1. 스토리지와 파일구조
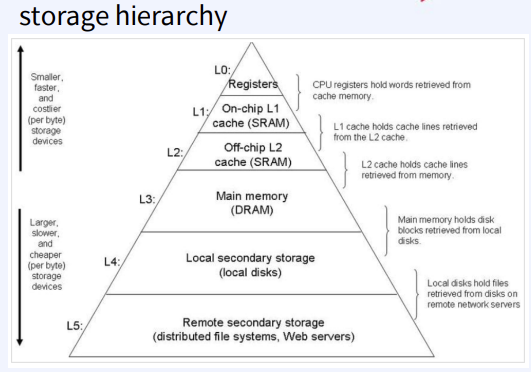
DBMS Storage
DBMS Storage
- DBMS는 데이터를 “hard” disk에 저장
- Disk access가 DBMS의 성능에 중요한 문제
- READ : disk -> main memory 데이터 전송
- WRITE : memory -> disk 데이터 전송
- higher cost than memory access
- Main memory에 모두 저장 못 하는 이유
- 비용문제
- 메모리에 저장된 데이터는 volatile
- 효과적인 memory – disk 데이터 전송을 위한 Buffer management 가 필요
DBMS Storage
Disk space management
- DBMS에서 가장 낮은 layer에서 disk의 space를 관리
- 상위 component에서 다음과 같은 request를 요청
- allocate & de-allocate a page
- read & write a page
- 성능을 위해 page들을 최대한 sequential 하도록 allocation 한다
- seek / rotation delay을 줄이기 위해
Buffer Management
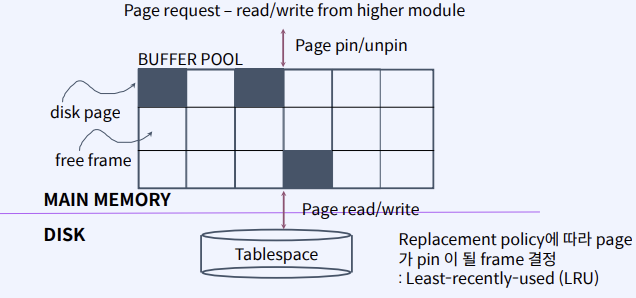
- Page buffering process
- Pool에서 page 을 저장할 frame을 선택
- free frame이 있으면 선택
- 없는 경우, replacement policy (LRU)에 의해 오래된 frame unpin 후에 frame 결정
- page을 disk에서 읽어 frame에 저장
- pin : pin_count++, page를 사용하는 사용자가 있음을 표시하기 위해
- pin_count가 0 인 경우만 replacement 대상
- 주소를 반환
- Page 사용자는 사용이 끝나면 page에 대한 unpin을 불러주어야 한다
- 만약 업데이트 경우 dirty flag set
- 읽는 pages list가 예측되면 성능을 향상 위해 prefetch 기능 제공
Format in File
Record formats: Fixed Length
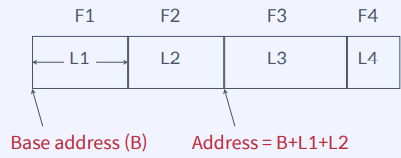
- Field 타입과 size에 대한 정보가 system catalog에 저장
- 필요한 Field access할 때 pointer 연산으로 빠르게 주소 반환
Page format for fixed length records
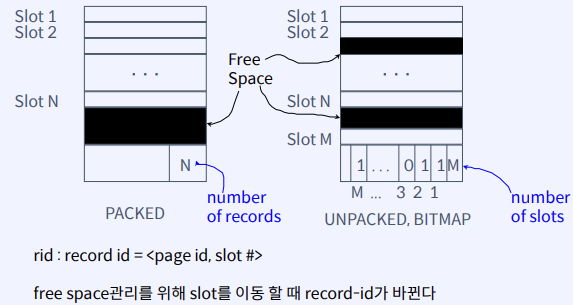
Format in File
Record formats: Variable Length
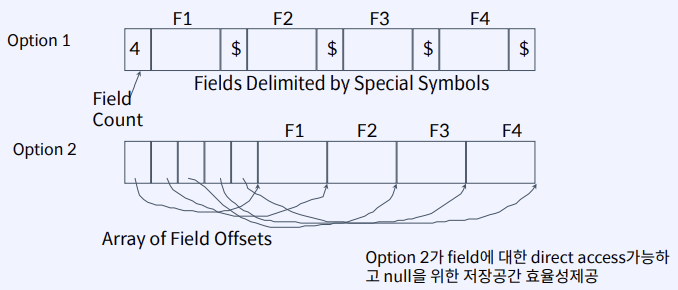
Page format for variable length records
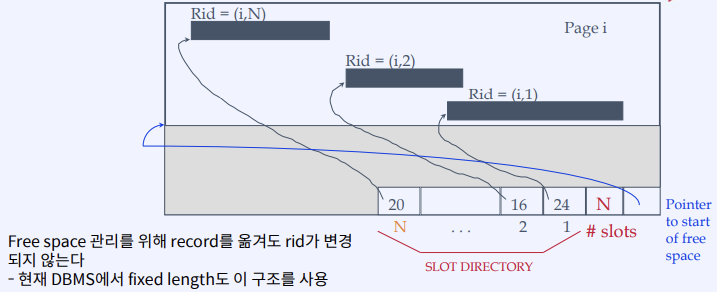
2. 인덱스 개념
인덱스
Indexes (indices)
- 특정 기준에 맞는 rows를 빠르게 찾기 위해 사용
- Index trade-off
- Search 성능 향상
- 인덱스를 관리하는 비용 발생
- DML성능 저하
- 인덱스를 저장하기 위한 space 사용 증가
- Search Key
- index에서 검색을 위해 사용되는 column 또는 column의 집합
- 한 테이블에서 다른 search key를 가지는 다수의 index가 생성 가능
인덱스를 만들 때 고려 사항
- 인덱스가 언제 사용될 것인가?
- 정확하게 key와 일치하는 row들을 찾을 때 사용할 것인가?
- Range query에 사용하나? (values between, >, <= 등)
- 테이블에 모든 row 들을 조회할 때 사용할 것인가?
- 테이블이 얼마나 자주 업데이트 되는가?
- DML은 index 관리를 위한 update가 발생
- 인덱스의 key가 super key인가 또는 primary key인가?
- 하나의 key로 여러 row 들이 가능한가? Unique or not
Tree (Ordered) Index vs. Hash Index
- Tree Index는 search key의 순서로 index entry가 정렬
- range query나 order by operation에 유리
- B+ Tree가 주로 사용
- Hash Index
- index entry의 위치를 hash function을 이용하여 bucket의 위치를 지정하여 저장
- search 에 효율성 : O(1)
- DML이 발생할 때 index 관리에 유리
인덱스
Index on SQL
- DBMS 다음의 경우에 index 를 생성한다
- Primary key
- unique constraint
- Create index statement in SQL
CREATE [UNIQUE] INDEX [using ]index_type : HASH, BTREE
ON (index_colomn_name, ...)
3. B+ Tree 인덱스
B+Tree
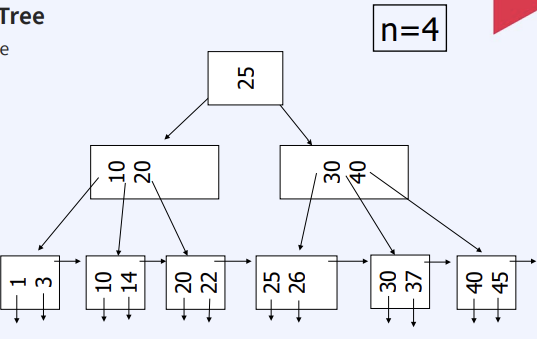
B+ Tree
- DBMS에 index로 사용되는 tree structure
- 같은 레벨의 모든 leaf모드에 key와 실제 data pointer 저장
- Components
- Root Node (적어도 두 개의 children을 가질 때)
- Non-leaf Node
- Leaf Node
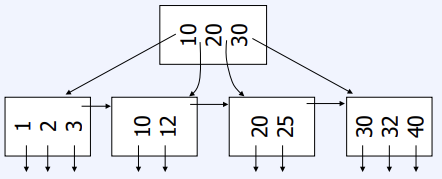
- 차수 n (Order n) 는 노드 사이즈을 결정한다
- size of Node = n + 1 pointers + n key
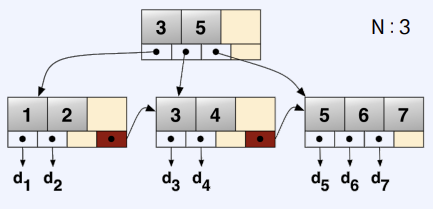
Insert into B+ Tree
- Simple case : Leaf Node에 공간이 있는 경우
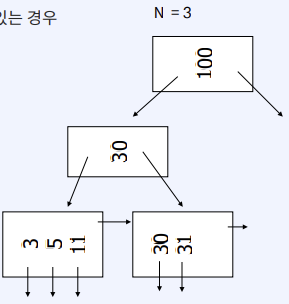
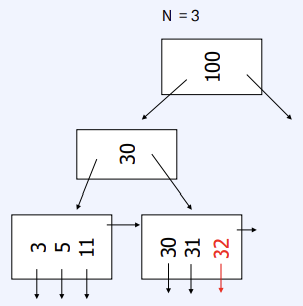
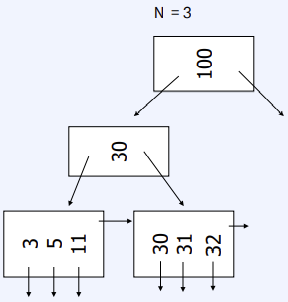
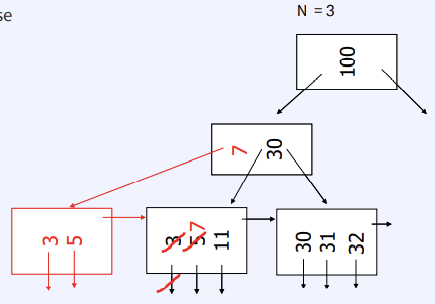
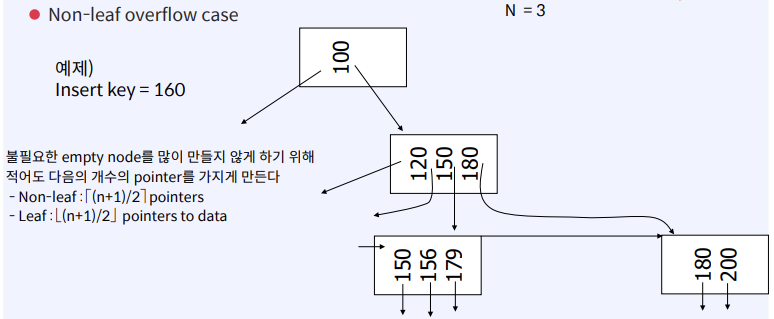
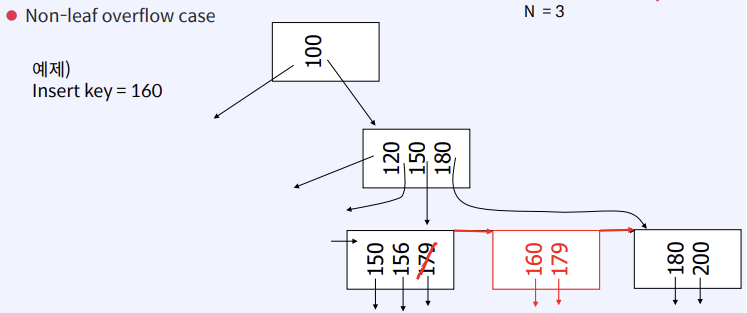
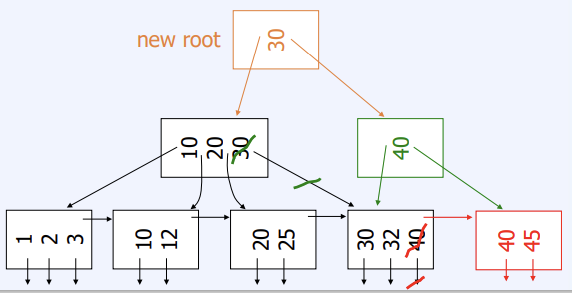
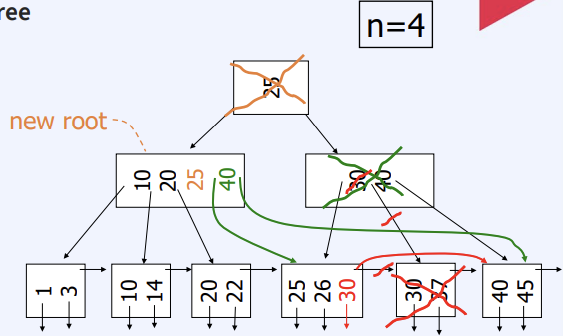
Delete from B+Tree
- Leaf node : Coalesce with sibling
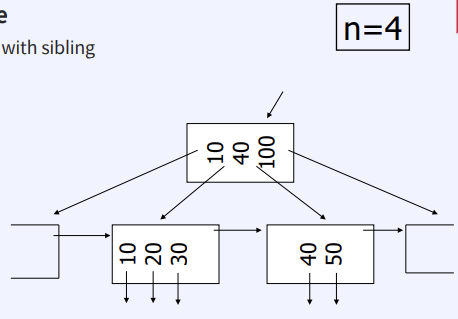
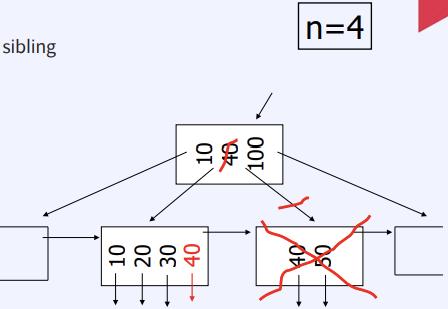
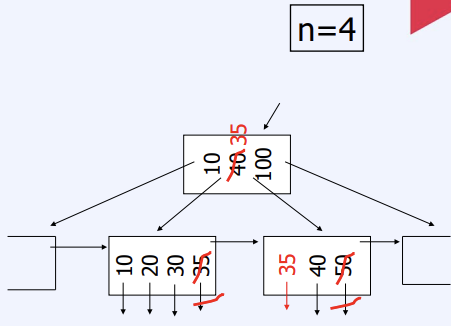
4. 해쉬 인덱스
해쉬인덱스
Hash Index
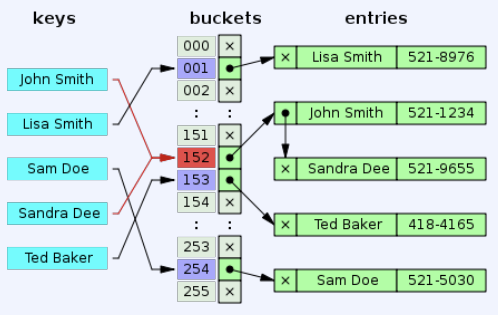
- key에 대한 hash function을 통해 데이터 위치를 찾는 index
- Index entry들이 bucket이라는 단위로 저장된다
- Bucket을 할당하는 방법
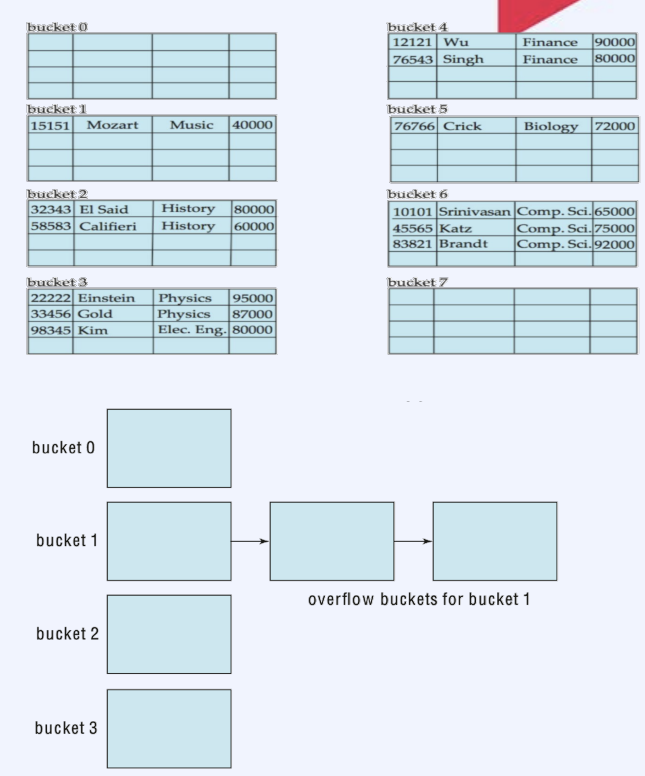
- static hashing
- Bucket을 고정 된 수로 할당
- dynamic hashing
- 데이터 양에 따라 가변적으로 bucket 을 늘려나간다
Static Hashing
- Hash function의 결과에 bucket수로 mod 연산하여 위치 결정
- Bucket수가 미리 정해져 있기 때문에 overflow 발생 가능
- Overflow chaining – linked list형태로 같은 hash key을 갖는 bucket을 연결한다
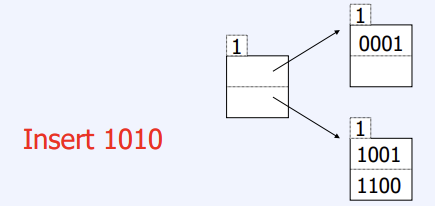
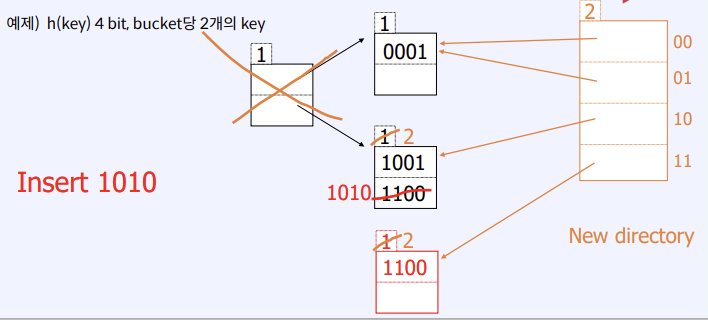
Dynamic Hashing - Extensible Hasing
- Static hashing과 달리 bucket수를 동적으로 변경하면서 hashing하는 방법
- Hashing function의 결과를 binary로 표현하여 bucket의 할당에 binary의 prefix을 사용
- if prefix = 0, 2^0=1 bucket
- if prefix = 1, 2 bucket , prefix =3, 2^3 = 8
- Bucket이 overflow가 발생하면 hash function의 prefix을 늘려가며 bucket의 개수를 늘 린다
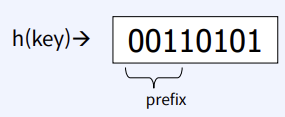
- 예제) h(key) 4 bit, bucket당 2개의 key