Review)
I/O (Input/Output)
- CPU입장에서 Memory 빼고는 다 I/O
- hard disk는 io와 controller에 연결 되어 있는 storage

- 입출력 모듈(IO)은 왜 필요할까요?
- 다양한 장치가 존재하는데 각자의 속도는 다 다릅니다. 출력 데이터 포맷도 다 다르고 그래서 일반화 할 수는 없을까? 해서 만들어진 것이 'I/O module' 입니다. (CPU와 RAM보다 속도도 느리기 때문에 버퍼링 할 수 있는 게 필요 했습니다.)
https://com24everyday.tistory.com/173
- 빠른 것들은 그냥 붙이고 느린 것들은 bridge를 달아서 거기에 매다는 방식도 존재함

- data를 저장하는 register와 status/control register가 존재한다.
- 그런데 이런 것들 하나하나를 control 하는 것은 쉬운 일이 아니다.(chip을 설계한 사람이 아닌 이상)
- 그래서 드라이버를 설치하는 것
- 하나하나 register와 logic마다 IO address가 존재한다.(I/O port)
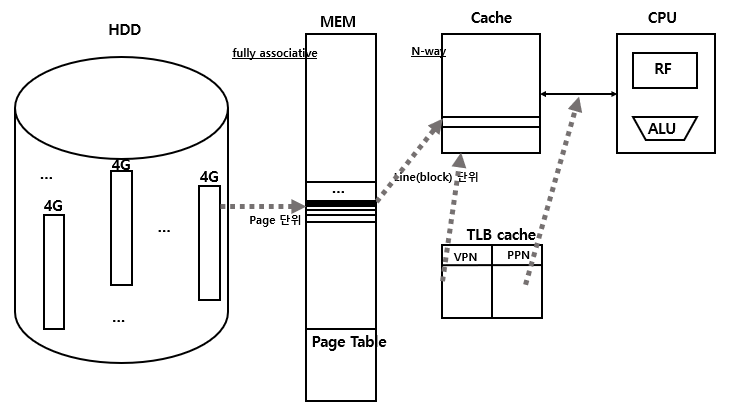
- memory와는 별개로 따로 I/O가 존재하는 경우 -> Isolated I/O
- memory의 한 부분을 I/O로 사용하는 것 -> memory-mapped I/O
- I/O를 할 때에도 그냥 기존의 lw, sw를 사용
I/O와 CPU가 통신하는 방법?
Input Output Techniques
- Programmed I/O : CPU must wait (polling)
- Interrupted-driven I/O
- Direct memory acess(DMA) : CPU한테 데이터를 주고 받겠다는 허락을 한 번 받기만 하면 그 이후부터는 CPU 에 개입 없이 다른 게 직접 수행

시스템 버스에는 CPU와 Memory가 붙고 아래쪽에 실제 디바이스가 위치한다.

Chapter 6. Storage and Other I/O Topics
Introduction
CPU입장에서 Memory가 아닌 것은 전부 I/O이다.
- I/O 장치는 다음에 의해 특징지을 수 있다.
- Behaviour: input, output, storage (어떤 행동?)
- Partner: human or machine (누가 컨트롤?)
- Data rate: bytes/sec, transfers/sec (얼마나 빠르게 전송?)
- I/O bus connections

- 프로세서와 메모리는 프로세서가 원하면 메모리에서 데이터를 가져오거나 데이터를 쓰는 것이 가능
- IO 자체가 주체가 되어 데이터를 주고 받을 수도 있는데
- I/O들이 CPU에게 Interrupt를 걸기위한 interrupt 핀이 존재함 (그래야 I/O가 다 마쳤을 때 알리기 위함)
- IO device들은 direct로 연결된 것이 아니라 IO controller를 중간에 거친다.
- 그래서 CPU는 IO device가 어떻게 생겼는지 알 필요가 없고
- IO controller에 내장된 (두 종류의 register[control, cammand], data, logic) 것들에 접근하여 데이터를 주고 받는 것이다.
I/O System Characteristics
- CPU 부분에서는 performance가 중요했음
- memory 부분에서는 performance (throughput) 과 miss rate, capacitancy과 같은 것들이 최대 관심사였다.
- IO는 물론 performance(throughput)도 중요하지만 IO 종류가 다양하다 보니까 Latency가 중요한 경우도 많다.
- Dependability (reliability; 신뢰성) is important
- disk가 날라가면 엄청 큰일나기 때문에 speed 도 중요하지만 dependability가 매우 중요한 것
- Performance 측정 방식
- Latency (response time; 반응속도)
- IO에서는 키보드와 같은 것은 치자마자 입력이 되는 것이 중요하기 때문에 Latency가 중요함
- 키보드가 모았다가 보내는 것은 의미가 x
- Throughput (bandwidth; 밴드폭)
- gigabit internet 같은 것은 throughput이 중요함
- IO종류에 따라 latency가 중요할 때도 Throughput이 중요할 때도 있다
- Desktops & embedded systems (얘네는 아래가 중요함)
- response time & diversity of devices
- Servers (서버는 아래가 중요함)
- throughput & expandability of devices
Dependability
- system이 얼마나 안전하냐 (reliability)

system이 실행되다가 fail이 발생하면 interrupt가 발생하고 restoration(복구)되면 다시 실행하는 방식
- Fault: component의 failure
- system failure를 초래할 수도 있고 아닐 수도 있다.
- system에서 fail과 restore은 지정된 시간에 따라 발생하는 것이 아니기 때문에 평균을 구한다.
실제로 사용할 수 있는 구간은 fail이 발생하고 restore가 되면 그 restore된 시점부터 다음 fail이 발생하기 전까지이다.
Dependability Measures
- Reliability – mean time to failure (MTTF)에 의해 측정됨.
- Service interruption은 mean time to repair (MTTR)에 의해 측정된다.
- MTTF는 available한 상태
- MTTR는 service interrupt 구간(사용하지 못하는)
- Availability – service accomplishment의 측정
- Availability = MTTF/(MTTF + MTTR)
- availablity를 높이기 위해선 분자를 높이던지 분모를 낮추던지
- 고장이 덜나게 하려면(MTTF를 높이려면) -> Fault avoidance
- MTTF를 증가시키기 위해서 component의 퀄리티를 향상시키거나 faulty component의 존재 속에서 operating을 계속하는 시스템을 디자인해야 한다.
- Fault avoidance: construction에 의한 fault 발생을 방지한다.
- Fault tolerance: faulty component를 고치거나 bypass하기 위해 redundancy를 사용한다.(hardware)
- Fault detection vs. fault correction
- Permanent faults vs. transient faults
Disk Storage
special IO
- Nonvolatile, rotating magnetic storage
- 비휘발성, 자기를 띤, 겹친 디스크가 회전,
- track의 sector마다에 데이터가 쓰여짐.

Disk Sectors and Access
- 각 sector는 다음을 기록한다.
- Sector ID
- Data (512 bytes, 4096 bytes proposed)
- Error correcting code (ECC): 오류를 숨기기 위해 사용됨
- Synchronization fields and gaps(동기화 필드 및 간격)
- sector에 대한 접근은 다음을 수반한다.
- Queuing delay if other accesses are pending(다른 액세스가 보류 중인 경우 대기열 지연)
- Seek: heads를 움직임
- Rotational latency
- Data transfer
- Controller overhead
- Blocks vs. sectors
- Sector: 포맷된 디스크에서 정보를 저장하는 물리적인 지점
- Block: 운영 체제가 접근할 수 있는 섹터 그룹
(1, 2, 4, 8 or even 16 sectors)
- OS가 관리할 때는 block이라는 용어를 사용함.
Disk Access Example
- 다음과 같은 조건 하에,
- 512B sector, 15,000rpm, 4ms average seek time, 100MB/s transfer rate, 0.2ms controller overhead, idle disk
- Average read time은?
- 4ms seek time512 / 100MB/s = 0.005ms transfer time
- 0.2ms controller delay
= 6.2ms
- ½ / (15,000/60) = 2ms rotational latency
- 만약 실제 average seek time이 1ms라면,
- Average read time = 3.2ms
Disk Performance Issues
- 제조업체는 average seek time을 인용한다
- 모든 가능한 seek에 기반하여
- Locality와 OS scheduling은 더 짧은 실제의 average seek times을 가져온다.
- 똑똑한 disk controller는 disk에 physcial sectors를 할당한다.
- host에게 logical한 sector interface를 제공한다.
- SCSI, ATA, SATA
- Disk drives는 caches를 포함한다.
- access를 예상한 sectors를 prefetch한다.
- seek과 rotational delay를 피한다.(혹은 감소)
Flash Storage(SSD)
- 비휘발성 반도체 저장소
- disk보다 100× – 1000× 빠르다.
- 더 작고, 더 낮은 파워를 사용하며, 더 강인하다.
- 하지만 더 큰 $/GB를 갖는다.(disk와 DRAM 사이에)
- Flash memory bits는 마모되지만(디스크 및 DRAM과 달리) 마모 레벨링으로 인해 플래시의 쓰기 제한이 초과되지 않을 수 있음
- wear out - 10만번 정도 쓰면 자주쓰는 부분은 다 떨어짐, 마모 된다.
- FTL이라는 펌웨어가 들어있음 -> 골고루 쓸 수 있도록 관리해 주는
RAID: Disk arrays
dependability, throughput을 위해 사용하는 방법
- Redundant Array of Inexpensive Disks (RAID)
- 말 그대로 disk를 여러개 쓰는 (disk array)
- reliability 측면에서 하나 있는 거 보다는 더 떨어짐
- disk가 많아질 수록 고장날 확률이 올라가기 때문에
- 그치만 동시에 여러 개의 데이터를 준비시킬 수 있음
- 작고 값싼 disk 의 배열
- disk drives 를 많이 사용하여 잠재적인 throughput 향상
- 데이터가 여러 disk에 분산됨
- 한 번 access할 때, 여러 디스크에 여러 번 액세스합니다
- Reliability는 single disk보다 더 낮다.
- 하지만 availability는 redundant disk를 추가함으로써 향상시킬 수 있다. (RAID)
- 손실된 정보는 redundant 정보로부터 복구될 수 있다.
- MTTR: mean time to repair is in the order of hours(평균 수리 시간은 수시간)
- MTTF: mean time to failure of disks is tens of years(평균 Disk 장애 발생 시간은 수십 년)
RAID 0 (no redundancy)
- 원래 하나의 disk에 다 있던 block을 두 개의 disk에 interleaved 시킴
- 하나의 큰 디스크가 아닌 여러 개의 작은 디스크
- 여러 디스크에 걸쳐 분산( striping )하면 여러 block에 병렬로 액세스할 수 있어 성능이 향상된다
- 4개의 디스크 시스템은 1개의 디스크 시스템보다 4배의 throughput을 제공한다
- 하나의 큰 디스크와 동일한 비용 – 4개의 작은 디스크가 하나의 큰 디스크와 동일한 비용이 든다고 가정
- redundancy가 없는데, 디스크 하나에 장애가 발생하면 어떡함?
- system의 disk 수가 증가함에 따라 하나 이상의 disk가 실패할 가능성이 높아진다
- reliability가 떨어짐 - 하나 있을 때보다 두 개 있을 때 고장날 확률이 더 높기 때문에

RAID 1 and 2
RAID 0 에서 reliability가 낮던 단점을 보완
- RAID 1: Mirroring
- N + N disks, replicate data(데이터 복제)
- data disk와 mirror disk 둘다에 데이터를 write한다.
- disk 고장 시 mirror로부터 읽는다.
- 용량이 두 배가 되기 때문에 비효율

- RAID 2: Error correcting code (ECC)
- N + E disks (e.g., 10 + 4)
- N개의 disk에 걸쳐 bit level로 데이터를 분리
- E-bit의 ECC 생성
- Error correction code
- 어느 부분에서 error가 났는지 판단 후 복구
- 너무 복잡하고 실제로 잘 사용되지도 않음

Striping
- Striping in Storage
- 논리적으로 순차적인 데이터(예: 파일)를 분할하여 연속적인 세그먼트를 서로 다른 물리적 저장 장치에 저장하는 기법입니다.
- consecutive segment가 서로 다른 물리적 storage에 저장되어있다.
- 동시에 액세스할 수 있는 여러 장치에 세그먼트를 분산시킴으로써 총 데이터 throughput 증가

RAID 3: Byte-level striping with Parity
- N + 1 disks (+1은 parity check를 위한 disk)
- 바이트 수준의 N개 디스크에 걸쳐 데이터 스트라이프(하위 분할)
- Redundant disk가 parity를 저장
- Read access: 모든 disks 읽기
- Write access: 새 parity 생성 및 모든 disk 업데이트
- 고장 시: parity를 사용하여 missing 데이터를 재구성
- 효율적 사용을 위해 hardware적 지원이 요구된다.
- 6개가 하나의 블락
- 한 블락을 access 하려면 저 6개를 다 access해야함
- 널리 사용되지는 않음

RAID 4: Block-level striping
- N + 1 disks
- block level에서 N개의 disk에 걸쳐 striped된 데이터
- Redundant disk는 block 그룹에 대한 parity를 저장
- Read access: 필요한 block을 유지하고 있는 disk만 읽기
- Write access: 수정된 block과 parity disk가 포함된 디스크만 읽기
- 새 parity 계산, 데이터 disk 및 parity disk 업데이터
- 고장 시: Use parity to reconstruct missing data
- 널리 사용되지는 않음

각 parity block의 block 그룹을 나타내는 각 색상을 가진 전용 parity disk로 RAID4 설정(a stripe)
RAID 3 vs RAID 4

RAID 4에서는 block 단위로 하기 때문에 disk하나하나 access 하지 않아도 됨(reliablity는 줄어들긴 해도)
RAID 5: Distributed Parity
- N + 1 disks
- RAID 4와 유사하지만, parity blocks이 여러 disk에 분포되어있다.
- parity disk가 bottleneck이 되는 것을 피함
- 널리 사용되는 방식

parity block을 분산 시켜서 배치한 방식
- 한 disk에만 traffic이 몰릴 것을 대비
RAID 6: P + Q Redundancy
redundancy를 두 개 쓰자는 아이디어
- N + 2 disks
- RAID 5와 유사하지만, parity가 두 개나 된다.
- 이중화를 통해 fault tolerance 향상
- Multiple RAID
- 더 진보된 시스템은 성능이 향상된 유사한 fault tolerance를 제공한다.


복잡하고 cost가 올라가지만 두 개가 고장나도 복구가 가능하다.
RAID Summary
- RAID는 performance와 availability를 향상시킬 수 있다.
- High availability을 위해서는 hot swapping (시스템을 중지, 종료 또는 재부팅하지 않고 컴퓨터 시스템에 구성 요소를 추가하는 교체)이 필요하다
- interleaved된 구조로 인해서 performance 증가
- 고장이 나도 parity라던가 redundancy로 복구가 가능함 -> dependability(availability)
- 독립적인 disk 고장을 가정
- See “Hard Disk Performance, Quality and Reliability”
Review: components of a computer

- II/O system에서 중요한 metrics (중요한 기준)
- Performance
- Expandability
- Dependability
- Cost, size, weight
- Security
- IO 종류에 따라 중요하게 여겨지는 metric(기준)이 달라질 수 있다.
A Typical I/O system

IO bus를 기준으로 윗 부분이 master, 아랫 부분이 slave로 본다.
IO device마다 속도가 다름
사람이 CPU에게 요청할 수 있는데 이는 개별적으로 CPU에게 요청하는 것이 아니기 때문에 Interrupt라고 한다.
Input and output Devices
- I/O devices are incredibly diverse with respect to
- I/O 장치는 다음과 관련하여 엄청나게 다양합니다
- Behavior – input, output or storage(입력, 출력 또는 저장) - 무슨 용도로 사용하는지
- Partner – human or machine - 누가 사용하는지
- Data rate – I/O 장치와 메인 메모리 또는 프로세서 간에 데이터를 전송할 수 있는 최대 속도 - 어느 정도의 성능인지

I/O Performance Measures
- I/O bandwidth (throughput) – 단위 시간당 interconnect(예: 버스)를 통해 프로세서/메모리(I/O 장치)로 입력(출력) 및 통신할 수 있는 정보의 양
- 시스템을 통해 일정 시간 동안 얼마나 많은 데이터를 이동할 수 있는지?
- 단위 시간당 몇 개의 I/O 작업을 수행할 수 있습니까?
- I/O 응답 시간(지연 시간-latency) – 입력 또는 출력 작업을 수행하기 위한 총 경과 시간
I/O system interconnection issues
- bus 는 다양한 latencies와 데이터 전송 속도를 가진 다양한 장치를 지원해야 하는 공유 통신 링크(여러 서브시스템을 연결하는 데 사용되는 단일 wire 세트)이다
- 키보드와 같은 IO device가 CPU에게 데이터를 보내기 위해서 IO controller의 serial interface를 통한다.
- 장점
- Versatile(변하기 쉬움) – 새로운 장치를 쉽게 추가할 수 있고 같은 bus 표준을 사용하는 컴퓨터 시스템 간에 이동이 가능하다.
- Low cost – 단일 wires 세트가 여러 방식으로 공유된다
- 단점
- communication bottleneck이 생긴다.
- bus bandwidth가 최대 I/O throughput을 제한한다.
- 최대 bus 속도는 대체로 다음에 의해 제한된다.
이는 진짜 간단한 형태의 bus로 이 방식으로 구성하면 제한이 너무 크다.
Types of Buses
- Processor-memory bus (“Front Side Bus”, proprietary; 전용)
- 짧고 빠른 속도
- 메모리 시스템과 일치하여 memory-processor bandwidth 극대화
- 캐시 블록 전송에 최적화
- I/O bus (industry standard, e.g., SCSI, USB, Firewire)
- 일반적으로 길고 느리다
- 광범위한 I/O 장치를 수용해야 함
- 프로세서 메모리 버스 또는 backplane bus를 사용하여 메모리에 연결한다
- Backplane bus (industry standard, e.g., ATA, PCIexpress)
- 프로세서, 메모리 및 I/O 장치를 단일 버스(컴퓨터의 backplane에 내장)에 공존시킬 수 있다.
- Used as an intermediary bus connecting I/O busses to the processor-memory bus
- I/O 버스와 processor-memory bus를 연결하는 intermediary bus로 사용됩니다
I/O Transactions(read/write)
- I/O transaction은 요청을 포함하고 데이터를 전달할 수 있는 응답을 포함할 수 있는 interconnect를 통한 일련의 작업 순서이다.
- 트랜잭션은 단일 요청에 의해 시작되며 많은 개별 버스 작업을 수행할 수 있다. I/O 트랜잭션은 일반적으로 두 부분을 포함한다
- Sending the address
- Receiving or sending the data
- CPU에서 mem을 읽을 때 address가 mem으로 가면 어느 정도 후에 mem이 data를 실어주고 양방향으로 왔다갔다 하기도 한다.
- 이 과정에서 메모리(slave)는 가만히 있고 CPU(master)가 능동적으로 작동한다.
- 메모리는 수동적
- IO도 마찬가지로 address를 보내주고 데이터를 받아오는데 가만히 있는 것이 아니라 능동적으로 주고 받는다.
Synchronous and Asynchronous Buses
- Synchronous bus (e.g., fast processor-memory buses)
- control lines에 clock를 포함하고 clock에 상대적인 통신을 위한 고정 프로토콜이 있음
- 장점: 매우 적은 logic을 사용하며 매우 빠르게 실행할 수 있다
- 단점:
- 버스에서 통신하는 모든 장치는 동일한 클럭 속도를 사용해야 한다
- clock skew를 피하기 위해서, 속도가 빠르면 길 수 없다
- Asynchronous bus (e.g., relatively slow I/O buses)
- It is not clocked, so requires a handshaking protocol and additional control lines
- clock이 아니라서 handshaking protocol과 추가 control lines이 필요하다
- handshaking: 준비 됐어? -> 준비 됐다 -> 데이터 왔다 갔다
- 장점:
- 광범위한 장치 및 장치 속도를 수용할 수 있다.
- clock skew 이나 동기화 문제 걱정 없이 길이가 길어질 수 있습니다
- 단점: (더) 느리다
Asynchronous Bus Handshaking Protocol
- memory에서 I/O 장치로 데이터 출력(읽기)


Bus Types
- Processor-Memory buses
- Short, high speed
- 디자인이 memory 구성과 일치한다.
- I/O buses
- 더 길고, 다중 연결이 가능하다.
- 조금 느려도 low power?
- interoperability(상호운용성) 표준에 의해 지정됨
- bridge를 통해 processor-memory bus에 연결
Bus Signals and Synchronization
- Data lines
- address와 data를 전달
- Multiplexed 혹은 separate
- Control lines
- Synchronous
- Asynchronous
- Uses request/acknowledge control lines for handshaking
- handshaking에 대한 request(요청)/acknowlege(응답) control lines 사용
I/O Bus Examples
 ..
..
Typical x86 PC I/O System

north bridge를 통해서 high speed IO가 연결 되고
south bridge를 통해서 low speed IO가 연결된다.
AMBA(Advanced Microcontroller Bus Architecture)
ARM

지금은 AXI로 변하였음 - network
- master가 여러개가 붙어 있음(core와 같은 것들)
I/O Management
- OS(대부분 OS 가 handling)에 의해 I/O가 매개됩니다
- 여러 프로그램이 I/O 리소스를 공유함
- protection 및 scheduling 필요
- I/O로 인해 asynchronous interrupts가 발생
- IO controller가 요청
- exceptions과 같은 메커니즘
- I/O programming is fiddly(어렵다, 이상하다)
- I/O의 낮은 수준의 제어는 복잡하고 상세하다
- OS는 프로그램에 추상화(abstractions)를 제공한다.
- IO controller가 수십개 수백개가 되는 경우가 있는데 이것들에 대해 잘 알아야 프로그래밍을 잘 짤 수 있다.
- 그래서 IO 설계 logic은 설계자 외에 모른다.
- 그래서 보통 드라이버 소스를 만들어서 제공해 주고 사용자가 실행하여 사용한다.
I/O Commands
- I/O 장치는 I/O 컨트롤러 하드웨어에 의해 관리된다
- 장치로/로부터 데이터 전송
- software와 작업 동기화
- I/O registers (I/O port addresses)
- Command registers (control)
- Status registers
- 장치가 수행 중인 작업 및 오류 발생을 나타낸다
- Data registers
- Write: 장치로 데이터 전송
- Read: 장치에서 데이터 전송
I/O Register Mapping
몇 번지부터 몇 번지 까지 I/O를 쓸 것인가
- Memory mapped I/O
- 레지스터는 메모리와 동일한 공간에서 처리된다:
- 동일한 load/store instruction 사용 (lw/sw 사용)
- Address decoder는 이들을 구별함
- OS는 주소 변환 메커니즘을 사용하여 커널에만 액세스할 수 있도록 한다
- RISC
- Isolated I/O (or separated I/O or I/O mapped)
- Memory와 I/O address 공간이 분리되어 있음
- I/O registers에 접근하기 위한 Special instructions (e.g. in, out)
- 분리된 control signal (e.g. MEM/IO)
- kernel mode만 실행 가능
- Example: x86
Memory-mapped I/O hardware
- Address Decoder:
- 주소를 확인하여 프로세서와 통신하는 장치/메모리를 확인한다
- I/O Registers:
- ReadData Multiplexer:
- 메모리와 I/O 장치 중에서 프로세서로 전송되는 데이터 소스로 선택합니다

Memory-mapped I/O code
- I/O 장치 1에 주소 0xFFFF4가 할당되었다고 가정
- 값 42를 I/O 장치 1에 기록
- I/O Device 1에서 값을 읽고 $t3로 표시

memory의 address에 따라 진짜 memory에 접근 하는 것일 수도 있고 IO에 접근하는 것일 수도 있다.
- 이와 다르게 Isolated의 경우
out or in 과 같은 명령어가 별도로 존재함.
Communication of I/O devices and Processor
CPU와 IO간 어떤 방식으로 통신하는가?
IO는 memory와 다르게 IO device마다 속도가 다르기 때문에 memory처럼 일관적인 속도로 주고 받을 수 없다.
- Polling
- 주기적으로 IO status register를 check한다.(IO가 준비가 됐나... 하고 계속 체크하는 것)
- device가 준비되면 작동 하고
- error이면 행동을 취한다.
- 소규모 또는 저성능 실시간 임베디드 시스템에서 공통적으로 사용 가능
- CPU가 하루종일 그것에만 낭비하면 손해임 그래서 나온게 Interrupt-driven I/O
- 물론 목적이 하나인 임베디드라면 상관이 없겠지만... 범용 컴퓨터에선 중요함
- Interrupt-driven I/O (중요)
- I/O 장치 문제 및 서비스 요청을 위한 interrupt
- 더 효율적임 - CPU가 할일이 많고 Interrupt 걸 수 있는 I/O가 많을 때 효율적이다.
- 하지만 냉장고와 같은 장치는 할 일이 딱히 없기 때문에 굳이 이런 기능이 없어도 되는 것이다.
Polling example

준비(loop)하다가 input, LSB가 준비 됐는지를 알려주기 때문에 그것을 계속 확인해서 1이면 즉, 준비 됐으면 s2에 read한다.

Example (PIC 32 microcontroller)

Bus Matrix는 interconnection network로 되어 있으니까 여러개가 한 꺼번에도 가능
PIC32 MX675F521H block diagram
MIPS controller

Example (keyborad control)
- Example (note that this is not MIPS)

Example (PIC32 GPIO; Gernal Purpose IO)
여러 기능의 IO가 있어서 여러 개를 control 가능하다. -> 일부는 output으로 일부는 input으로
- (ex) 4개의 스위치를 읽고 해당하는 하단 4개의 LED를 켠다.
- TRIS(control) register는 input(1) and output(0)을 결정한다.
- PORT(data reg) register: input 혹은 output으로 driven된 값
- 핀 RD[11:8]를 조사하고 RD[3:0]에 다시 write.
// C Code
#include <p3xxxx.h>
int main(void) {
int switches;
//1111 111100000000
TRISD = 0xFF00; // RD[7:0] outputs ; control register 0이면 output,1이면 input
// RD[11:8] inputs
while (1) {
// read & mask switches, RD[11:8]
switches = (PORTD >> 8) & 0xF; // read(1111)한 결과를 읽기 위해
PORTD = switches; // display on LEDs ; write
}
}