Parallel Processors from Client to Cloud
Introduction
여러개 processor에다가 나눠서 각각에서 실행시키도록 한다.
- 목표: 더 높은 성능을 얻기 위해 여러 컴퓨터를 연결하는 것
- Multiprocessors
- Scalability, availability, power efficiency
- Task-level (process-level) parallelism
- 독립적인 작업에 대한 높은 throughput
- Parallel processing program
- Multicore microprocessors
- Chips with multiple processors (cores)
Hardware and Software
- Hardware
- Serial: e.g., Pentium 4
- Parallel: e.g., quad-core Xeon e5345
- Software
- Sequential: e.g., matrix multiplication
- Concurrent: e.g., operating system
- Sequential/concurrent software는 serial/parallel 하드웨어 위에서 실행될 수 있다.
- Challenge: parallel 하드웨어의 효과적인 사용
Parallel Programming
여러개 multiprocessor를 사용해서 parallel programming
여러 개의 processor에다가 각자 할당된 부분만 실행함.
- Parallel software가 문제이다.
- 성능이 크게 향상되어야 함
- 그렇지 않으면 더 빠른 uniprocessor를 사용하는 게 더 쉬움
- 애로사항
- Partitioning : task를 나누는 것
- Coordination : 나눠준 결과를 다 받는 것
- Communications overhead : 통신
Amdahl's Law

Example:
Scaling
- 문제의 크기를 고정한 상태에서 멀티프로세서에서 속도를 높이는 것은 문제의 크기를 늘려서 속도를 높이는 것보다 어렵다.
- strong scaling – 문제의 크기를 늘리지 않고 멀티프로세서로 속도를 높일 수 있는 경우
- Weak scaling – 프로세서 수의 증가에 비례하여 문제의 크기를 증가시킴으로써 멀티프로세서에서 속도를 높이는 경우
- 로드 밸런싱(load balancing)은 또 다른 중요한 요소이다. 다른 프로세서보다 부하가 두 배나 높은 프로세서 하나만 있으면 속도가 거의 절반으로 줄어든다.
Scaling Example
- Workload: sum of 10 scalars, and 10 × 10 matrix sum
- Single processor:
- 10 processors
- Time = 10 × tadd + 100/10 × tadd = 20 × tadd
- Speedup = 110/20 = 5.5 (55% of potential)
- 100 processors
- Time = 10 × tadd + 100/100 × tadd = 11 × tadd
- Speedup = 110/11 = 10 (10% of potential)
- 프로세서 간에 부하를 균형 있게 조정할 수 있다고 가정
- 걸리는 시간이 110 -> 20 -> 10으로 줄어들었다.
- 하지만 speedup이 10보다 커질 수는 없다.(bottleneck)
Scaling Example (cont)
- matrix size가 100 × 100라면?
- Single processor:
- Time = (10 + 10000) × tadd
- 10 processors
- Time = 10 × tadd + 10000/10 × tadd = 1010 × tadd
- Speedup = 10010/1010 = 9.9 (99% of potential)
- 100 processors
- Time = 10 × tadd + 10000/100 × tadd = 110 × tadd
- Speedup = 10010/110 = 91 (91% of potential)
- load balanced를 가정
- 데이터의 사이즈를 100x100으로 높이니까 91배까지 늘어날 수 있었다.
- problem 사이즈를 가변적으로 변화시키는 방식 -> weak scaling
Strong vs Weak Scaling
- Strong scaling: problem size 고정
- As in example
- 목표: 동일한 problem size를 더 빨리 실행시키는 것
- Weak scaling: 프로세서 수에 비례하는 problem size
- 목표: 같은 시간에 더 큰 문제를 실행하는 것
- 10 processors, 10 × 10 matrix
- Time = (10 + 100/10) × tadd = 20 × tadd
- 100 processors, 32 × 32 matrix
- Time = (10 + 1000/100) × tadd = 20 × tadd
- 이 예제에서 일정한 성능을 보임
- 애플리케이션에 따라 다른 접근 방식
Instruction and Data Streams
- An alternate classification

- MIMD 중에 special한 MIMD
- SPMD: Single Program Multiple Data
- A parallel program on a MIMD computer
- Conditional code for different processors
- 다 똑같은 프로그램이 여러 processor에서 돌고 있다.
- 프로그램은 같지만 실행되는 부분이 다르다. -> parallel programming
SIMD
- 데이터 벡터에 대해 요소별(elementwise) 연산
- E.g., MMX and SSE instructions in x86
- 128비트 wide register의 multiple data 요소
- 모든 프로세서가 동시에 동일한 명령을 실행
- 동기화 간소화
- 축소된 instruction control 하드웨어
- data parallel이 높은 애플리케이션에 가장 적합
Vector Processors
SIMD의 특별한 타입
MIPS의 vector
- Highly pipelined function units
- Stream data from/to vector registers to units
- 메모리에서 레지스터로 수집되는 데이터
- 레지스터에서 메모리로 저장된 결과
- 예제: MIPS로 벡터 확장
- 32 × 64-element registers (64-bit elements)
- Vector instructions
- lv, sv: load/store vector (전부 데이터를 벡터에 load, store)
- addv.d: add vectors of double (vector가 한 번만 계산이 일어나는 것이 아니라 pipeline식으로 쭉 전체가 계산된다.)
- addvs.d: 더블 벡터의 각 요소에 스칼라를 추가
- instruction-fetch bandwidth 대폭 감소
Example

- 2 + 512/8 * 9 = 600번에 가깝게 fetch

Multithreading and Multiprocessing
- Multithreading and Multiprocessing
- 하나의 프로세스에서 여러개의
- 여러 개의 프로세스
- 프로세스에서도 여러 개의 thread
- Multithreading: OS에서 지원하는 CPU(또는 멀티코어 프로세서의 단일 코어)가 여러 스레드의 실행을 동시에 제공하는 기능
- Multiprocessing: 하나 이상의 코어에 여러 개의 완전한 처리 장치(processing unit) 포함
두 기술은 상호 보완적이기 때문에 여러 개의 멀티스레드 CPU와 여러 개의 멀티스레드 코어가 있는 CPU를 사용하는 거의 모든 현대적인 시스템 아키텍처에서 결합된다.
Hardware Multithreading (on a Chip)
- core 안에 여러 개의 thread를 동시에 실행시킬 수 있음
- hareware support가 되어야 함(register file 복사품이 여러 개 있어야 함, PC도 마찬가지)
- 여러 스레드의 실행을 병렬로 수행(스레드 레벨 및 명령어 레벨 병렬을 사용하여 단일 코어의 활용도를 높이는 것)
- 하드웨어는 Replicate 레지스터 파일, PC 등을 지원해야 한다.
- 그리고 스레드 간의 빠른 전환도 필요함.
- 스레드는 컴퓨팅 유닛, CPU 캐시 및 TLB를 포함하는 단일 또는 다중 코어의 리소스를 공유한다.

Threading on a 4-way Super Scalar Processor
연산 unit이 여러개 들어있는 super-scalar-processor(동시에 fetch)

Coarse MT: 할 수 있는 만큼 다 실행하고 다른 thread 대기
Fine MT: clock level에서 실행
SMT: hazard 등의 이유로 비어 있는 공간에 다른 thread를 실행
Multicore or Multiprocessor
- Q1 – How do they share data?
- Q2 – How do they coordinate?
- Q3 – How scalable is the architecture? & How many processors can be supported?
Shared memory
여러 multi processor, 여러 core들이 같은 address의 memory를 동시에 공유
- Q1 – 모든 프로세서가 공유하는 단일 주소 공간(single address space)
- Q2 – 프로세서가 메모리의 shared variables를 통해(load 및 store) 조정/통신
- 한 번에 하나의 프로세서에만 데이터에 액세스할 수 있는 동기화 기본 요소(잠금 장치; lock)를 통해 공유 데이터 사용을 조정해야 한다
- 두 가지 스타일로 제공됨
- Uniform memory access (UMA) multiprocessors
- Nonuniform memory access (NUMA) multiprocessors
Example: Sum Reduction
- 100개의 프로세서 UMA에서 100,000개의 숫자를 합산한다
- 각 프로세서마다 1000개씩
- 각 프로세서의 ID: 0 ≤ Pn ≤ 99
- 프로세서당 파티션 수 1000개
- 각 프로세스에 대한 초기 합계
- 자기에게 할당된 계산을 각자 계산하고 합침

- 이제 이 부분합을 더한다
- Reduction: divide and conquer
- 프로세서의 절반이 pair를 추가하고, 그 다음에 4분의 1을 추가한다…
- reduction steps 사이에 동기화가 필요함
계층적으로 계산 결과를 취합하면서 올라감
Message Passing Multiprocessors(MPP)
shared memory에서는 공통적인 메모리 하나를 여러 프로세서가 공유(확인)하는 것이었다면
MPP는 network을 두고 이를 통해서 나눠져 있음 (+ send/receive protocol)
- 각 프로세서에는 고유한 개인 주소 공간이 있다
- Q1 – 프로세서가 명시적으로 정보를 주고받음으로써 데이터를 공유한다(message passing)
- Q2 – 조정 기능이 기본 메시지 전달 기본 요소(message send and message receive)에 내장되어 있다
- 주고 받는 protocol 때문에 느려질 수 있음
- 메시지 송수신(message sending and receving) 속도가 추가(addition)보다 훨씬 느리다
- multi core 방식 같은 경우 SMT 모델을 쓰는 것이 좋고 일반적인 경우는 MPP를 사용한다.
- 그러나 메시지가 여러 프로세서를 passing하고 설계하기가 훨씬 쉽다
- cache coherency에 대해 걱정하지 않아도 된다.
- Communication은 명시적이다. (vs. implicit communication in SMPs)
- 모든 통신을 미리 식별해야 하기 때문에 message passing multiprocessor로 sequential program을 전송하는 것이 더 어렵다.
- cache-coherent shared memory를 사용하면 hardware가 통신해야 할 데이터를 파악할 수 있다.
Example with 10 processors

최종적으로 master processor(0번 processor)가 취함
MPT and OpenMP in multi-core
- OpenMP:
- 쓰레드에 대한 인터페이스가 있음
- 코드는 병렬 영역, 축소, 동기화 등을 나타내기 위해 특별한 #pragma 문으로 주석을 단다.
- #pragma 는 여기서 부터 parallel 하게 하겟다는 뜻
- 켜려면 특수 컴파일러 플래그가 필요하다. (e.g. –fopenmp)
- 멀티 코어 CPU에서 사용 가능
- 사용하는 코어 수를 늘리고 데이터 크기를 작고 크게 사용하여 확장성 측면에서 성능이 더 뛰어났다.
- MPI
- 통신을 위한 높은 오버헤드
- 공유 메모리를 사용하지 않는 대규모 병렬 컴퓨팅의 표준이기 때문에 통신에 더 의존한다
- 분산 메모리 시스템의 대규모 과학 문제 해결을 위해 설계되었다
MPI
- Mpiexec (or mpirun)
- Can specify hostfiles: mpiexec –hostfile myhostfile ./a.out
- 공정(processes) 수를 지정할 수 있다
- mapping MPI processes to Nodes (processors)
- -np 옵션에서 프로세스 수 읽기
- 프로세스가 실행될 위치를 결정한다:
- 호스트 파일 또는 -host 옵션으로 지정된 사용 가능한 호스트(또는 노드)
- Scheduling the policy (round-robin or by-slot)
- 각 호스트에서 사용할 수 있는 기본 및 최대 슬롯 수
CPU info (example)
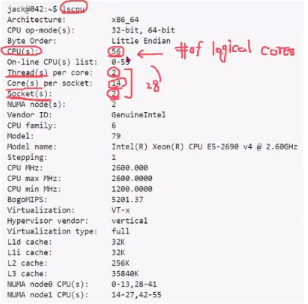
- socket -> cpu가 2개
- 실제로 cpu의 갯수 -> 56개 -> logical core의 개수를 말함
