새소식
반응형
Program Execution time
= (# instructions)(cycles/instruction)(seconds/cycle)
= # instructions x CPI x TC


combinational logic에서 어떤 거는 데이터가 빠르게 오고 어떤 거는 느리게 올텐데 이 중 가장 느린 경로를 가진 combinational logic의 경로를 critical path라고 한다.

TC limited by critical path (lw)
clock period가 이를 수용할 수 있을 정도로 길어야 함.

TC = tpcq_PC + 2tmem + tRFread + tmux + tALU + tRFsetup
= [30 + 2(250) + 150 + 25 + 200 + 20] ps
= 925ps
Program with 100 billion instrucitons:
Execution Time = # instructions x CPI x TC
= (100 x 109) (1) (925 x 10-12s)
= 92.5 seconds
명령어 별로 걸리는 시간차이가 다르기 때문에(lw는 엄청 느리고, J 나 beq는 굉장히 빠르다.) 가장 긴 instruction 시간에 맞춰서 clock time을 정해야 하기 때문에 짧은 instruction은 클락이 끝나지 않았는데도 이미 벌써 끝나서 정해진 다음 클락을 기다리기 때문에 비효율적인 상황이 발생한다.
그래서 이를 해결하기 위한 방법 두 가지를 앞으로 소개해 보도록 하겠다.
Q) 그럼 multi-cycle은 CPI가 5인 것인가?
A) 다 다르기 때문에 평균으로 구함


위와 같이 나누어서 생각해 보자.(골고루 나누어야 효율적이기 때문)
그러면 중간 중간 데이터를 담아야할 register를 끼워 주어야 함(clock이 지나면 잊어버리기 때문에 저장해 놓는 것)
STEP 1: Fetch instruciton

STEP 2a: Read source operands from RF

STEP 2b: Sign-extend the immediate

STEP 3: Compute the memory address

STEP 4: Read Data from memory

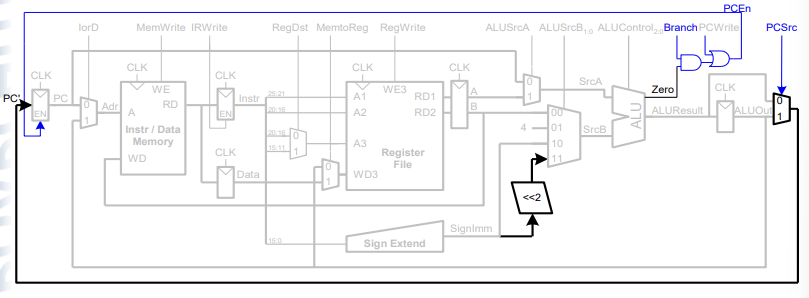
IorD에 따라 data memory에 저장해야 하기 때문에 IorD는 1이 될 것이고 이 결과가 data memory에 저장된다.
data memory에 있는 것을 읽어서 async하게 data register에 넣어준다.
STEP 5: Write back data block to register file

Increment PC -> 사실상 step 1에서도 가능하다 (step1(fetch)에서 ALU는 놀고있기 떄문에)

Write data in rt to memory

RF에 저장할 필요가 없기 때문에 4 cycle이면 된다.

3번째 clock에서는 ALU를 쓰고 있기 때문에(빼기 연산) BTA를 계산하는 과정을 3번째 clock에는 넣으면 안 된다.
그러므로 두 번째 cycle에서 BTA를 만들어 놓고 3번째 clock에서 두 값의 조건을 확인하는 용도로 ALU를 사용한다.
Finite State Machine(FSM)이 사용됨

5단계로 쪼갰기 떄문에 4개의 register가 추가됨
Control unit을 main controller와 ALU decoder 로 나누었음.
Control에는 Mux control과 Write enable 신호가 있다.

FSM: moore machine

IR <- Mem[PC] // IorD = 0 , IRWrite
PC <- PC + 4 //AluSrcA, ......

A <- RF[A1]
B <- RF[A2]

control 신호가 필요없어서 안 씀
lw or sw
ALUResult <- A + Imm
ALU register에 저장


Data <- Mem[ALUout] :4번째 ; data register에 저장하는 과정
RF[A3] <- Data : 5번째 ; data에 저장된 내용을 register file에 저장하는 과정
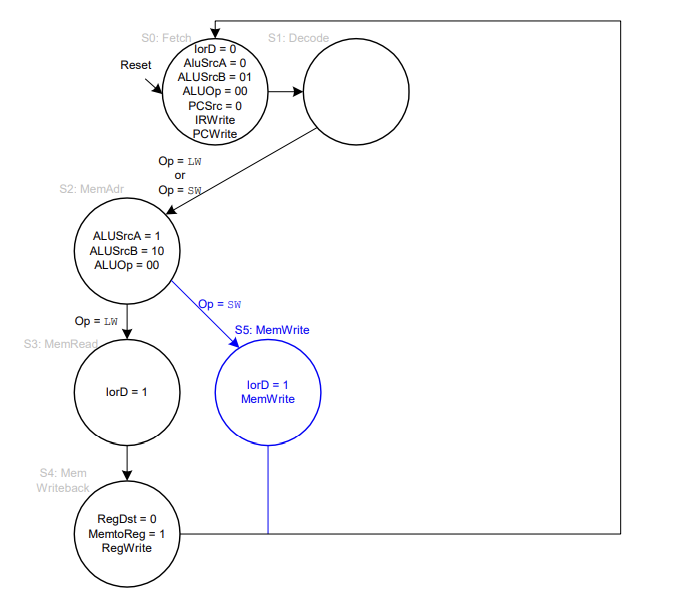
memory에 write하고 다시 Fetch 과정으로 돌아감

register write
state에 따라 각각의 control signal이 다르기 때문에 FSM 사용하는 것.
ALUout <- PC + 4 + Imm << 2 // 두 번째 cycle에서 BTA 계산
if (A == B) PC <- ALUout //세 번째 cycle






| [컴퓨터구조] 14-1. Pipelined MIPS (1) | 2023.10.10 |
|---|---|
| [컴퓨터구조] 13. Multi-cycle Performance (2) | 2023.10.10 |
| [컴퓨터구조] 11. Single Cycle MIPS microarchitecture (1) | 2023.10.10 |
| [컴퓨터구조] 10. Micro architecture(Single-Cycle) (1) | 2023.10.10 |
| [컴퓨터구조] 9. System Verilog (0) | 2023.10.10 |
소중한 공감 감사합니다