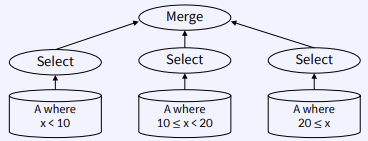
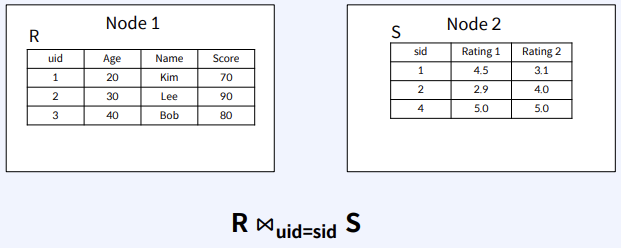
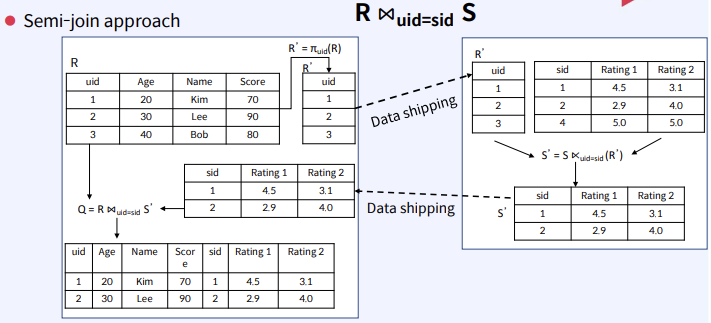
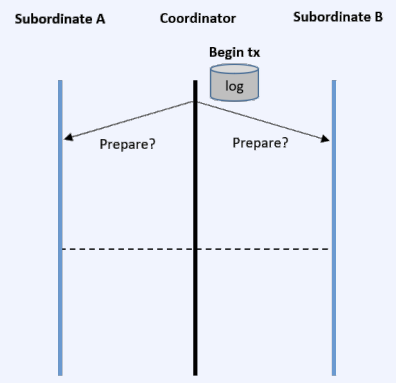
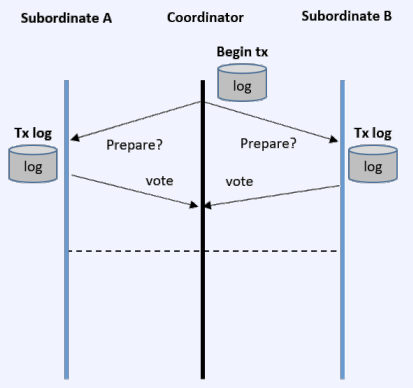
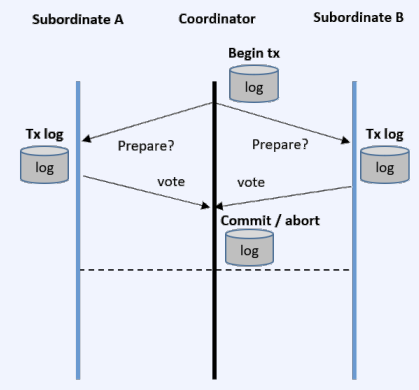
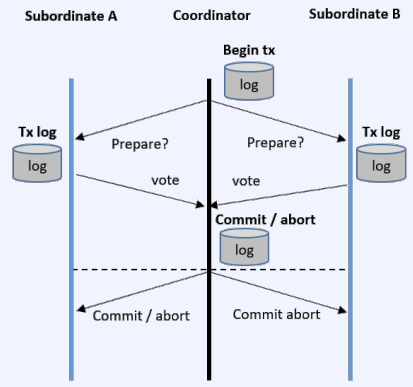
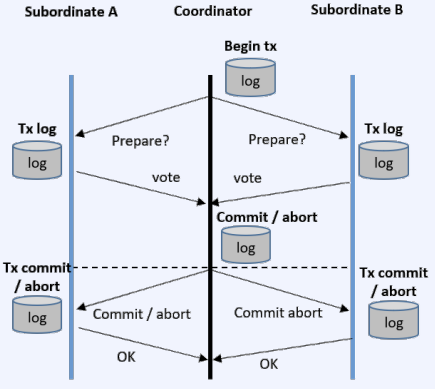
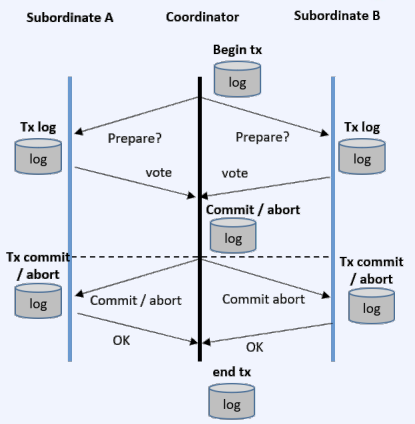
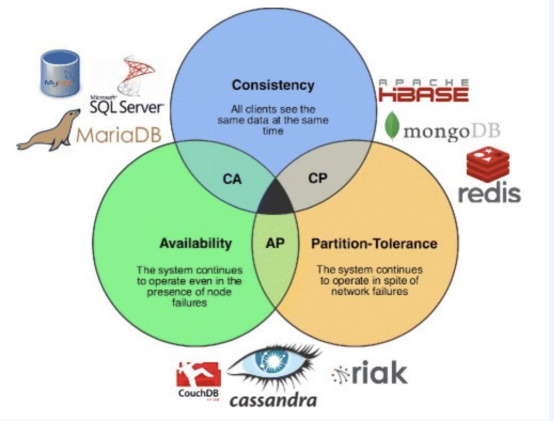
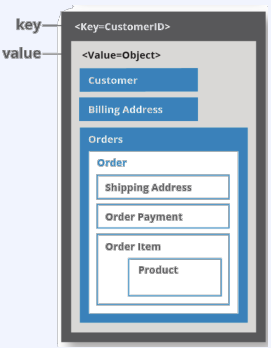
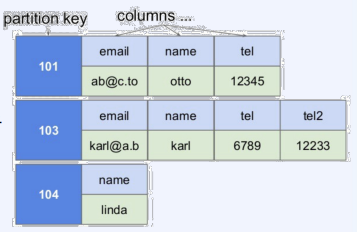
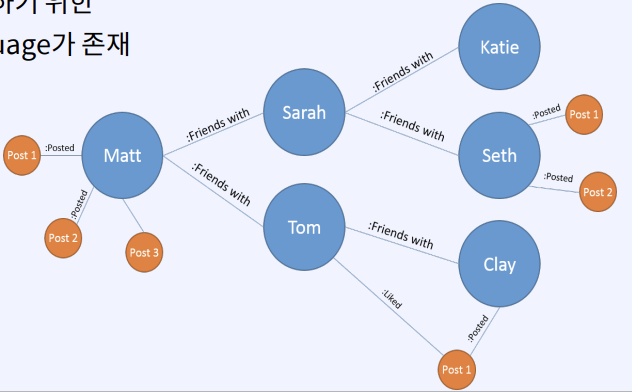
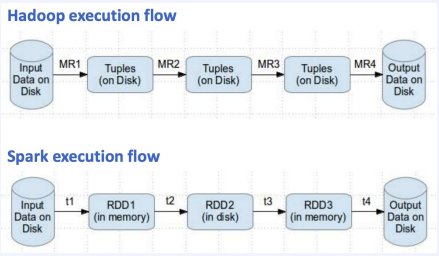
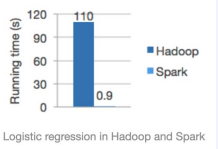
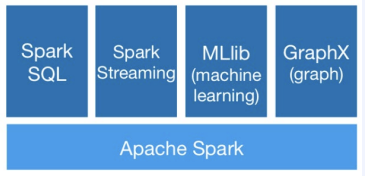
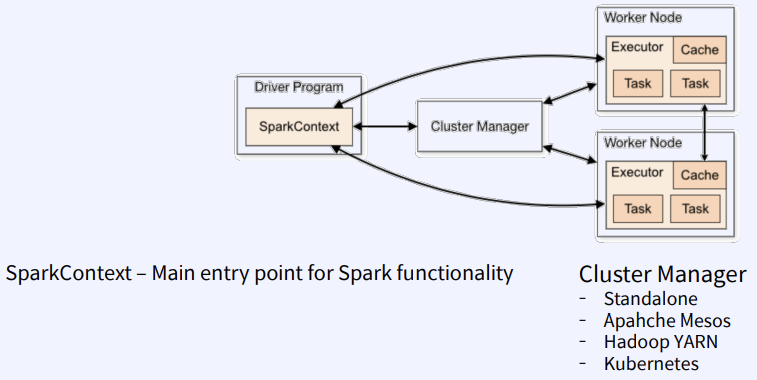
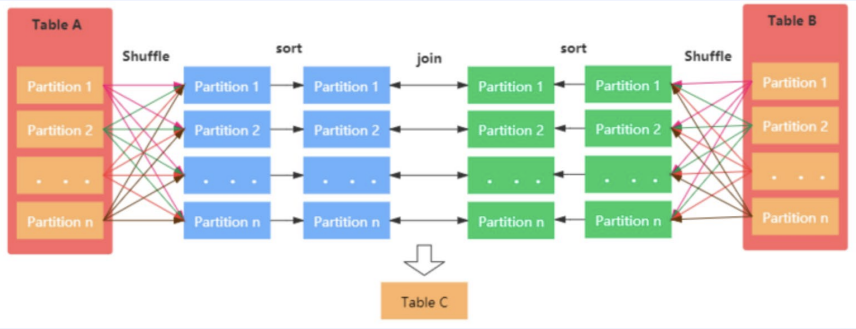
CS 지식/데이터베이스 [데이터베이스-simple 버전] 10. 데이터베이스 최신기술 2023.11.07 - 반응형 1. 분산데이터베이스(Distributed Database) - 1 분산 데이터베이스 데이터가 다른 physical location에 저장되는 데이터베이스 분산 데이터베이스의 장점 Fault tolerance High performance Low cost 해결해야 할 이슈들 data 분산 분산 데이터를 활용한 병렬처리 Distributed Transaction / Distributed Locking Semi join Distributed Database 분산 데이터베이스의 종류 Homogeneous distributed database 각 distributed node에 같은 종류의 DBMS 가 실행 Heterogeneous distributed database 각 distributed node에 다른 종류의 DBMS가 실행 Federated database 라고도 함 데이터 분산 Replication 전체 테이블의 copy를 distributed nodes에 저장 가용성 (availability) 향상 query 실행 향상 synchronous vs. asynchronous Fragmentation 전체 테이블을 분할을 해서 저장하는 방식 Horizontal vs. Vertical Partitioning 전략 Hash partitioning 특정 컬럼의 값을 hashing 함수를 통해 나오 location id로 row를 분산 load balancing을 위한 똑같이 row을 분산하고자 할 때 사용 Range partitioning 특정 컬럼의 값 또는 값의 범위에 따라 특정 partition을 결정 Round-robin partitioning 각 partition에 똑같이 분산하고자 할 때 사용. Hash와 같이 특정 column이 필요 없음 Parallelism in Distributed Database Pipelining : 여러 operation들을 중첩하여 실행시키는 기술Temp <- Select * From A where cond. Result <- Join Temp and B Ex. Concurrent execution : 각각 node에서 동시에 실행 된 결과를 mergeT1 <- Select * From A where cond Ex. Distributed Queries Horizontal Fragmentation (row가 다른 노드에 저장) – 파란색 각 노드에서 SUM(age)와 Count(age)을 연산한 다음 그 결과로 AVG(age)을 연산 Vertical Fragmentation - 빨간색 score노드에서 where절 연산 결과에 따른 rid로 age가 있는 노드에서 AVG 연산 Replication : 모든 노드가 같은 데이터 cost를 고려해서 노드 선택 2. 분산데이터베이스 (Distributed Database) - 2 Distributed Database Distributed Join Naïve approach 두 테이블 중에 작은 사이즈의 테이블을 옮겨 local node에서 조인한다 전체 테이블을 copy하거나 page-wise로 데이터를 옮겨온다 문제점 데이터를 옮기는 cost가 크다 모든 데이터가 옮겨지기 때문에 shipping cost가 full table scan cost와 같다 Semi-join approach Semi-join R ⋉ S : 조인 후에 조인 컬럼에 포함되지 않는 S의 컬럼을 삭제 이 조인 operator을 이용하여 shipping되는 dataset을 줄이는 방법 Distributed Transaction Multi node에 거친 transaction에 대한 commit을 할 때 사용하는 atomic commitment protocol 2 phase commit Prepare phase Coordinator가 참여자들에게 precommit을 하도록 하고 그 결과 (commit or abort) vote를 받는 단계 Commit phase 모든 참여자 노드들이 precommit이 끝나고 commit 준비가 되면 coordinator 가 commit or rollback를 결정하여 실제 commit를 하는 단계 2PC protocol Coordinator가 "begin transaction" 로그를 기록 Coordinator가 참여자들에게 "prepare" msg를 보낸다. 각 참여자들은 자기 노드의 업데이트가 있으면 "prepare" transaction log를 기록한다 각 참여자들은 coordinator에게 commit 결과에 대한 "vote" msg를 보낸다. Coordinator는 모든 참여자들에게 “vote” msg 받고 commit/rollback 결정하여 log 기록 Coordinator는 모든 참여자들에게 commit/abort msg 보냄 참여자들은 commit/abort 로그를 기록 참여자들은 ok msg을 coordinator에게 보냄 Coordinator는 모든 참여자들로부터 “ok” msg을 받은 후에 ”end transaction” log 기록 하여 commit을 끝냄 Protocol중간 단계에서 만약 fail이 발생하면 되면 coordinator는 참여자들에게 abort msg 전송 3. NoSQL 데이터베이스 NoSQL NoSQL Database 우리가 지금까지 배운 데이터베이스는 RDBMS (Relational database) RDBMS는 데이터의 ACID 속성을 가장 중요시하고 Entity(table)간의 referential constraint 등 테이블의 schema가 미리 정의 Big data등 data set이 클 때 distributed database가 제안되긴 했지만 scalability 에 이슈가 있음 NoSQL (Not only SQL) DBMS의 제공하는 일부 기능(Consistency)을 포기하고 대신 단순한 그러나 확장성이 좋은 구조를 제공 – Distributed 데이터에 대한 Schema를 지정하지 않기 때문에 쉬운 확장성 제공 SQL에 유사한 query language 제공 CAP theorem을 사용하여 ACID 속성 중의 일부를 완화 NoSQL Database CAP theorem 분산시스템에서 다음과 같은 세가지 조건을 모두 만족하는 시스템을 존재할 수 없음을 증명한 정리 C(Consistency) : 모든 노드들이 같은 시점에 같은 값을 볼 수 있다 (또는 에러) A (Availability) : 모든 request는 에러 없이 response를 받을 수 있다. (최신 값을 return함은 보장 안함) P (Partition tolerance) : network partition이 나서 message의 분실이 발생해도 시스템이 계속 동작해야 한다 NoSQL은 consistency와 availability을 동 시에 제공하지 않는다 - 불가능 NoSQL 이 더 좋은 경우 NoSQL 데이터베이스는 very large semi-structured data 를 처리하는 애플리케이션 에 적합 – Log Analysis, Social Networking Feeds, Time-based data.. 더 큰 데이터 볼륨을 처리하고 대기 시간을 줄이고 처리량을 개선하는 몇 가지 조합을 통해 데이터 액세스 성능을 개선 복잡한 relationship이 있는 테이블이 있는 경우 JOIN을 제공하지 않기 때문에 적합하지 않음 Key-value store Free-from values (simple primitive types, string 또는 JSON document)까지 저장하고 key을 통해 조회 가장 간단한 구조 – eventual consistency 또는 serializability 의 consistency model제공 Example CouchDB, Redis, Dynamo, Azure Customs DB 사용 예제 ) session 정보 제공, 사용자 profile 등 Wide-column store (column family database) RDBMS 와 비슷하게 wide-column store 도 table ,column, row 개념을 사용 RDBMS와 차이점 각 rows가 다른 column list를 가질 수 있다 Two-dimensional key-value store로 생각할 수 있음 Example AWS DynamoDB, Cassandra, Google Bigtable Document store JSON같은 semi-structured data 인 document를 저장/조회하는 데이터베이스 Key-value store의 하위 클래스 Key-value store와 달리 데이터베이스 내부에서 최 적화를 지원하기 위해 document가 가진 metadata 정보 이용 Example MongoDB, Azure CosmosDB, Azure DocumentDB MongoDB example Graph database 데이터를 node, edge 및 property를 가지고 graph structure를 이용하여 저장하는 데이터베이스 Graph에서 데이터를 효율적으로 쿼리하기 위한 graph데이터베이스 전용 query language가 존재 Cypher, Gremlin Example) - Neo4j, Infinite Graph 4. Spark Spark Why Spark? MapReduce 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작 된 소프트웨어 프레임워크 각 stage의 output을 disk에 저장됨에 따라 성능이 좋지 않음 대부분의 머신러닝 알고리즘은 반복적으로 실행함으로써 더 좋은 결과를 만들어가는 방식으로 iterative하게 반복 수행 Spark 2009년 UC Berkeley에서 개발 Matei Zaharia, Databricks 의 CTO Fast and general purpose cluster computing system for large-scale data processing 10x (on disk) ~ 100x (in-memory) 빠른 성능 Iterative machine learning algorithm 수행하는 엔진으로 많이 쓰임 High level APIs로 JAVA, Scala, Python 제공 Integration with Hadoop eco-system like hive-metastore http://spark.apache.org/ Spark Stack Spark는 SQL, DataFrame, Mlib, GraphX 및 spark streaming을 포함한 라이브러리 스택을 지원 Spark SQL SQL 와 unstructured data processing MLib Machine Learning Algorithms GraphX Graph Processing 라이브러리 Spark Streaming live data streaming processing 위한 라이브러리 Spark Execution Flow RDD Resilient Distributed Dataset의 약자 여러 분산 노드에 걸쳐서 변경이 불가능한 objects(데이터)의 집합 변경을 위해서는 새로운 RDD을 생성해야 한다 RDD에 속한 요소들은 파티션으로 나누어 지고 Spark는 파티션 단위로 병렬 처리 수행 Lineage : Spark는 RDD를 생성 작업을 기록 Fault Tolerant : Proccessing중 장애가 발생했을 때 이 정보를 가지고 re-create Lazy Evaluation RDD에 실제 데이터 로딩은 action을 실행할 때 일어난다 lines.count() – 실제 파일을 읽어서 RDD로 만듬 lines = sc.textFile(“README.md”) 두 가지의 operations만 제공한다 Transformation : RDD데이터를 변경하여 새로운 RDD 를 생성 Narrow Transformation : 각 partition이 partition을 생성 map, filter, join, union 등 Wider Transformation : multi partition들을 가지고 computation이 필요 groupByKey(), join(), reduceByKey() Shuffle : partition의 executor node 간 이동 Action : RDD의 데이터를 기반으로 계산 결과를 생성 count(), collect(), forEach() Spark Join Strategies Broadcast Hash Join Join 대상 테이블 중에 작은 테이블이 있는 경우 사용 No shuffling cost Steps Broadcast Stage : 작은 테이블을 모든 executor에 cache Hash join Phase : 각 executor 노드에서 hash join 후에 결과 merge Spark Join Strategies Sort Merge Join Default join 방법 두 개의 큰 테이블 Join에 일반적으로 사용하는 방법 Steps Shuffle Phase : join key에 따라 두 테이블의 데이터 를 분산하여 partition을 만드는 과정 Sort Phase : 각 partition의 데이터를 Sort Merge Phase : Sort된 partition을 traverse하면서 merg 반응형 공유하기 URL 복사카카오톡 공유페이스북 공유엑스 공유 게시글 관리 구독하기개발자로 살아남기 Contents 1.분산데이터베이스(DistributedDatabase)-1 분산데이터베이스 DistributedDatabase 분산데이터베이스의종류 데이터분산 Partitioning전략 ParallelisminDistributedDatabase DistributedQueries 2.분산데이터베이스(DistributedDatabase)-2 DistributedDatabase DistributedJoin DistributedTransaction 2PCprotocol 3.NoSQL데이터베이스 NoSQL NoSQLDatabase NoSQLDatabase NoSQL이더좋은경우 Key-valuestore Wide-columnstore(columnfamilydatabase) Documentstore Graphdatabase 4.Spark Spark WhySpark? Spark SparkStack SparkExecutionFlow RDD SparkJoinStrategies SparkJoinStrategies 당신이 좋아할만한 콘텐츠 [데이터베이스] RDBMS를 활용한 데이터베이스 설계 및 최적화 2024.09.03 [데이터베이스-simple버전] 9. 쿼리 프로세싱과 최적화(Query processing & Optimization) 2023.11.07 [데이터베이스-simple버전] 8. 스토리지와 인덱스 2023.11.07 [데이터베이스-simple버전] 7. 트랜잭션 시스템 2023.11.07 댓글 0 + 이전 댓글 더보기