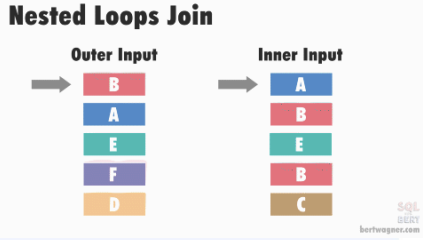
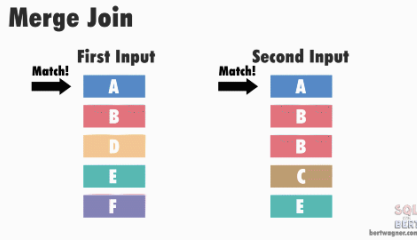
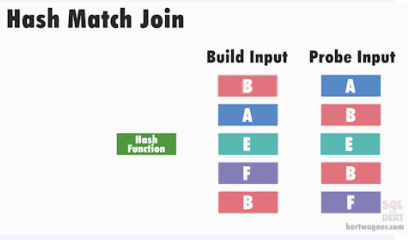
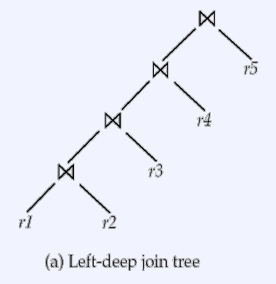
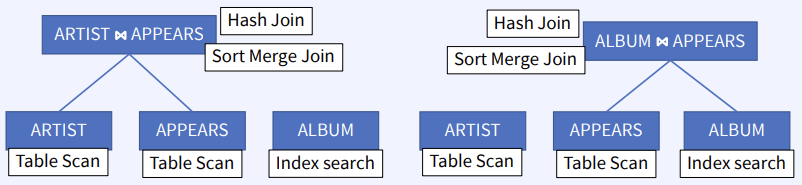
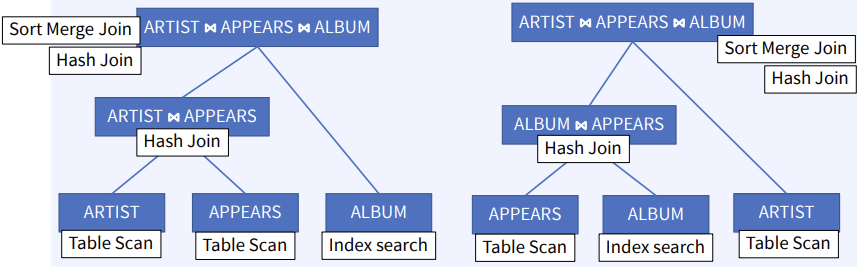
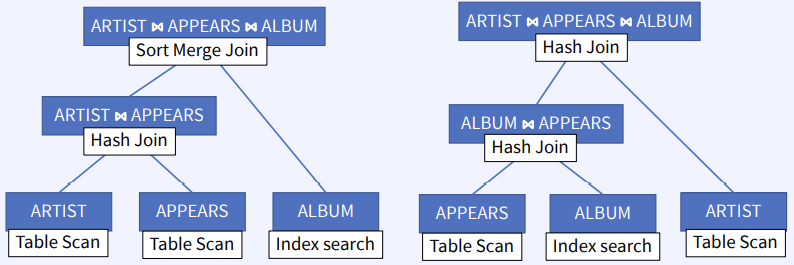
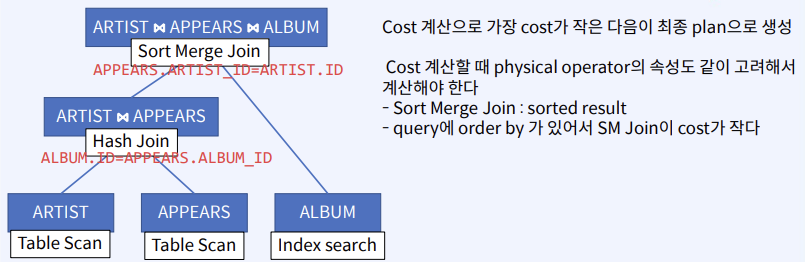
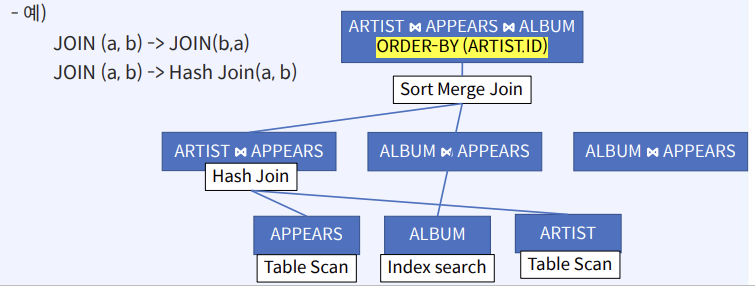
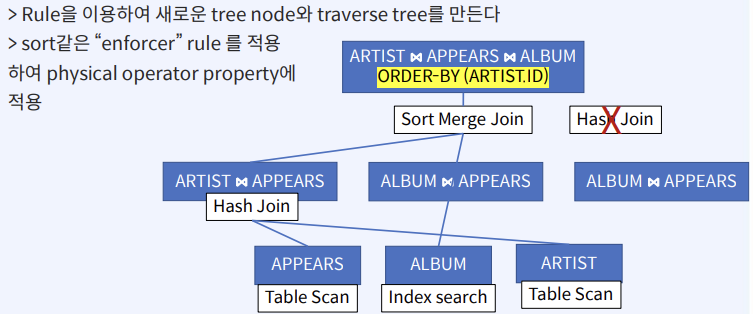
CS 지식/데이터베이스 [데이터베이스-simple버전] 9. 쿼리 프로세싱과 최적화(Query processing & Optimization) 2023.11.07 - 반응형 1. DBMS의 쿼리프로세싱 Query processing Query processing in DBMS Parser SQL 문장을 분석해서 syntax 체크 및 catalog을 이용해서 sematic check등을 하여 annotated AST 생성 Optimizer AST를 분석하여 execution plan을 생성 AST에 따라 가능한 execution plan리스트를 만들고 그 중에서 최저 비용을 가지는 execution plan 을 선택 Rule-Based Optimizer 미리 정해 놓은 rule에 따라 logical access 경로를 비교하며 최적의 plan을 생성 Cost-based Optimizer Plan의 각 실행 operator의 cost를 미리 정해놓고 예상 비용을 계산하여 최적의 plan을 선택 Query optimization on DBMS 좋은 DBMS는 query를 가장 효율적인 execution plan으로 변환하여 실행한다 better response time better throughput Query optimization은 DBMS 안에서도 가장 어려운 문제 (NP-Complete) 어떤 optimizer도 “optimal” plan 만 만들어 낸다고 보장할 수 없다 real plan cost를 추측하여 cost estimation 가능한 plans 수를 제한하기 위한 heuristics 방법을 사용 좋은 DBMS는 query를 가장 효율적인 execution plan으로 변환하여 실행한다 Cost estimation Resource utilization (CPU, Disk IO, network) Cost of algorithms and access methods Size of intermediate results Data statistics (skew, order, placement) Relational algebra equivalence 두 relational algebra expression이 같은 결과의 튜플 셋을 만들어 내는 경우 equivalent 하다고 한다 Example) Equivalence Rules 2. selection operators selection operators Selection Strategies Linear search – Full table scan 데이터가 저장된 모든 disk block의 access 필요 Binary search – (B+Tree Index) Exact matches Multiple matches Range queries Complex queries Index를 이용한 search는 index access를 위한 disk block access 와 실제 data block access가 필요 일반적인 query에서 전체 full table scan에 비해 access 횟수가 훨씬 적다 Join Strategies Join의 경우 세 가지 형태로 execution plan이 만들어 진다 Nested loop join 조인을 순차적으로 수행하면서 데이터에 random access Inner table에 조인을 위한 index 필요 cost = Outer table cardinality access count of Inner table block Merge Join (Sort Merge Join) 데이터에 랜덤하게 액세스하지 않고 스캔을 하면서 수행 양쪽 테이블 처리 범위를 각자 접근해 정렬한 결과를 차례대로 스캔 인덱스가 존재하지 않고 조인 연산자가 “=” 가 아닌 경우 좋은 성능을 보임 Hash Join 내부적으로 hash table를 만들어서 수행 두 테이블 중에 작은 테이블에 대해 hash table 생성 큰 테이블을 스캔하면서 hash table를 조회 하며 join하는 방식 hash table 생성 cost가 추가 되기 때문에 한 join대상 테이블이 작을 때 유리 3. Optimizer - 1 Optimizer - 1 Heuristic-based optimization Optimizer of INGRES of Stonebraker and Oracle (1990년초 이전버전) Logical operator를 physical plan으로 바꾸는 static rules를 이용한다 가장 제한적인 selection을 먼저 수행한다 Join 전에 모든 selection을 수행한다 Predicate/Limit/Projection은 push down Cardinality을 기준으로 join ordering Paper : Query Processing In A Relational Database Management System Heuristic + Cost based optimization Static rule로 initial optimization을 수행한다 좋은 join ordering을 결정하기 위해 dynamic programming을 수행한다 첫번째 cost-based query optimizer divide-and-conquer 방식을 이용한 Bottom-up planning System R, 초기의 IBM DB2, 대부분의 open source databases 들이 이 방식을 이용 Paper : Access path selection in a relational database management system Heuristic + Cost based optimization System R optimizer query을 blocks 들로 나누고 각 block을 위한 logical operator들을 생성 각 logical operator을 위한 physical operator의 모든 가능한 join path 와 access path의 조합을 set으로 생성 반복적으로 cost를 계산하면서 가장 cost가 작은 plan의 left-deep tree을 만든다 Example of Heuristic + Cost based optimization Step 1 각 테이블에 대한 가장 좋은 access path을 고른다APPEARS : Sequential Scan ALBUM : Index on NAME ARTIST : Sequential Scan Step 2 가능한 모든 join ordering을 나열한다 Step 3 join ordering 중에 가장 cost가 작은 것으로 >선택 Example of Heuristic + Cost based optimization Example of Heuristic + Cost based optimization Example of Heuristic + Cost based optimization 4. Optimizer - 2 Optimizer - 2 Top-down vs. Bottom-up Top-down Optimization 최종 logical plan을 가지고 plan tree를 내려가며 alternative plan과 비교하며 cost 를 계산하여 optimal plan을 계산 Volcano, Cascades Bottom-up Optimization 아무것도 없는 상태에서 시작해서 plan을 시작부터 만들어 가면서 원하는 최종 plan을 만드는 방식 System R, Starburst Volcano Optimizer Relational algebra의 equivalence rule을 기본으로 하는 cost-based optimizer이다 새로운 operator과 equivalence rule를 추가하기 쉽다 branch-and-bound 방법을 사용하여 top-down방식으로 optimal plan을 고른다 일단 logical plan에 대한 가능한 physical plan을 고르고 그 다음 alternative plan들 을 찾아 비교 MEMO table를 이용하여 equivalent operator를 저장 Cascade optimizer : Object-oriented implementation of Vocano SQL server 에서 사용 Step 1 실행을 원하는 logical plan에서 optimization 시작 Step 2 > Rule을 이용하여 새로운 tree node와 traverse tree를 만든다 예) JOIN (a, b) -> Hash Join(a, b) JOIN (a, b) -> JOIN(b,a) 결론 Optimizer에 의한 query optimization은 매우 어려운 문제 ”optimal” 한 plan을 찾아내는 건 NP-complete 문제로 DBMS는 heuristic과 지정된 cost값을 이용 DBMS 들은 optimizer의 역할을 보완하기 위한 기능 제공 SQL Hint Plan Stability (저장된 old 버전의 plan 사용 반응형 공유하기 URL 복사카카오톡 공유페이스북 공유엑스 공유 게시글 관리 구독하기개발자로 살아남기 Contents 1.DBMS의쿼리프로세싱 Queryprocessing QueryprocessinginDBMS QueryoptimizationonDBMS Relationalalgebraequivalence EquivalenceRules 2.selectionoperators selectionoperators SelectionStrategies JoinStrategies 3.Optimizer-1 Optimizer-1 Heuristic-basedoptimization Heuristic+Costbasedoptimization Heuristic+Costbasedoptimization ExampleofHeuristic+Costbasedoptimization ExampleofHeuristic+Costbasedoptimization ExampleofHeuristic+Costbasedoptimization ExampleofHeuristic+Costbasedoptimization 4.Optimizer-2 Optimizer-2 Top-downvs.Bottom-up VolcanoOptimizer 결론 당신이 좋아할만한 콘텐츠 [데이터베이스] RDBMS를 활용한 데이터베이스 설계 및 최적화 2024.09.03 [데이터베이스-simple 버전] 10. 데이터베이스 최신기술 2023.11.07 [데이터베이스-simple버전] 8. 스토리지와 인덱스 2023.11.07 [데이터베이스-simple버전] 7. 트랜잭션 시스템 2023.11.07 댓글 0 + 이전 댓글 더보기