새소식
반응형
이번 시간에는 이진 탐색(Binary Search)에 대해서 알아보겠습니다.
정렬 알고리즘을 배우기 앞서 이진 탐색 내용이 공부가 되어있으면 편하기 때문에 우선은 이진 탐색 먼저 알아봅시다.
자료구조 및 알고리즘 강의 초반에 시간 복잡도를 설명하면서 이진 탐색에 대한 내용을 간단히 설명을 했었습니다.
다시 설명하자면 이진 탐색은 오름차순으로 정렬되어 있는 리스트 내에서 특정 값의 index를 찾는 알고리즘입니다.
만약 오름차순으로 정렬 되어 있지 않다면(혹은 내림차순) 반드시 다른 정렬을 사용해야 하는데 이때는 가장 단순하고 무식한 선형 탐색 방식을 사용합니다.
선형 탐색은 그저 배열의 처음 인덱스부터 마지막 인덱스 까지 순회하면서 일치하는 값이 될 때까지 반복하는 것으로 굉장히 구현 방식이 단순하기 때문에 자세한 설명은 하지 않겠습니다.
이진 탐색 알고리즘의 순서는 다음과 같습니다.
아래와 같은 리스트를 생각해 봅시다.

1부터 20까지의 숫자가 들어있는 리스트에서 특정 값의 위치를 찾는 방법 중 가장 효율 적인 방법은 어떤 것일까요?
숫자 7을 찾는다고 가정해 보면, 이때 low와 high라는 인덱스는 배열의 처음(1)과 끝(20)에 위치한 변수라고 합시다.
먼저 배열의 가운데를 결정한다.
숫자가 정렬되어 있는 것은 보장 받지만 리스트 안의 숫자가 모두 연속된 숫자(1, 2, 3, ...)라는 사실은 보장 받지 못합니다. 그렇기 때문에 리스트의 7번째 값을 가져온다고 해서 숫자 7을 가져오지는 못할 것입니다.
이진 정렬에서는 먼저 가운데 숫자를 확인합니다. 이 리스트에서는 11이라는 숫자가 될 것입니다.
mid = low + (high - low) / 2
= 0 + (13 - 0) / 2
= 7
이 리스트는 오름차순으로 정렬되어 있기 때문에 11이라는 숫자를 기준으로 더 작은 숫자는 왼쪽에 11보다 더 큰 숫자는 오른쪽에 있음을 보장 받습니다.
중앙 값과 검색 값을 비교한다.
우리가 찾고자 하는 7은 11보다 작기 때문에 11의 왼쪽에 있으므로 왼쪽 값을 기준으로 하여 다시 확인합니다.(7 < 11)
high = mid - 1
= 7 - 1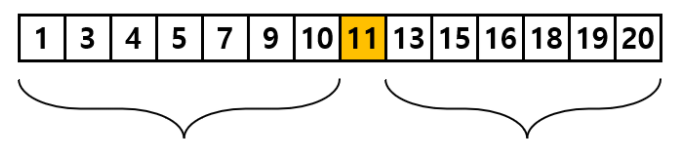
중앙 값을 다시 결정한다.
mid = 0 + (6 - 0) / 2
= 3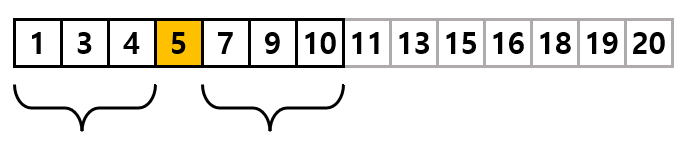
1부터 10까지 리스트에서 가장 가운데 숫자는 5입니다. 따라서 마찬가지로 5보다 왼쪽에는 5보다 작은 숫자가 오른쪽에는 5보다 큰 숫자가 있을 것입니다.
중앙 값과 검색 값을 비교한다.
A[3] < key 이므로 서브리스트의 오른쪽 구간을 다시 서브 리스트로 하여 탐색을 재진행합니다.
low = mid + 1
= 3 + 1
= 4
이를 반복한다.
다시 남은 리스트의 가운데 값을 확인해 보니 9가 나왔습니다.

여기서 다시 7은 9보다 작기 때문에 9의 왼쪽 남은 부분에서 탐색을 진행하여 7을 찾게 됩니다.
중앙 값과 검색 값을 비교한다.
A[4] = key 이므로 탐색을 종료합니다.
이처럼 한 번 탐색을 진행 할 때마다 값의 범위가 1/2씩 줄어들기 때문에 이진 탐색(binary search)이라는 이름이 붙여지게 된 것입니다.
이진 탐색의 종료 조건은 두 가지가 존재합니다. 다음 조건 중 하나라도 성립하면 탐색이 종료됩니다.
이제는 그럼 BinarySearch가 어떻게 동작하는 지에 대해 코드로 구현을 직접 해 봅시다.
package sort;
public class BinarySearch {
...
}위의 코드와 같이 BinarySearch 클래스에 구현을 하도록 하겠습니다.
public int search(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
int mid;
while(left <= right) { // 종료조건
mid = left + ((right - left) / 2);
if(arr[mid] == target) {
return mid;
}
if(arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}먼저 리스트의 양 끝을 나타내는 변수 left와 right을 선언 후 초기화합니다. 그리고 중간 값을 나타내는 mid 변수도 선언합니다.
반복문을 돌며 이진 탐색을 할 것인데 while문의 종료 조건은 left보다 right가 클 때, 즉 모든 arr의 데이터를 본 경우에 종료하기로 합니다.
중간 값인 mid에 중간 index를 넣기 위한 작업을 합니다. 이에 대한 수식은 아래와 같이 됩니다.
mid = (left + right) / 2
그러나 위와 같이 하면 변수 mid는 int형 변수이기 때문에 들어갈 수 있는 숫자의 범위가 존재하게 됩니다(-2^31 ~ 2^31). 그렇기 때문에 이 범위를 넘어가게 되면 overflowExeception이 발생 할 수 있습니다. 그래서 이를 막기 위하여
mid = left + ((right - left) / 2);와 같이 식을 표현해 준 것입니다.
이제 본격적으로 이진 탐색에 들어 가봅시다.
마지막으로 이 while문을 다 돌았는데도 arr[mid]값이 target값과 존재하지 않는다면 값을 찾지 못한 것이기 때문에 return 되지 않고 while문을 빠져나와 -1을 반환하게 됩니다.
| 연산 | Best | Average | Worst |
| Search | O(1) | O(log n) | O(log n) |
binary search는 한 번의 시행마다 우리가 봐야 하는 데이터의 크기가 1/2 씩 줄어든다는 특징 때문에 빠른 속도를 가질 수 있다는 장점이 있습니다.
이것이 시간 복잡도 O(N)을 갖는 것과 얼마나 차이가 있는 지를 계산 해보면 그 차이를 명확히 알 수 있습니다.
자료의 크기가 100이라면 앞에서 하나하나 탐색을 해서 찾으려면 최대 100번 만큼의 시간이 소요되는 반면,
binary search를 사용하면 log100의 값으로 대략 6.64 번 만에 찾을 수 있는 것입니다.
따라서 데이터의 크기가 커질 수록 이 차이가 훨씬 더 심해지기 때문에 그만큼 더 효율적이게 되는 것입니다.
하지만 binary search는 정렬된 조건 하에서만 사용 가능 하기 때문에 이러한 제약 조건 또한 존재합니다.
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | Θ(1) | Θ(n) | Θ(n) | Θ(n) |
| Stack | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Queue | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Singly Linked List | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Doubly Linked List | Θ(n) | Θ(n) | Θ(1) | Θ(1) |
| Hash Table | Θ(1) | Θ(1) | Θ(1) | Θ(1) |
| Binary Search Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| AVL Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| B Tree | Θ(log2n) | Θ(log2n) | Θ(log2n) | Θ(log2n) |
| 자료구조 | Access | Search | Insertion | Deletion |
| Array | O(1) | O(n) | O(n) | O(n) |
| Stack | O(n) | O(n) | O(1) | O(1) |
| Queue | O(n) | O(n) | O(1) | O(1) |
| Singly Linked List | O(n) | O(n) | O(1) | O(1) |
| Doubly Linked List | O(n) | O(n) | O(1) | O(1) |
| Hash Table | O(n) | O(n) | O(n) | O(n) |
| Binary Search Tree | O(log2n) | O(log2n) | O(log2n) | O(log2n) |
| AVL Tree | O(n) | O(n) | O(n) | O(n) |
| B Tree | O(log2n) | O(log2n) | O(log2n) | O(log2n) |
읽어주셔서 감사합니다.
| [Algorithm | Java] Jump Search(점프 탐색) (0) | 2022.12.28 |
|---|---|
| [Algorithm | Java] 보간 탐색, 삼진 탐색, 지수 탐색(Interpolation, Terenary, Exponential Search) 알고리즘 (0) | 2022.12.28 |
| [자료구조 | Java] Hash(해시)와 Hash Collision(해시 충돌) (1) | 2022.12.28 |
| [자료구조 | Java] Queue(큐)-선형 큐와 원형 큐 (1) | 2022.12.28 |
| [자료구조 | Java] Stack(스택) (0) | 2022.12.28 |
소중한 공감 감사합니다