새소식
반응형
[프로젝트] - [kakao tech bootcamp] 카카오 테크 부트캠프 챗봇 프로젝트(피카부) - 1
[kakao tech bootcamp] 카카오 테크 부트캠프 챗봇 프로젝트(피카부) - 1
카카오테크 부트캠프(카테부) 챗봇, "피카부"는 카카오테크 부트캠프에서 진행한 팀 미션으로부터 시작된 프로젝트입니다. 카카오테크 부트캠프에서는 각 과정별로(풀스택, 인공지능, 클라우
cdragon.tistory.com
지난 포스팅에서 카테부 챗봇인 "피카부(Pikaboo)" 프로젝트에 대한 내용을 정리하였습니다. 이번 포스팅에서는 개발을 진행하면서 발생했던 트러블 슈팅과 개인적으로 최적화를 진행했던 내용에 대해서 정리해보려 합니다.


이번에 진행했던 프로젝트에서는 사용자의 경험에도 신경을 썼기 때문에 AI의 응답을 스트림 방식으로 받아오면서 이를 보여줄 때, 단어별로 끊어서 업데이트 되도록 구현을 진행하였습니다.

저희는 RAG(Retrieval-Augmented-Generation) 기술로 GPT가 응답하기 직전에 문서를 뒤져보는 프로세스가 진행되기 때문에 시간이 더 오래 걸리게 됩니다. 그러한 이유로 AI의 응답이 전부 만들어질 때까지 기다렸다가 전체 텍스트를 보내는 동기 방식으로 진행했을 때, 사용자가 첫 응답을 마주하게 되기까지는 약 5초의 시간을 기다려야 했습니다.
이는 사용자 경험(UX) 측면에서 봤을 때 사용자가 아무런 행동도 하지 못하고 5초를 기다린다는 것은 굉장히 좋지 않은 설계라고 보기 때문에 stream 형식으로 응답을 받아 메시지의 내용을 청크 단위로 업데이트 시켜 첫 응답까지의 시간을 줄일 수 있는 스트림 방식을 채택하게 된 것입니다.
초기에 이러한 기능을 프론트엔드 단에서 구현하려고 했으나, 아직 백엔드 API가 스트림 응답을 적용하기 전이었기 때문에 Next.js에서 직접 openai의 gpt api를 호출하여 stream 옵션을 true로 설정한 응답으로 미리 구현을 진행해 보았고 큰 문제 없이 구현을 할 수 있었습니다.
그런데 문제는 백엔드 API가 완성되어 백엔드 응답을 사용하면서부터 생겼습니다.

분명 GPT api의 응답을 사용했을 때는 왼쪽 사진과 같이 잘 돌아갔었는데, 백엔드 API의 응답을 사용하였더니 동일한 코드가 동작하도록 구현했음에도 위 사진과 같이 중간에 특정 단어들이 생략되어 나오는 문제가 발생하는 것이었습니다.
백엔드 api가 응답을 하는 방식은 다음과 같습니다.
먼저 기존에 GPT api를 가져와서 사용했던 코드를 살펴보도록 하겠습니다.
const response = await fetch("/api/gpt", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt: content }),
});
if (!response.ok) {
throw new Error("Failed to fetch AI response.");
}
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let done = false;
let aiResponse: AIResponse = {
chatMessageId: Date.now(), // Temporary ID for AI response
content: "",
isUser: false,
};
while (!done) {
const { value, done: streamDone } = (await reader?.read()) ?? {};
done = streamDone!;
const chunk = decoder.decode(value, { stream: true });
if (chunk.trim() !== "") {
const jsonChunks = chunk
.split("\n\n")
.filter((c) => c.startsWith("data: "));
for (const jsonChunk of jsonChunks) {
const jsonStr = jsonChunk.replace("data: ", "");
if (jsonStr === "[DONE]") {
done = true;
break;
}
try {
const json = JSON.parse(jsonStr);
const content = json.choices?.[0]?.delta?.content;
if (content) {
aiResponse.content += content;
// Update local state (initial data store) as the response streams in
setInitialData(1, {
...aiResponse,
});
}
} catch (error) {
console.error("Failed to parse chunk:", error);
}
}
}
}// api/gpt
// GPT API를 받아 응답을 넘겨줄 때 text/event-stream으로 넘겨줌
return new NextResponse(response.body, {
headers: {
"Content-Type": "text/event-stream",
},
});
위 코드에서 특이한 점은 일반적은 json 형태의 응답을 받는 것이 아니라 event-stream 형태의 응답을 받기 때문에 response를 받아 getReader()로 스트림 값을 읽어 디코딩 하여 내용을 파싱하는 과정이 추가가 되어 굉장히 복잡한 형태를 띄고 있는 것을 볼 수 있습니다.
코드를 한 부분씩 살펴보도록 하겠습니다.
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let done = false;
let aiResponse: AIResponse = {
chatMessageId: Date.now(),
content: "",
isUser: false,
};
응답 본문(response.body)에서 데이터를 읽을 reader를 설정합니다. 또한 스트림 데이터를 텍스트로 변환하기 위해 TextDecoder를 생성합니다.
done 변수는 스트리밍이 끝났는지를 확인하는 변수이며, aiResponse 객체는 스트리밍이된 AI의 응답 데이터를 저장합니다.
while (!done) {
const { value, done: streamDone } = (await reader?.read()) ?? {};
done = streamDone!;
const chunk = decoder.decode(value, { stream: true });
if (chunk.trim() !== "") {
const jsonChunks = chunk
.split("\n\n")
.filter((c) => c.startsWith("data: "));
while 루프를 통해 스트림이 완료(done)될 때까지 데이터를 읽어들입니다. reader.read()를 호출하여 읽은 데이터를 반환받으며, 여기서 value는 읽은 바이트 데이터를, streamDone은 스트림이 끝났는지의 여부를 표현합니다.
TextDecoder를 사용해 value를 텍스트로 디코딩하며, 이 때 스트림 모드를 true로 설정하여 중간 결과도 처리할 수 있게 합니다.
응답 스트림은 보통 여러 데이터 조각으로 나뉘어서 전달되며, 여기서는 데이터를 두 개의 개행문자("\n\n")로 구분하고 `data: `로 시작하는 유효한 JSON 데이터를 필터링합니다.
for (const jsonChunk of jsonChunks) {
const jsonStr = jsonChunk.replace("data: ", "");
if (jsonStr === "[DONE]") {
done = true;
break;
}
try {
const json = JSON.parse(jsonStr);
const content = json.choices?.[0]?.delta?.content;
if (content) {
aiResponse.content += content;
// Update local state (initial data store) as the response streams in
setInitialData(1, {
...aiResponse,
});
}
} catch (error) {
console.error("Failed to parse chunk:", error);
}
}
해당 for문에서는 위에서 처리한 조각인 jsonChunks에 대해 순회하면서 각 JSON 조각을 처리합니다.
jsonChunk에서 "data: " 부분을 제거한 후, 내용이 "[DONE]"이면 스트림이 끝났다는 의미이므로 done을 true로 설정하고 루프를 종료합니다.
이후 JSON 데이터를 파싱하여 응답에서 AI가 반환한 내용(delta.content; gpt api의 응답 포맷)을 추출합니다. 이 내용이 만약 존재한다면 aiResponse.content에 계속 덧붙여 저장합니다.
AI의 응답이 들어올 때마다 setInitialData 함수를 호출하여 로컬 상태를 실시간으로 업데이트합니다. 이로 인해 사용자는 AI의 응답을 스트리밍으로 단어 별로 끊어서 확인할 수 있습니다.
그럼 이제 문제를 해결한 코드를 살펴보면서 무엇이 문제였는지 확인해보겠습니다.
const response = await fetch(
`${process.env.NEXT_PUBLIC_API_URL}/chats/me/new`,
{
method: "POST",
headers: {
"Content-Type": "application/json",
},
credentials: "include",
body: JSON.stringify({ content }),
}
);
if (!response.ok) {
throw new Error("Failed to fetch AI response.");
}
const reader = response.body!.getReader();
const decoder = new TextDecoder("utf-8");
let buffer = "";
let done = false;
let aiResponse: AIResponse = {
chatMessageId: Date.now(),
content: "",
isUser: false,
};
while (!done) {
const { value, done: streamDone } = await reader.read();
done = streamDone;
buffer += decoder.decode(value || new Uint8Array(), {
stream: !done,
});
let lines = buffer.split("\n");
for (let i = 0; i < lines.length - 1; i++) {
const jsonStr = lines[i].replace("data:", "").trim();
if (jsonStr) {
try {
const aiJson = JSON.parse(jsonStr);
const {
type,
chatId: rchatId,
content,
chatMessageType,
title: rtitle,
} = aiJson.aiResponse;
if (rchatId && rchatId) {
chatId = rchatId;
}
if (type === "DONE") {
done = true;
break;
}
// if (chatMessageType === "TITLE") {
// title = rtitle;
// }
if (!content) {
break;
}
aiResponse.content += content;
setInitialData(1, {
content: aiResponse.content,
isUser: false,
chatMessageId: Date.now(),
});
} catch (error) {
console.log("Failed to parse chunk:", error);
}
}
}
buffer = lines[lines.length - 1];
}
return chatId;
} catch (error) {
console.log("Error during fetching:", error);
throw error;
}
if (!response.ok) {
throw new Error("Failed to fetch AI response.");
}
const reader = response.body!.getReader();
const decoder = new TextDecoder("utf-8");
let buffer = ""; // buffer 선언
let done = false;
BEFORE 코드와 유사하지만 여기서 buffer 변수가 주요한 역할을 하게됩니다.
buffer는 스트림에서 받은 데이터를 저장해두는 임시 공간으로 활용됩니다.
while (!done) {
const { value, done: streamDone } = await reader.read();
done = streamDone;
buffer += decoder.decode(value || new Uint8Array(), { // 버퍼에 저장
stream: !done,
});
let lines = buffer.split("\n"); // 청크 분리
for (let i = 0; i < lines.length - 1; i++) {
const jsonStr = lines[i].replace("data:", "").trim();
if (jsonStr) {
try {
const aiJson = JSON.parse(jsonStr);
const {
type,
chatId: rchatId,
content,
chatMessageType,
title: rtitle,
} = aiJson.aiResponse;
reader.read()를 사용하여 스트림에서 데이터를 읽어오고, 스트리밍이 완료되었는지 여부를 done 플래그로 확인합니다.
응답 받은 데이터를 decoder.decode()로 UTF-8 문자열로 변환하여 buffer에 저장합니다.
스트리밍 데이터는 개행(\n)을 기준으로 나누어 lines 배열에 저장됩니다. 이 부분으로 인해 응답이 여러 줄로 나뉘어 들어오는 경우를 대비할 수 있게 됩니다.
lines[i].replace("data:", "").trim()으로 각 줄의 앞에 있는 'data:' prefix를 제거하고 공백을 제거한 후, JSON 형식의 문자열을 얻습니다.
if (jsonStr) {
try {
const aiJson = JSON.parse(jsonStr);
const {
type,
chatId: rchatId,
content,
chatMessageType,
title: rtitle,
} = aiJson.aiResponse;
if (rchatId && rchatId) {
chatId = rchatId;
}
if (type === "DONE") {
done = true;
break;
}
if (!content) {
break;
}
aiResponse.content += content;
setInitialData(1, {
content: aiResponse.content,
isUser: false,
chatMessageId: Date.now(),
});
} catch (error) {
console.log("Failed to parse chunk:", error);
}
}
백엔드로부터 넘어오는 각 청크는 JSON 형태로 구조를 갖춘 데이터입니다. JSON.parse(jsonStr)로 스트림 데이터에서 얻은 JSON 문자열을 파싱하여 aiJson 객체로 변환합니다.
aiJson.aiResponse에서 chatId, content, chatMessageType, title 등의 정보를 추출합니다.
buffer = lines[lines.length - 1];
이 코드가 가장 중요한 부분이라고 할 수 있을 것 같습니다.
buffer는 아직 처리되지 않은 데이터가 남아 있을 경우 다음 루프에서 이를 이어 받아 처리하기 위해 lines 배열의 마지막 요소로 다시 설정됩니다. 이를 통해 청크가 중간에 끊겨서 오는 경우에도 데이터를 안전하게 이어서 처리할 수 있습니다.
이로써 문제를 해결하여 정상적으로 메시지를 보여줄 수 있게 되었지만 궁금증은 여전히 남아있습니다.
첫 번째로 gpt api에서 받아온 응답은 왜 끊기지 않은 것이며, 백엔드가 응답하는 데이터는 왜 끊겨서 보내지는 것인지에 대한 의문입니다.
이에 대한 원인은 이후에 찾게되면 내용을 추가하도록 하겠습니다. 아직은 그 원인은 잘 모르겠지만 예상하기론 백엔드에서 문자열 데이터를 구조를 갖춘 객체 형태로 보내는 과정에서 문제가 생긴 것이 아닌지 생각이 듭니다.
혹은 스프링에서 보내는 스트림을 처리하는 경우는 다른 방식으로 처리해야 하는 것일 수도 있을 것 같습니다. 의심되는 것 중에 하나로 gpt 응답에는 "data: "와 같이 뒤에 공백이 포함되어 오는데 스프링 스트림은 "data:"와 같이 공백이 존재하지 않는 것을 알게되었습니다. 그래서 문제도 이와 관련된 것일 수도 있을 것이란 생각이 듭니다.

새 채팅을 시작하면 페이지 리디렉션 없이 채팅화면에 채팅 메세지가 업데이트 되다가 AI 응답이 모두 도착하게 되면 해당 채팅방으로 리디렉션을 하면서 동시에 sidebar의 히스토리 내역도 업데이트 해주도록 로직을 구현했었습니다.
저는 tanstack query를 사용하고 있고 useQuery로 받아온 데이터가 없으면 Skeleton UI를 보여주도록 하는 방식으로 개발을 진행했었는데 이 과정에서 데이터가 없다고 판단되어 위 영상과 같이 갑자기 중간에 Skeleton UI가 잠깐 생기는 것으로 문제를 파악할 수 있었습니다.
이를 해결하기 위해선 아래과 같이 조건문의 isFetching을 isLoading으로 해결해주었더니 해결할 수 있었습니다.
if (isLoading) {
return (
<aside className="flex flex-col h-full py-4 space-y-2 w-[318px] max-w-[318px]">
<header className="flex flex-row items-center space-x-3">
<Skeleton className="w-14 h-14 rounded-xl" />
<div className="flex flex-col space-y-2">
<Skeleton className="w-3/4 h-5" />
<Skeleton className="w-1/2 h-4" />
</div>
</header>
<Separator />
<Skeleton className="w-full h-15 mb-2" />
<div className="relative h-full px-2 overflow-y-auto space-y-2">
{[...Array(5)].map((_, index) => (
<Skeleton key={index} className="w-full h-9 rounded-lg" />
))}
</div>
<Separator />
<div className="flex flex-col items-center justify-center p-2 space-y-2">
<Skeleton className="w-full h-8" />
<Skeleton className="w-full h-8" />
</div>
</aside>
);
}
문제의 원인과 해결 과정을 말하자면, 먼저 제가 원했던 방식은 데이터를 처음 가져올 때만 로딩중임을 Skeleton 컴포넌트로 나타내다가 이후 refetching하여 데이터를 업데이트 할 때는 로딩 없이 추가된 데이터만 재랜더링 되어야 합니다.
기존에 사용했던 isFetching은 데이터를 처음 가져올 때 뿐만 아니라 이후에 데이터를 가져오는 모든 fetch에서 true가 되기 때문에 불필요하게 계속 Skeleton 컴포넌트가 보이게 되는 것입니다.
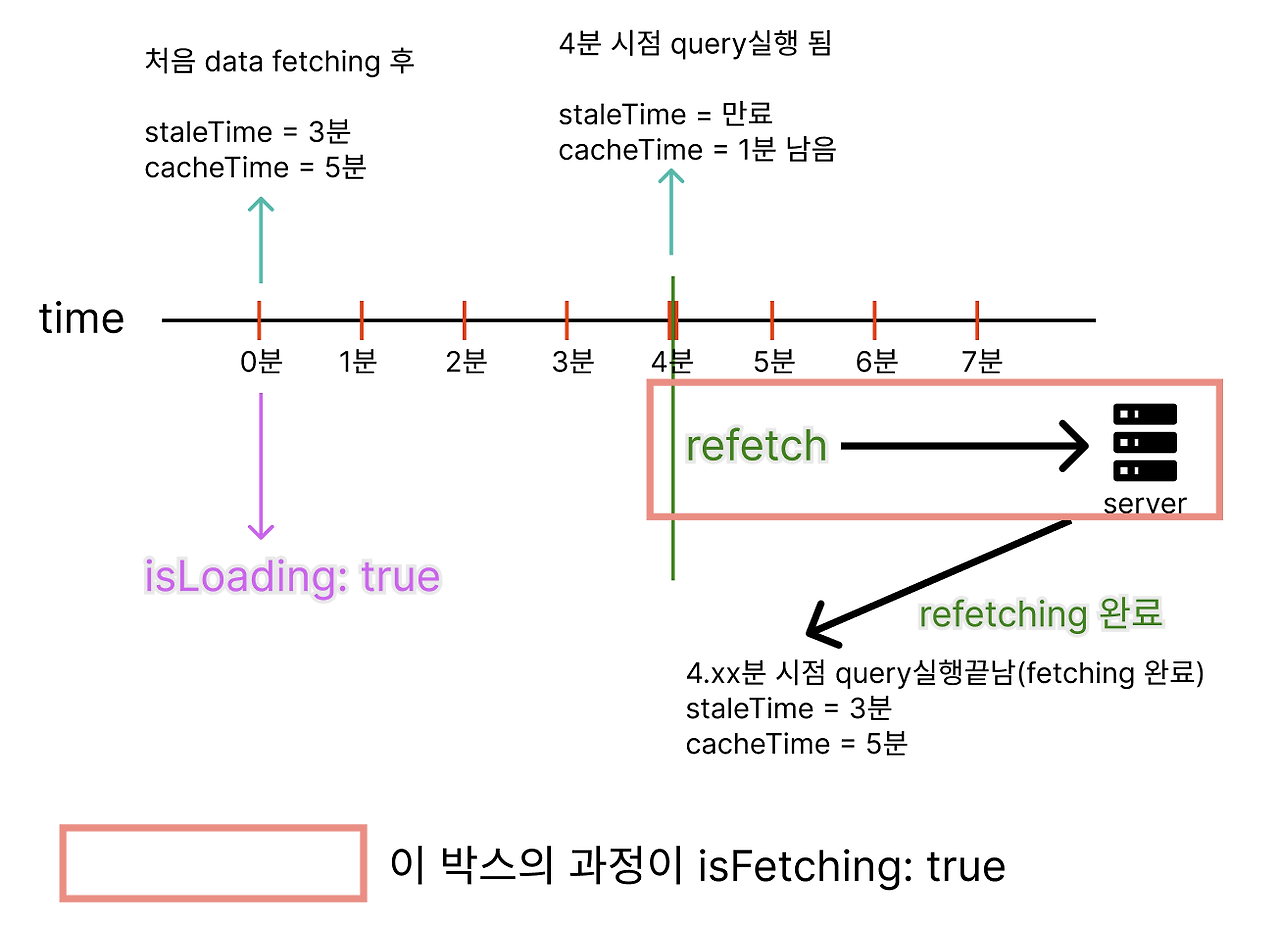
반면, isLoading의 경우 맨 처음 데이터를 가져오는 경우(캐시에 저장된 데이터가 없는 경우)에만 true가 되기 때문에 isLoading이 true일 때 스켈레톤 컴포넌트를 보여주게 하면 됩니다.
새로운 채팅을 보내는 경우, 아직 채팅방 ID가 만들어지기 전이며, AI 응답이 스트림으로 넘어오다가 마지막 청크에 해당 ID 값을 넘겨주게 됩니다.
메인 화면에서 채팅을 보내게 되면 먼저 사용자의 채팅과 AI의 dummy 채팅 메세지를 Zustand 상태로 저장을 시킵니다. 이는 서버 상태가 아닌 클라이언트 상태이기 때문인데요.
AI 응답이 모두 도착하면 그 때 chatId를 가지고 페이지 리디렉션을 하게 되는데 해당 컴포넌트에서는 서버 상태(Server State)을 사용해야 하기 때문에 Tanstack Query의 useQuery 데이터를 가져와 화면에 보여주게 됩니다.
이후에 채팅 화면으로 넘어갔을 때 Zustand의 상태는 초기화시켜야 하고 Tanstack Query의 데이터를 보여주어야 할 것입니다.
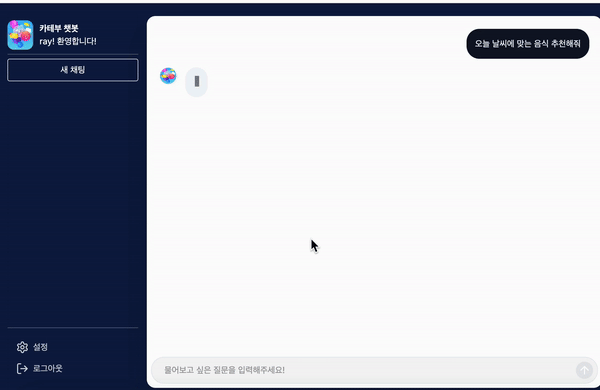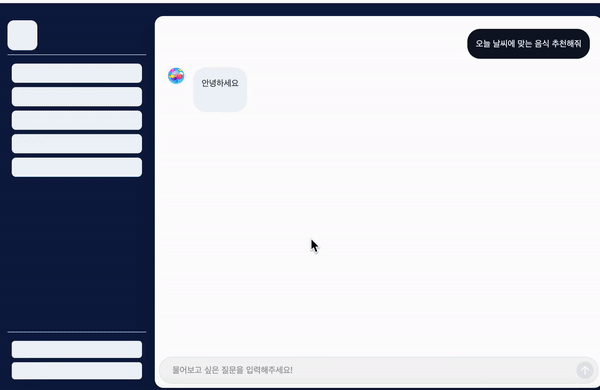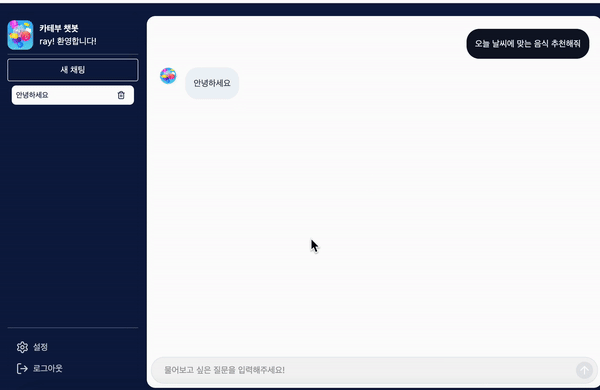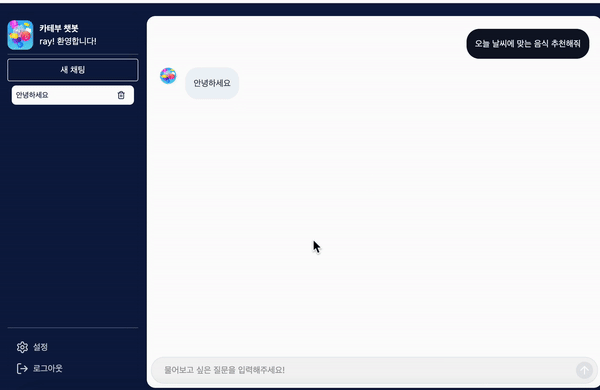
하지만 zustand 상태가 초기화되고 나서 tanstack query의 데이터를 불러오는 데까지 시간이 걸리게 된다면 화면에 보여줄 채팅이 없어 채팅 메세지가 사라졌다가 다시 나타나는 것처럼 보이게 됩니다.
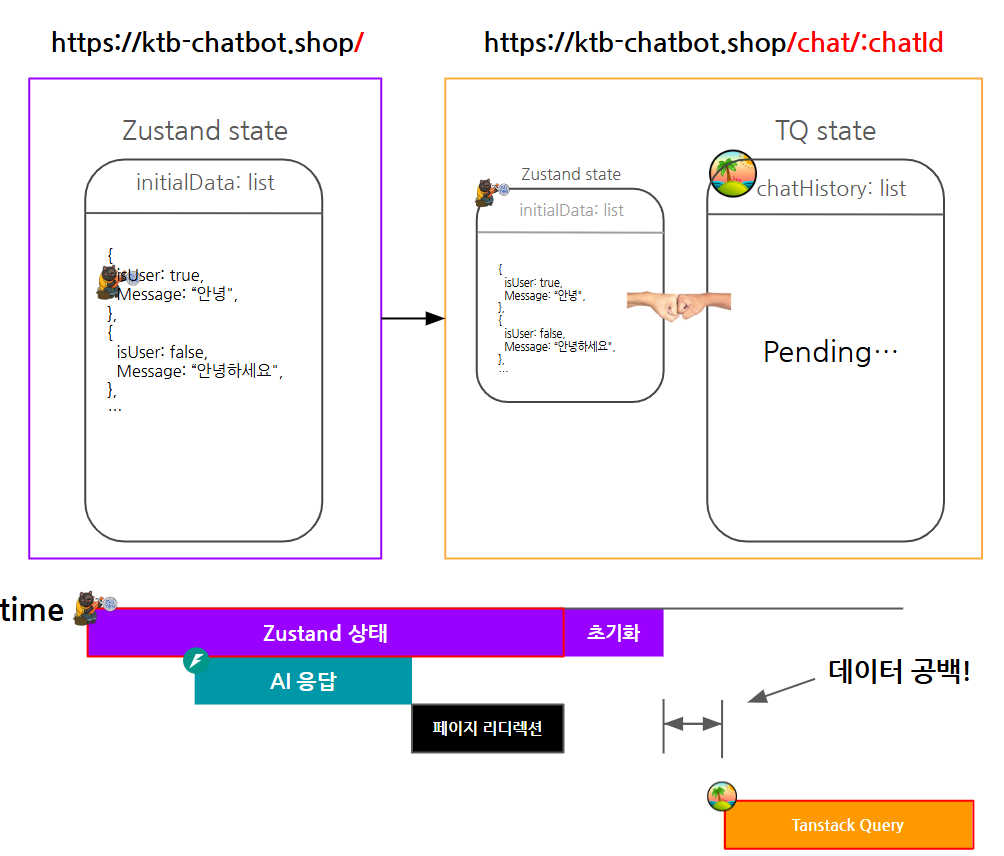
이를 해결한 방법은 페이지 리디렉션 된 컴포넌트(Chat.tsx)에서 useQuery의 데이터를 가져오고 useEffect를 통해 data가 있으면 zustand의 상태를 초기화하도록 동기로 묶어주어 안정적으로 데이터가 바뀔 수 있도록 처리를 해준 것입니다.
// 중략...
const { data, error, isFetching } = useChatHistoryQuery(chatId);
// 중략...
useEffect(() => {
if (data && !isFetching) {
resetInitialData();
}
}, [data, isFetching, resetInitialData]);
// 중략...
const chatData = initialData.length !== 0 || isFetching ? initialData : data;
// 중략...
또한 이 화면은 새 채팅 시에만 들어오는 것이 아니라 채팅 내역 사이드바를 통해서도 들어오기 때문에 zustand 상태의 유무와는 관계가 없을 수도 있는데 새 채팅 시에는 zustand 상태를 일부 시간동안 보여주어야 하므로 useQuery 데이터를 보여주는 것이 아니라 chatData라는 변수를 따로 설정하여 zustand 데이터가 없으면서 / useQuery 데이터가 isFetching이면 zustand를 보여주고 아니라면 useQuery의 데이터를 보여주도록 설정하여 이러한 문제를 해결할 수 있었습니다.
| [프로젝트 | 트러블 슈팅] 강의 수강 완료의 기준 설정 및 트리거 방식 (0) | 2024.11.17 |
|---|---|
| [kakao tech bootcamp] 카카오 테크 부트캠프 챗봇 프로젝트(피카부) - 1 (3) | 2024.09.09 |
| mysql 커넥션 풀 오류 해결 과정 (1) | 2024.08.26 |
| [프로젝트] 데이터를 불러오는 데 너무 오래걸리는 문제 해결 및 성능 개선(feat. 데이터베이스 join) (0) | 2024.06.20 |
| [Devlog] 개발 시작부터 지금까지의 여정 (1) | 2024.06.02 |
소중한 공감 감사합니다