새소식
반응형
이번 시간에는 Stack 자료구조에 대해서 배워 볼 것입니다.
stack은 후입선출(Last-In-First-Out; LIFO)의 대표적인 선형 자료구조 중의 하나입니다.
후입선출이란 'Last-In-First-Out'이라는 뜻 그대로 '나중에 들어온 데이터가 가장 먼저 나간다' 의 의미를 가지고 있습니다.
그 예로 인터넷 브라우저에서 뒤로 가기 기능같은 경우 그 버튼을 눌렀을 때 가장 최근의 페이지가 나오는데 이 역시 가장나중에 들어간 페이지가 가장 먼저 나오는 것이기 때문에 스택 구조라고 할 수 있습니다.
또한, Ctrl + z 와 같은 실행 취소 기능역시 제일 나중에 했던 동작을 취소하는 것이므로 스택 구조라고 볼 수 있습니다.

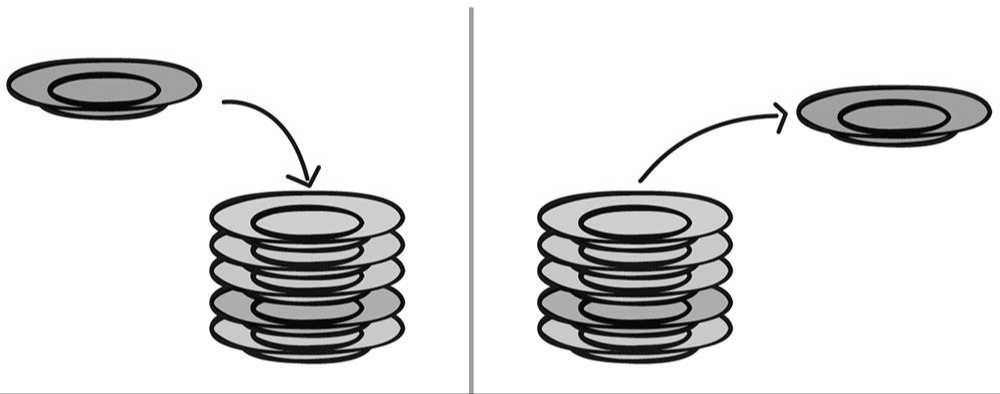
위 그림은 스택의 구조를 시각화한 자료입니다.
흔히 스택은 접시쌓기를 생각하면 이해하기 편합니다. 가장 마지막에 내려놓은 접시를 가장 먼저 빼야지 쌓아놓은 접시들이 무너지지 않겠죠?
이때, 접시(데이터)를 넣는 작업을 Push, 접시를 빼는 작업을 Pop이라고 부릅니다.
또한 스택은 완전히 꽉 찼을 때 Overflow상태라고 하고, 완전히 비어 있으면 Underflow상태라고 합니다.
그럼 연산 메소드에 대해 자세히 알아보겠습니다.
스택은 아래와 같은 연산 메소드들로 추상화할 수 있습니다.
push는 스택 구조에 데이터를 넣는 작업을 말합니다. push는 다음 과정으로 진행됩니다.
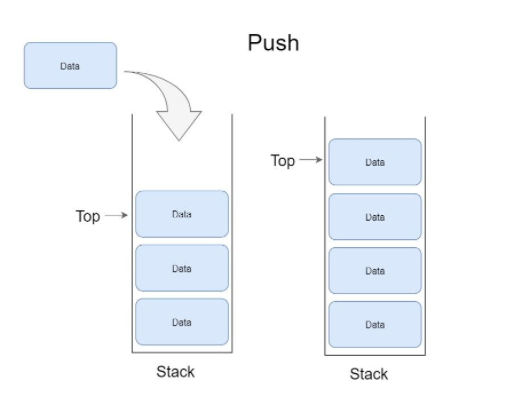
위의 그림처럼 Top은 항상 스택구조에서 위에 위치한 데이터를 가리키는 변수로 데이터를 뺄 때는 항상 top에서 빠지게 됩니다.
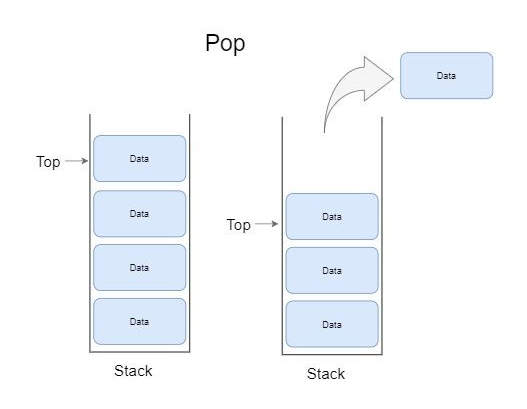
많은 사람들이 pop을 데이터를 제거하는 과정이라고 하는데 그것도 틀리지는 않지만 더 정확히 말하자면 추출이라는 표현에 더 가깝습니다. 실제로 pop메소드 실행시 제거한 데이터를 반환까지하기 때문에 제거라고만 하기엔 뭔가 2% 부족한 느낌입니다.
그렇다면 데이터를 꺼내서 가져오는 pop과정에 대해서 알아봅시다. 기본적으로 pop은 스택에 있는 데이터를 추출하여 가져오는 것으로 다음 과정을 거치게 됩니다.
| 연산 | 평균 소모 시간 | 최악 소모 시간 |
| Access | O(n) | O(n) |
| Search | O(n) | O(n) |
| Push (Insert) | O(1) | O(1) |
| Pop(Delete) | O(1) | O(1) |
스택에서 데이터의 삽입, 삭제, isEmpty, peek 연산은 모두 O(1)의 시간 복잡도를 갖습니다.
스택을 구현하는 방법에는 배열을 사용하는 방법과 LinkedList를 사용하는 방법이 있습니다.
장점
단점
장점
단점
포인터(노드)를 위한 추가 메모리 공간이 필요하다.
배열로 구현 시 순서가 중요하기 때문에 top이란 변수가 굉장히 중요하게 작용하지만 연결리스트로 구현 시 이 변수가 그렇게 중요하지 않습니다.
저는 자바의 강점을 살려 노드로 구현을 해 보도록 하겠습니다.
IStack.java
package stack;
public interface IStack<T> {
void push(T data);
T pop();
T peak();
int size();
}IStack이라는 interface에 push(), pop(), peak(), size() 메소드들을 정의하였습니다.
MyStack.java
package stack;
public class MyStack<T> implements IStack<T> {
...
}MyStack 클래스에서 IStack을 구현상속합니다.
private class Node {
T data;
Node next;
Node(T data) { this.data = data; }
Node(T data, Node next) {
this.data = data;
this.next = next;
}
}먼저 stack도 마찬가지로 노드를 기반으로 하여 구현할 것이기 때문에 지난 시간에 만들었던 Node 클래스를 가져옵니다.
지난 시간 포스팅 참조
[CS 지식/자료구조와 알고리즘(Java)] - [자료구조] LinkedList(연결 리스트) 이론 및 구현
[자료구조] LinkedList(연결 리스트) 이론 및 구현
이번 포스팅은 지난 포스팅에 이어 ArrayList에서 했던 것과 마찬가지로 LinkedList에서의 데이터 삽입, 데이터 삭제, 리스트 검색 등의 기능에 대해서 다뤄보도록 하겠습니다. LinkedList는 Node라는 객
cdragon.tistory.com
스택의 크기 변수와 head 노드를 멤버 변수로 선언합니다.
private int size;
private Node head;
위에서 선언한 멤버변수의 값을 초기화 시켜줍니다.
head 노드를 null로 초기화 시키는 것도 가능하지만 그렇게 되면 코드가 나중에 복잡해 질 가능성이 있기 때문에 새로운 null 노드 객체를 생성시켜 대입하였습니다.
public MyStack() {
this.size = size();
this.head = new Node(null);
// this.head = null; 코드가 복잡해 질 수 있다.
}
새로 push할 노드를 생성하는데 이 노드의 next pointer가 가리키고 있는 노드는 head노드의 next pointer가 가리키고 있던 노드를 가리키게 됩니다.
그 후 head 노드의 next pointer는 새로운 노드를 가리키게 해 주고, 스택의 크기를 1 증가시키면 됩니다.
이로써 head next pointer는 항상 새로 들어온 노드를 가리키는 것을 알 수 있습니다.
@Override
public void push(T data) {
Node node = new Node(data, this.head.next);
this.head.next = node;
this.size++;
}
@Override public T pop() {
if (this.isEmpty()) {
return null;
}
Node curr = this.head.next;
this.head.next = curr.next;
curr.next = null;
this.size--;
return curr.data;
}head노드의 next pointer가 가리키는 노드는 항상 스택 맨 위에 있는 노드(Top)이기 때문에 이를 curr 노드로 지정하고 head 노드의 next pointer를 curr 노드의 다음 노드와 연결합니다.
그 이후 curr 노드의 next pointer 연결을 null로 초기화 시켜 끊어주고 스택의 size를 1 감소 시킵니다.
pop()연산은 스택의 데이터를 삭제하면서 그 삭제한 데이터를 가져오는 것이기 때문에 curr의 데이터를 반환합니다.
단, 스택이 비어있는 경우 가져올 데이터 혹은 노드가 없기 때문에 반환할 객체가 없으므로 null 객체를 리턴합니다.
@Override
public T peek() {
if (this.isEmpty()) {
return null;
}
return this.head.next.data;
}peak() 연산은 스택의 구조를 건들이지 않고 가장 꼭대기의 값을 가져오는 것이기 때문에 head 노드의 next pointer가 가리키고 있는 노드(Top)의 data만을 그대로 return 하면 됩니다.
이 역시도 스택이 비어있는 경우에는 리턴할 객체가 없기 때문에 null을 반환해 줍니다.
@Override
public int size() {
return this.size;
}size()는 언제나 그랬듯이 간단하게 멤버변수 size를 리턴해 주면 됩니다.
이렇게 스택의 각 연산에 대해서 알아 보았다. 이 역시도 노드를 통해 이루어진 자료구조이지만 일반적인 연결리스트와는 데이터의 삽입, 삭제 방식(코드 구현)이 더 간편하다고 볼 수도 있습니다.
챕터 3에서 배운 스택과 관련된 풀어 볼 만한 문제는 백준 사이트의 9012번 괄호 문제가 있습니다.
이상 스택 자료구조에 대한 내용이었습니다.
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | Θ(1) | Θ(n) | Θ(n) | Θ(n) |
| Stack | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Queue | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Singly Linked List | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Doubly Linked List | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Hash Table | Θ(1) | Θ(1) | Θ(1) | Θ(1) |
| Binary Search Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| AVL Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| B Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | O(1) | O(n) | O(n) | O(n) |
| Stack | O(n) | O(n) | O(1) | O(1) |
| Queue | O(n) | O(n) | O(1) | O(1) |
| Singly Linked List | O(n) | O(n) | O(1) | O(1) |
| Doubly Linked List | O(n) | O(n) | O(1) | O(1) |
| Hash Table | O(n) | O(n) | O(n) | O(n) |
| Binary Search Tree | O(log2n) | O(log2n) | O(log2n) | O(log2n) |
| AVL Tree | O(n) | O(n) | O(n) | O(n) |
| B Tree | O(log2n) | O(log2n) | O(log2n) | O(log2n) |
| [자료구조 | Java] Hash(해시)와 Hash Collision(해시 충돌) (1) | 2022.12.28 |
|---|---|
| [자료구조 | Java] Queue(큐)-선형 큐와 원형 큐 (1) | 2022.12.28 |
| [자료구조 | Java] Double LinkedList(이중 연결 리스트) (0) | 2022.12.27 |
| [자료구조 | Java] LinkedList(연결 리스트) 이론 및 구현 (2) | 2022.12.27 |
| [자료구조 | Java] 리스트(List) - ArrayList (0) | 2022.12.27 |
소중한 공감 감사합니다