는 작업이라고 합니다.
회원 정보를 저장할 수 있는 수단은 아래와 같은 12칸의 서랍 뿐입니다.
회원을 등록할 때에는 서랍을 하나하나 열어보면서 어느 칸이 비어있는 지 맨 앞의 칸부터 열어보면서 최대 12칸의 서랍을 열어봄으로써 확인을 해야 할 것입니다.
그리고 회원이 재방문 시 해당 회원의 정보가 어느 칸에 들어있는 지 확인하기 위해 또 다시 최대 12 칸의 서랍을 열어봄으로써 확인을 해야 하기 때문에 굉장히 불편합니다.
그래서 여러분들은 회원의 얼굴 정보에 따라 12가지 색 중 하나의 고유한 색깔을 찾아주는 프로그램을 만들 것입니다. 프로그램의 기능은 다음과 같습니다.
이와 같이 서랍을 하나하나 열어보지 않더라도 회원을 확인할 수 있으며, 서랍이 12칸이 아니라 100칸, 1000칸 ... 과 같이 점점 더 커질 때마다 이 프로그램의 효용성은 더 커지겠죠?
그런데 지금까지 예시를 들었던 것이 이게 hash와 무슨 연관이 있을지 궁금하실 겁니다.
그렇다면 이제 앞서 들었던 예를 우리가 배울 hash 자료 구조와 엮어서 설명해 보겠습니다.

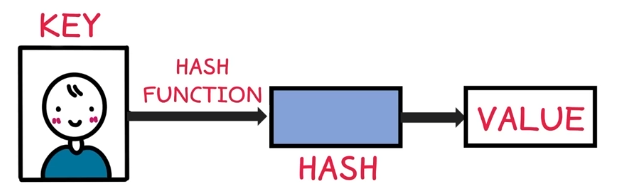
우리가 저장하고자 하는 정보는 value입니다. 그리고 이 정보를 구분할 수 있는 데이터를 key라고 정의합니다. key는 중복되지 않은 값을 사용해야 합니다.
앞서 설명했던 고유의 색깔을 찾아주는 프로그램은 Hash function이라고 하며, 이에 따라 나오는 output인 12가지 색 중 하나를 뜻했던 것은 해시 값(Hash Value)이라고 합니다. 그리고 이 해시 값을 인덱스화 해서 데이터를 저장하게 되는 것입니다.
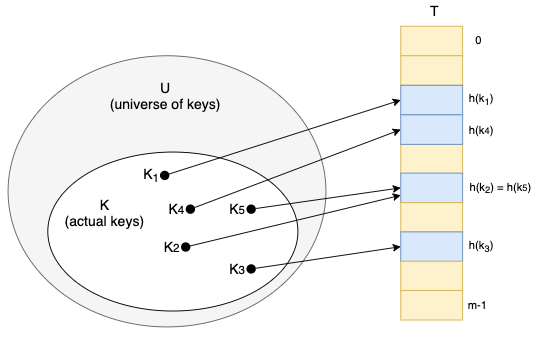
아래 해시 테이블 그림을 봅시다.
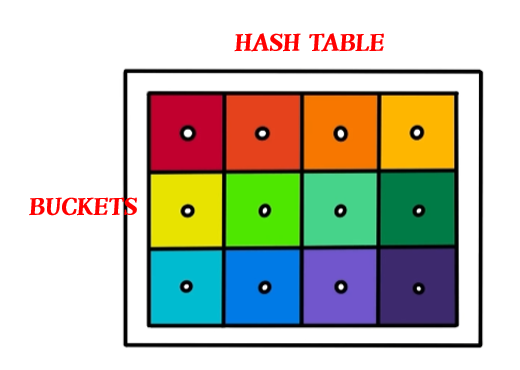
위 그림에서 Hash table은 해시 값을 인덱스화 해서 데이터를 저장하는 자료구조(서랍)를 뜻하며,
데이터가 저장되는 하나하나의 공간을 Buckets라고 합니다.
즉, 해시는 다음과 같이 설명할 수 있습니다.
해싱은 데이터를 빠르게 저장하고 가져오는 기법 중 하나로 키에 특정 연산을 적용하여 테이블의 주소를 계산하는데 이때, 특정 연산이 hash고 table이 hash table을 말하는 것입니다.
예를 들어, 'lion'이라는 문자열이 있다고 할 때 이 문자열을 특정 길이(e.g. 256bit, 512bit...)의 데이터로 변환시키는 과정입니다.
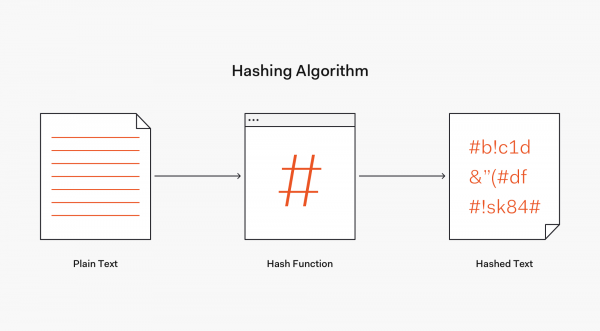
이러한 과정을 해싱('hashing')한다고 하며, 해시 함수를 통해 얻어진 값을 보통 다이제스트(digest)라고 합니다.
그렇다면 왜 굳이 이렇게 복잡한 해시 함수를 거쳐야 하는 지에 대한 의문이 들 것입니다.
우리가 이전에 배웠던 ArrayList, LinkedList, Stack, Queue 등의 자료구조들에서 '특정 값'을 찾기 위해 어떤 과정을 거쳤는지 생각해 봅시다.
배열 혹은 노드를 순회해 가면서 특정 값과 일치하는 것을 확인 했던 것이 기억 날 것입니다. 하지만 이 Hash Function을 이용한다면 이 과정을 굳이 거칠 필요가 없어집니다.
왜냐하면 같은 메세지(값)를 갖는 것이 보장되면 같은 다이제스트를 갖는 것 또한 보장 되기 때문입니다.
즉, 쉽게 말해서 위 이미지에서 특정 문자열을 hash 함수에 돌려서 얻은 값이 '#b!c1d&.....'와 같은 것인데 이는 고정된 값입니다. 그렇기 때문에 동일한 해시 자료구조를 사용하는 경우 동일한 값에 대해서는 무조건적으로 동일한 다이제스트를 얻게 된다는 것입니다.
해싱의 목적을 정리하면 다음과 같습니다.
해시 테이블(Hash table)이란?
검색하고자 하는 키값을 받아서 해시 함수(Hash function)를 통해 얻은 해시를 배열의 인덱스로 환산해서 데이터에 접근하는 자료구조입니다.
해시 테이블을 (Key, Value)쌍을 저장합니다. 그렇기 때문에 데이터 상에 순서가 존재하지 않는다는 특징이 있습니다.
다음 코드를 보면서 key, value 쌍을 간단히 이해해 보도록 합시다.
import java.util.HashMap;
import java.util.Map;
public class Main() {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("Hello", "World");
map.put("ABC", "DEF");
map.put("Computer", "Science");
System.out.println(map.get("Hello"));
System.out.println(map.get("DEF"));
System.out.println(map.get("Science"));
}
}
//World
//DEF
//Science위 코드는 Hash 자료구조를 사용하는 예시입니다.
put()을 통해 key와 value를 쌍으로 저장을 하고 출력을 할 때에는 get()으로 key값을 통해 value값을 출력해 낼 수 있습니다.
해시 테이블에서 value는 key를 기준으로 관리되기 때문에 key는 고유한 값을 가집니다. 특징은 다음과 같습니다.
회원 정보를 받을 때 이름을 key값으로 하면 되지 않나? 라는 의문을 가지실 수 있을 겁니다. 하지만 이름을 key값으로 할 때에는 동명이인이라는 변수가 존재하기 때문에 시스템 상의 혼돈을 일으킬 여지가 굉장히 많습니다. 그렇기 때문에 사람의 고유한 얼굴이나 주민등록번호를 key로 설정해야 하는 것입니다.
해시 함수는 임의의 길이의 키값을 고정된 길이의 해시로 변환해 주는 mapping function이다.
어떤 해시 함수를 사용하느냐에 따라 해시 검색의 성능이 결정되기 때문에 좋은 해시함수를 사용해야 한다.
좋은 해시 함수란?
좋은 해시 함수(hash function)는 키 값을 고르게 분포 시켜야 합니다. 이는 뒤에서 더 자세히 설명하도록 할 것입니다. 또한 해시 값을 계산해 주는 계산이 굉장히 빨라야 하고 충돌(collision)을 최소화 해야 합니다.
요약하면 다음과 같습니다.
충돌(collision)?
해시라는 자료구조에는 해시 충돌(Hash Collision)이라는 것이 존재합니다.(뒤에서 다시 중요하게 다루는 내용입니다.)
해시 테이블 크기보다 키의 갯수가 더 많기 때문에 두 개의 키가 동일한 slot에 hashing 될 수 있는데 이를 해시 충돌이라고 합니다.
예를 들어, 만약 한 집에 사는 가족 구성원이 회원등록에 시도한다고 가정해 봅시다. 그렇다면 이들의 얼굴 혹은 주민 번호는 분명히 다를 것이기 때문에 key값이 각자가 다 다를 것입니다. 하지만 주거지는 같기 때문에 value는 같은 값을 가지게 되는 상황이 발생하는 것과 같은 것입니다.
이후에 나올 내용이지만 해시 충돌은 자바에서 LinkedList를 이용한 'chaining' 방식을 통해 해결할 것입니다.
Hash function은 다양한 방법으로 구현할 수 있는데, (여러 알고리즘이 존재) 이 방법에 대해서 알아보도록 하겠습니다.
전달 될 paramter(인자) key 값에 나누어서 저장소의 크기를 인덱싱(indexing)하는 방식입니다.
이 방식은 충돌이 일어날 가능성이 많아 충돌에 대비한 추가적이 대책이 요구됩니다.
m : 7, k : 124
hash(k) = 124 % 7 = 5
효율적인 m선택 방법

접기(Folding) 방법은 검색 키를 분해하고 조합하여 해시를 만들어 내는 방법입니다. 접기에는 이동 접기(Shift folding)와 경계 접기(Boundary folding)가 있습니다.
이동 접기(Shift folding)

table size = 1000 (0 ~ 999) 3자리 - 키를 세 자리수로 분해합니다.
경계 접기(Boundary folding)

table size = 1000 (0 ~ 999) 3자리 - 키를 세 자리수로 분해합니다.
위 예제에서 붉은색 숫자 부분은 경계 부분으로 값을 역으로 정렬하여 더한 것입니다.
키 값을 제곱한 뒤에 나온 결과 값에 대해서 중간 부분에 있는 몇 비트만 선택하여 해시로 사용하는 방법입니다.
이때, 테이블 크기의 자릿수만큼 중간값을 가져오게 됩니다.

table size = 100 (0~99) 2자리 - 중간 2자리 수를 가져옵니다.
key 중에서 편중(한쪽으로 치우침)되지 않은 수들에 대하여 해시 테이블의 크기에 적합하게 조합하여 사용하는 방법입니다.
예를 들어, 10진수 숫자의 key를 16진수 등으로 바꾸듯이 다른 sequence로 indexing하는 방식입니다.
각 자리의 숫자를 상호 이동시키거나 거꾸로 돌리는 등의 작업을 해서 indexing하는 방식입니다.
이것들 외에도 다양한 좋은 hashing algorithm이 존재하며, 이러한 내용은 구글링을 한다던지의 방법을 통해 찾아보는 것이 더욱 도움이 될 것입니다. 각각의 내용은 이곳에서 더 깊이 다루지는 않겠습니다.
(여러분들이 여러분들만의 hash algorithm을 만들 수도 있습니다.)
그럼 Hash 자료구조에 대해서 Node를 이용하여 실습을 진행해 보도록 하겠습니다.
아래 코드를 보면 알 수 있듯이, MyLinkedHashTable은 key와 value를 받아 IHashTable을 구현상속하여 진행해 보도록 할 것입니다.
package hashtable;
public class MyLinkedHashTable<K,V> implements IHashTable<K,V> {
...
}노드를 사용하여 구현하기 때문에 노드 클래스를 만듭니다.
private class Node {
K key;
V value;
Node(K key, V data) {
this.key = key;
this.data = data;
}
}노드 클래스 안에는 노드 생성시 key와 value를 포함한 노드가 만들어지도록 생성자를 만들었습니다.
Hash를 구현하는데 필요한 멤버변수들을 선언합니다.
private List<Node>[] buckets;
private int size;
private int bucketSize;buckets 이라는 배열은 노드가 담기는 리스트를 객체로 담는 배열입니다.
그리고 size와 bucketSize를 각각 선언합니다.
생성자는 총 두 가지로 인자(parameter)를 받지 않는 것과 인자로 bucketSize를 받는 것이 있습니다.
private static final int DEFAULT_BUCKET_SIZE = 1024; //기본 bucket size
public MyLinkedHashTable() {
this.buckets = new List[DEFAULT_BUCKET_SIZE];
this.bucketSize = DEFAULT_BUCKET_SIZE;
this.size = 0;
for( int i = 0; i < bucketSize; i++) {
this.buckets[i] = new LinkedList<>();
}
public MyLinkedHashTable(int bucketSize) {
this.buckets = new List[DEFAULT_BUCKET_SIZE];
this.bucketSize = DEFAULT_BUCKET_SIZE;
this.size = 0;
for( int i = 0; i < bucketSize; i++) {
this.buckets[i] = new LinkedList<>();
}
}생성자에서는 위에서 선언한 멤버변수에 대한 초기화와 노드리스트 배열의 초기화가 이루어지게 됩니다. 배열을 초기화 할 때에는 빈 LinkedList 자료구조를 생성하여 하나씩 대입하는 식입니다.
hash table 구현에서 가장 중요한 것은 hash function입니다. 이번엔 hash function을 구현해 보도록 하겠습니다.
private int hash(K key) {
int hash = 0;
for (Character ch : key.toString().toCharArray()) {
hash += (int) ch;
}
return hash % this.bucketSize;
}return value : hash function에서는 나오게 되는 정수형의 index 값을 반환 할 것입니다.
코드를 보면 알겠지만 가장 보편적인 나눗셈 방법(Division method)를 사용하였습니다.
이제 이것들을 바탕으로 데이터를 넣는 작업을 진행해 보도록 하겠습니다.
@Override
public void put(K key, V value) {
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Node node : bucket) {
if (node.key.equals(key)) {
node.data = value;
return;
}
}
Node node = new Node(key, value);
bucket.add(node);
this.size++;
}
다음은 get() 함수입니다.
@Override
public V get(K key) {
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Node node : bucket) {
if(node.key.equals(key)) {
return node.data;
}
}
return null;
}
다음은 delete() 함수입니다.
@Override
public boolean delete(K key) {
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Iterator<Node> iter = bucket.iterator(); iter.hasNext();) {
Node node = iter.next();
if(node.key.equals(key)) {
iter.remove();
this.size--;
return true;
}
}
return false;
}
다음은 conains() 함수입니다.
@Override
public boolean contains(K key) {
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Node node : bucket) {
if (node.key.equals(key)) {
return true;
}
}
return false;
}contains() 함수는 key값을 받아 해당 key값이 buckets 안에 존재하는 지의 여부를 확인하는 것이기 때문에 위와 마찬가지로 bucket을 하나씩 가져오면서 해당하는 bucket(노드)이 인자로 받아온 key값과 일치하면 true를 리턴하고 그렇지 않으면 false를 리턴 하도록 합니다.
다음은 size() 함수입니다.
size() 함수는 간단하게 멤버 변수 size를 반환하면서 끝내주도록 합니다.
public int size() {
return this.size;
}
지금까지 해싱(hasing)에 대해서 알아보았으니, 상당히 중요한 해시 충돌에 대해서도 알아보도록 하겠습니다.
먼저 해시 충돌에 대해서 이해하기 위해서는 먼저 적재율(Load Factor)을 이해해야 합니다.
적재율이란 해시 테이블의 크기 대비, 키의 개수를 말합니다.
해시 테이블은 테이블의 크기가 키의 개수보다 작기 때문에 적재율이 1을 초과합니다. 그렇기 때문에 해시 충돌이 발생할 수밖에 없는것입니다.
만약, 충돌이 발생하지 않는다면 테이블의 탐색, 삽입, 삭제 연산은 모두 O(1)의 시간 복잡도를 요구하지만 충돌이 발생할 경우 충돌에 대한 추가 작업이 필요하게 되어 더 복잡한 시간 복잡도를 요구하게 될 수도 있습니다.
충돌은 해시 테이블 연산 효율을 떨어뜨리기 때문에 충돌을 최소화하는 것이 해시 테이블의 핵심입니다. 또한 위에서 배웠던 해시 함수를 통해 충돌을 줄일 수도 있습니다.
위에서 잠깐 말했듯이 같은 거주지에 살지만 분명히 다른 사람인 회원들이 등록을 한다고 가정할 때 key(얼굴,주민번호)값은 다르지만 value(주거지)는 같은 값일 때 발생하는 경우를 말한다고 했습니다.
이러한 해시 충돌은 프로그램 상의 혼란을 야기할 수 있기 때문에 최소화 시켜야 합니다. 여기서 최소화라고 한 이유는 해시 충돌을 줄일 수는 있지만 그 자체를 완전히 없애는 것은 거의 불가능에 가깝기 때문입니다.
Computer Science(CS)에서는 이 원리를 비둘기 집 원리로 설명합니다.

비둘기 집 원리는 "N+1 개의 물건을 N개의 상자에 넣을 때 적어도 어느 한 상자에는 두 개이상의 물건이 들어있다"라는 원리를 말합니다.
쉽게 말해서 앞서 보았던 hash table은 12칸이 다였지만 등록하려는 회원 수가 15명, 20명 과 같이 hash table의 수보다 더 많으면 모든 회원의 정보를 저장하기 위해서는 어느 서랍 칸에서는 반드시 2명 이상의 정보를 저장해야 하는 문제가 생깁니다.
hash table에서는 index의 수가 한정되어 있습니다. 하지만 우리가 사용 가능한 데이터의 key의 숫자는 hash table의 index 수보다 많고 hash function의 특성 상 무한대의 key 입력도 가능합니다.
따라서 해시충돌이 발생할 수 밖에 없는 구조를 설명하는 원리입니다.
이를 설명하는 하나의 문제가 더 있습니다. 바로 Birthday Problem(생일 문제)입니다.
이는 "임의의 사람 N명이 모였을 때 그 중 생일이 같은 두 명이 존재할 확률"을 의미하는 것으로 생일의 가능한 가짓수는 366개이지만(2월 29일 포함) 여기서 의문이 생길 수 있습니다.
"엥? 366명이 모여야 생일이 같은 경우의 수가 발생한다고?"
당연히 아닙니다. 실제로는 23명만 모여도 50.7%의 확률로 같은 생일인 사람들이 존재하고 50명인 경우 97%라고 합니다.
왜 이 확률이 나오는지에 대해서는 이곳에서 다루지 않겠습니다. 하지만 궁금하신 분들은 아래 링크를 걸어 둘테니 참고하면 되겠습니다.
그래서 결론은 key의 갯수가 hash table의 index수와 비슷한 수준까지는 아니더라도 충돌 가능한 확률은 생각보다 크다
라는 것을 말하고 싶은 것이고 이에 대한 솔루션이 반드시 존재해야 한다는 것입니다.
그렇다면 해시 충돌에 대한 솔루션은 어떤 것들이 있을까요?
그 방법(solution) 중 첫 번째로 chaining에 대해서 알아보겠습니다.
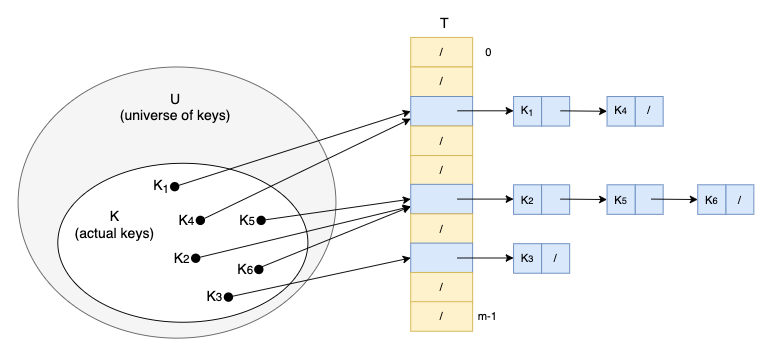
기존에 사용하던 구조에서는, 해시 주소 하나에 slot 하나가 mapping되어 이미 점유된 slot을 피해야 했습니다. 하지만 이는 점유된 슬롯을 피하지 않고, 그곳에 자료를 어떻게든 추가하는 방식으로 LinkedList를 이용하여 구현합니다.
메커니즘은 다음과 같습니다.
이 모습이 마치 chain이 연결된 것과 같다고 하여 chaining이라고 합니다.
이를 사용하면 항목을 탐색하거나 저장, 삭제 할 때 계산한 해시 주소에 해당하는 연결 리스트에서 독립적으로 수행되기 때문에, 수행 시간면에서 효율적이고 LinkedList로 구현하기 때문에 메모리 소모도 없습니다.
하지만 hash function으로 hash code값을 찾는데 O(1)의 시간복잡도가 걸리지만 index의 위치에서 해당 값을 찾기 위해 리스트를 하나 씩 탐색해야 하기 때문에 노드 연결이 길어질 수록 탐색 속도도 그 만큼 늘어나기 때문에 O(N)의 시간 복잡도를 가질 수 있고 이러한 이유로 최근 자바에서는 리스트 대신 트리라는 자료구조를 써서 시간복잡도를 줄일 수 있습니다.
아래 링크는 트리 자료구조 포스팅이니 참고하시면 좋을 것 같습니다.
[자료구조] Tree, Binary Tree(트리, 이진 트리)
이번 시간에는 트리 구조에 대해서 배워보도록 하겠습니다. 1. 트리(Tree)란? 트리란 노드들이 나무 가지처럼 연결된 비선형, 계층적 자료구조로 위 그림처럼 나무를 거꾸로 뒤집어 놓은 것과 같
cdragon.tistory.com
그렇다면 체이닝에 대한 자세한 내용을 살펴보겠습니다. 아래 그림을 보면,
해시 테이블 slot T[j]는 해시 값이 j인 모든 키를 연결 리스트로 저장하여 충돌을 해결합니다.
chaining의 기본 연산은 다음과 같습니다.
다음 그림은 chaining의 동작 예시입니다.
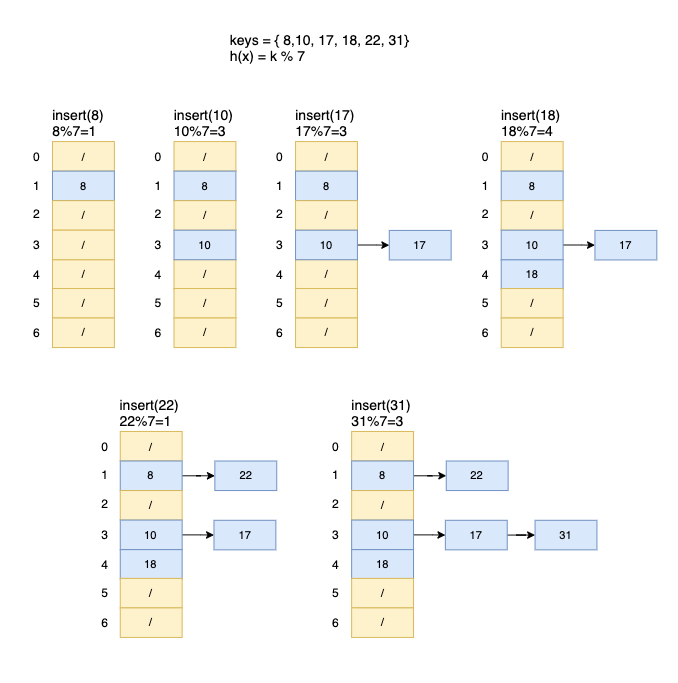
Division method(나눗셈 방식)로 hash function이 연산되어 만약 같은 값을 갖게 되면 LinkedList로 계속해서 데이터가 연결되어 충돌을 방지할 수 있습니다.
장점
단점
두 번째 방법은 open addressing 이다.
충돌이 발생할 경우, 다른 버킷에 데이터를 저장하는 방식입니다.
다시말해서 충돌이 일어난 키 값을 비어 있는 다른 주소를 찾아 저장하는 방법입니다. 모든 요소를 해시 테이블 자체에 저장하기 때문에 테이블의 크기는 키의 개수보다 반드시 크거나 같아야 합니다.
1) insert(key)
2) search(key)
3) delete(key)
근데 이때 다른 bucket을 어떻게 찾느냐에 따라 방법이 또 나뉘게 됩니다.
해시 충돌 시에 n칸을 건너뛴 버킷에 저장하는 방식입니다. 이 n은 1칸 혹은 2칸, 3칸... 이 될 수 있습니다.
아래와 같은 배열을 생각해 봅시다.

10번 index 부터 19번 index까지 있을 때 10번, 14번 ,18번 index에 데이터가 이미 들어 있다고 가정합시다.
근데 이때, 다른 key를 넣었는데 10번 index를 가리키는 hash값이 또 나오게 된다면 10번 index에는 이미 데이터가 있으므로 이를 건너 뛰고 다음 bucket인 11번 index에 값이 들어가게 되는 개념입니다. (n = 1인 경우)
그렇다면 각 연산에 대해 알아봅시다.
충돌이 발생하면 비어있거나(empty) 삭제된(deleted) slot을 발견할 때까지 index를 키워가며 탐색을 진행합니다.
만약 알맞은 위치를 발견하면 그곳에 key값을 삽입합니다.
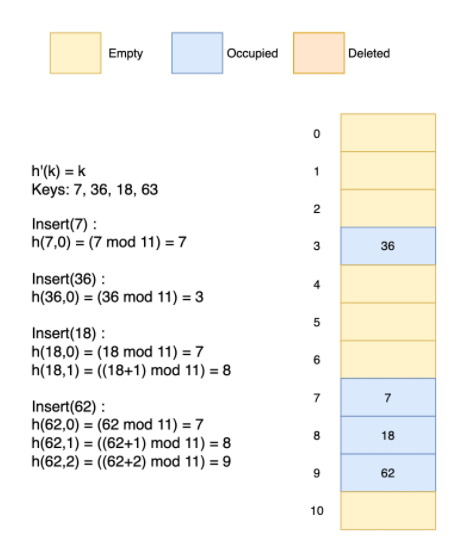
18의 key값에 입력을 할 때 18은 modulo연산(배열의 크기가 11인)에 의해 7이므로 앞에서 넣었던 7의 위치와 중복되어 이곳에 1이 더해진 8에 데이터가 들어간 모습입니다.
데이터의 추가는 이런 식으로 계속 진행되겠습니다.
삭제하기 위한 slot을 찾고 slot의 상태를 deleted로 변경합니다.
(중요!) 만약 deleted 표시를 하지 않고 삭제만 한다면 search를 했을 때 이 위치가 탐지가 되지 않는 경우가 발생할 수 있기 때문입니다.

검색은 키를 찾거나 빈 slot에 도달할 때까지 탐색을 계속합니다. 중간에 삭제된 slot이 있더라도 탐색을 멈추지 않습니다.

선형 탐색의 장점
선형 탐색의 단점
정리하면 선형 탐색은 다음과 같은 특징들을 갖습니다.
위의 선형 탐색의 단점인 clustering을 보완하기 위하여 제곱 탐색을 사용합니다.
제곱 탐색은 단순히 n번째 칸을 건너 뛰는 것이 아니라 N2칸(1,4,9,16,...)을 건너뛴 버킷에 데이터를 저장하는 것입니다.
즉, 충돌이 발생하면 2차 함수 꼴로 증가하면서 빈 slot을 계속해서 찾는 방식입니다.
이를 사용하면 데이터가 들어있는 bucket이 뭉쳐지는 현상(clustering)은 피할 수 있을 것입니다.
하지만 처음 hash function을 통해 나온 hash code값이 동일하다면 마찬가지로 건너 뛴 칸도 똑같기 때문에 여전히 n번의 탐색을 하게 될 수 있다는 문제가 여전히 존재합니다.
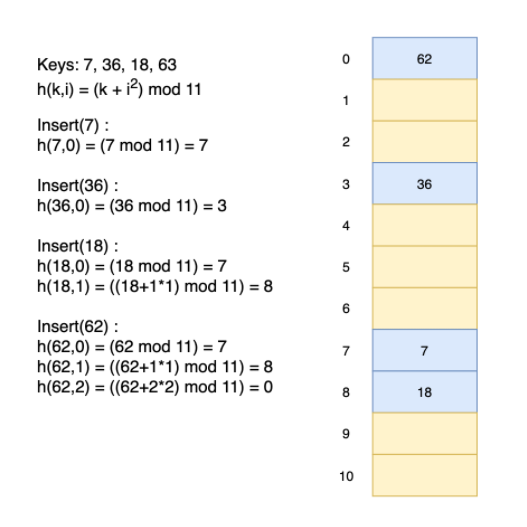
delete연산과 search 연산은 선형 탐색과 유사하기 때문에 생략하였습니다.
제곱 탐색의 장점
제곱 탐색의 단점
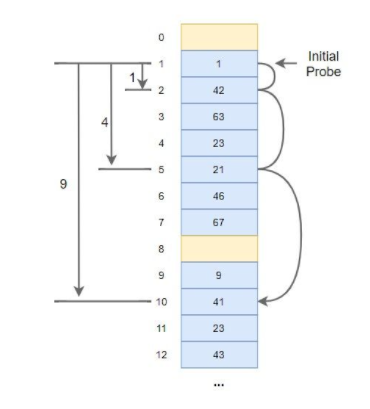
이를 해결 하기 위하여 나온 방법이 이중해시입니다.
이중 해시는 말 그대로 해시 값에 다른 hash function을 한 번 더 적용하는 것입니다.
이 때 첫 번째 해시함수와 두 번째 해시함수로 hash 값을 구하게 됩니다.
이 두 함수를 사용하면 최초의 hash값이 같더라도 이동 폭이 다르기 때문에 clustering(뭉쳐짐) 문제를 해결 할 수 있는 것입니다.
따라서 이 방법은 bucket을 탐색하는 데 있어서 규칙성을 완전히 없애버린 방법으로 볼 수 있습니다.
hash1(k) → 충돌 → hash1(k) + 1 * hash2(k) → 충돌 → hash1(k) + 2 * hash2(k) → 충돌 →hash1(k) + 3 * hash2(k) → ...
탐색 과정

이중 해시 또한 delete와 search 연산은 선형 탐색과 비슷하기 때문에 생략하였습니다.
주의점
이중 해시 장점
이중 해시 단점
Open addressing(개방 주소법)은 배열의 크기가 한정되어 있기 때문에 적재율(Load Factor)이 1 이하를 전제로 합니다.
또한, 계산 복잡성은 탐사 횟수에 비례하게 되는데 그렇기 때문에 search 횟수를 통해 시간 복잡도를 표현할 수 있습니다.
적재율을 α라고 했을 때 선형 탐색에서 시간 복잡도는 다음과 같습니다.
선형 탐색에서 적재율이 0.5 이상이 되면 unseccessful search 횟수는 급격하게 늘어나게 됩니다.
따라서 적재율이 0.5 이상이 되면 해시 테이블의 크기를 늘리는 등의 작업을 통해 적재율을 0.5 미만이 되도록 해야 합니다.
물론 제곱 탐색, 이중 해시도 적재율을 0.5 미만으로 유지하는 것이 좋겠습니다.
hash(해시) 와 관련된 문제로 백준 사이트의 1920번 수 찾기가 있습니다.
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | Θ(1) | Θ(n) | Θ(n) | Θ(n) |
| Stack | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Queue | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Singly Linked List | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Doubly Linked List | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Hash Table | Θ(1) | Θ(1) | Θ(1) | Θ(1) |
| Binary Search Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| AVL Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| B Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | O(1) | O(n) | O(n) | O(n) |
| Stack | O(n) | O(n) | O(1) | O(1) |
| Queue | O(n) | O(n) | O(1) | O(1) |
| Singly Linked List | O(n) | O(n) | O(1) | O(1) |
| Doubly Linked List | O(n) | O(n) | O(1) | O(1) |
| Hash Table | O(n) | O(n) | O(n) | O(n) |
| Binary Search Tree | O(log2n) | O(log2n) | O(log2n) | O(log2n) |
| AVL Tree | O(n) | O(n) | O(n) | O(n) |
| B Tree | O(log2n) | O(log2n) | O(log2n) | O(log2n) |
긴 글 읽어주셔서 감사합니다.
| [Algorithm | Java] 보간 탐색, 삼진 탐색, 지수 탐색(Interpolation, Terenary, Exponential Search) 알고리즘 (0) | 2022.12.28 |
|---|---|
| [Algorithm | Java] Binary Search(이진 탐색) 알고리즘 (1) | 2022.12.28 |
| [자료구조 | Java] Queue(큐)-선형 큐와 원형 큐 (1) | 2022.12.28 |
| [자료구조 | Java] Stack(스택) (0) | 2022.12.28 |
| [자료구조 | Java] Double LinkedList(이중 연결 리스트) (0) | 2022.12.27 |
소중한 공감 감사합니다