새소식
반응형
Performance
Example) ideal case
그 동안은 instruction을 하나만 봤기 때문에 performance를 1/exec.Time 으로 생각했는데 실제 프로그램은 수많은 instruction들로 이루어져 있기 때문에 latency 하나만 가지고는 performance를 생각할 수 없다.
따라서 instruction이 여러개가 있을 때는 throughput을 봐야한다.
5개로 나눴을 때 throughput이 1에서 5가 된 것을 보면 많이 쪼갤수록 throughput이 좋아질 텐데 이를 과연 어디까지 쪼갤 수 있을까?는 의문이다.
Example) non-ideal case(practical case)
0.3 + 0.4 + 0.3 + 0.3 + 0.2
위와 같이 not even(균등하지 X) 하게 나누어 졌다고 생각해 보자. 그러면 가장 긴 시간이 걸리는 0.4에 해당하는 부분을 기준으로 clock cycle time이 결정될 것이다.(즉, 모든 clock이 0.4s임)
그렇기 때문에 register마다의 overhead(tpcq, tsetup)를 고려해야 할 것이다.
많이 나누면 나눌수록 좋은데 자기 마음대로 나눌 수 있는가? -> NO
back path가 존재하는 경우 돌아갔을 때 돌아간 path 그 이전의 clock이 끝날 때까지 기다려야 하므로 제한이 걸린다.
어떤 한 순간에 봤을 때 여러 개의 instruction을 실행하고 있음.
Q) pipeline의 갯수보다 실행할 명령어가 더 적으면 비효율적인가?
A) Yes, but practical case에서 instruction의 수는 수백만, 수천만개임.
Q) multi cycle과의 차이?
A) multi cylce은 5개로 나눠서 이 전체를 clock으로 사용하여 한 순간에 한 instruction만을 실행했는데, pipeline은 각 순간에 여러개의 다른 명령어가 실행될 수 있고 반드시 한 instruction이 5cycle 동안 진행되어야 한다.


5cycles 이후부터는 끝날 때까지 한 clock 당 한 instruction이 끝나기 때문에 hazard가 없는 경우의 CPI는 1이다.
위 그림을 보면 알 수 있듯이 어떤 한 순간에 모든 방에서 instruction이 돌아가는 경우가 존재하기 때문에 data memory와 instruction memory가 동시에 사용되는 경우가 있어 multi cycle 처럼 memory(Data memory와 Instruction Memory)의 share가 더 이상 불가능해진다.
따라서 single cycle처럼 각각의 모든 hardware resource가 다 있어야 함.

W방에 들어가면서 rising edge에서 write back 하여 register file에 data를 write 하려고 할 때 register file의 clk이 rising edge에서 동작하면 충돌이 일어나기 때문에 rising edge에서 writeback 하면 negative edge에서 register file에 data가 실제로 저장되도록 해야 한다.

위 명령이 진행되는 것을 보면 어느 특정 clock에서 하나의 Register에 대해서 Write와 Read가 동시에 일어나기도 한다.
그러나 하나의 hardware에서 두 가지 동작을 동시에 할 수는 없기 때문에 write을 한 후에 read를 하기 위해서 write하는 동작이 synchronous하게 동작하므로 이를 rising edge에서 동작하는 것이 아니라 falling edge에서 동작하게끔 하여 해결할 수 있다.

sw 명령의 경우 메모리에서 write과 read가 동시에 일어나는데 실제 memory write 명령이 Memory 단계에서 일어나는 것이 아니라 Writeback 단계에서 일어나는데(즉, next cycle) 해당 clock의 rising edge에서 write을 동작하게 하면 lw명령에서 memory를 read할 때는 async로 read하기 때문에 문제가 없다.

WriteReg must arrive at same time as Result
빨간색으로 표시된 path의 의미는 add와 같은 R-type 명령의 경우 register에 값을 저장하려면 해당 register를 언제 RF에 저장할 지가 관건인데 이를 저 빨간 path 처럼 저장할 register의 주소를 writeback 방까지 같이 끌고 가도록 한 것이다.

각 cycle에서 필요한 control을 끌고가서 register(clock)과 함께 사용한다.
위 그림에서 두 개의 hazards가 존재함.(data hazard, control hazard)
그림에 rising edge와 falling edge가 표현되어 있음 - falling edge가 Reg.read
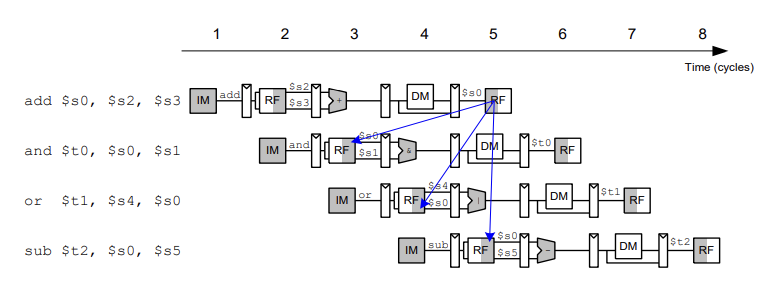
같은 clock 상에 있으면 앞에서 배웠던 것처럼 clock의 rising edge와 falling edge의 적절한 선택(falling에서 write 그 직후에 read)으로 데이터를 가져다 쓸 수 있었는데 (위 그림의 5번 clock에서 가져다 쓴 것처럼)
위 그림처럼 c5에서 write 된 것을 c3와 c4에서 읽어야 하는 경우 만들어지지 않은 값을 가져다 써야 하는 문제가 생긴다.(파란선) 이를 data hazard라고 한다.

이처럼 nop(no operation)을 끼워서 의미 없는 2 cycle을 보낸다. 그렇게 되면 반드시 write이 된 clock 이후에 read가 이루어지기 때문에 문제가 발생하지 않게 해준 것이다.
하지만 두 clock cycle의 낭비가 있다.
그래서 이를 해결하기 위해서는 기존의 명령어를 끼워 넣는 방법도 있는데,
이는 중복되는 경우 dependency가 없는 명령어를 찾아, 순서를 조금 바꿔서 실행시키는 방법이다. 명령어의 위치를 합리적인 곳에 넣을 수 있는지 컴파일러가 엄밀히 따져서 괜찮은 경우에 그곳에 끼우는데 (optimize) 이 때 다시 back 하는 path가 생기게 되고 이를 hazard라고 한다.

i1 명령어를 실행하다 보면 s0(register)에다가 write하는데 이 계산된 결과가 나오게 되는 시점을 생각해 보면 3번째 clock에서 이 값이 만들어진 것을 알 수 있다. (by ALU)
그니까 괜히 이 값이 register에 저장될 때까지 기다리지말고 굳이 register file에서 값을 가져오는 것이 아니라 중간에 데이터값이 만들어지면 바로 가져다 쓰자라는 아이디어이고 이를 통해 nop 없이도 문제를 해결할 수 있게 된다.
그래서 i2를 보면 $s0는 update되기 전의 원래 있던 $s0인데 얘를 register에 저장만 해 두고 실제로 ALU에 들어가는 $s0는 i1의 ALU를 통해 만들어진 값을 넣어주게 되는 것이다.
그 이후에 $s0는 Writeback 과정을 통해 새로운 값이 그제서야 update 된다.

이러한 과정은 위 경우처럼 write clock 전에 read를 하려고 하는 경우에만 처리를 하는 것이다.
따라서 hazard가 없는 경우는 그냥 데이터를 가져오는데 만약 hazard가 발생할 우려가 있는 것에 대해서는 ALU에 들어갈 연산자를 어디서 가져올 것인지를 결정하기 위해 mux control로 결정한다.
어떤 경우에 이런 경우가 생길까?
i1: add $4, $1, $2 | i2: $4, $8 | i3: $8, $4 Q) 그럼 $4가 write된 이후에는 어떻게 가져오는가?
A) register file에 저장이 된 것이기 때문에 그냥 register file에서 읽어올 수 있는 것이다.
if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM)
then ForwardAE = 10
else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW)
then ForwardAE = 01
else ForwardAE = 00 //no hazardForwarding logic for ForwardBE same, but replace rsE with rtE
WriteRegX: X 방에서 write하려고 하는 Register (즉, add 명령의 경우 rd)
RegWriteX: X방에서의 RegWrite control 신호 (각 방에서 계속 쭉 이어지고 있는 control signal)
Q) WriteReg는 어디서 알 수 있는가?
A) 그림에서 자세히 보면 rs, rt는 data path를 따라 W방까지 쭉 이어진다. 단지 방에 따라 뒤에 붙은 알파벳만 다를 뿐. 그래서 그 이어져 오던 rs와 현재 클락의 싱싱한 rs가 hazard unit에서 같은 register인지 비교되어, 만약 같다면 ForwardAE 신호가 결정되는 것이다.
| [컴퓨터구조] 14-3. Pipelined MIPS Performance and Exception handler (1) | 2023.10.10 |
|---|---|
| [컴퓨터구조] 14-2. Pipelined MIPS - hazard (1) | 2023.10.10 |
| [컴퓨터구조] 13. Multi-cycle Performance (2) | 2023.10.10 |
| [컴퓨터구조] 12. Multi-cycle MIPS (1) | 2023.10.10 |
| [컴퓨터구조] 11. Single Cycle MIPS microarchitecture (1) | 2023.10.10 |
소중한 공감 감사합니다