새소식
반응형
heap을 이용하여 sorting을 하는 것을 heap sort라고 합니다.
heap이 주로 사용되는 곳은 priority queue(우선순위 큐)입니다.
완전 이진 트리는 그 높이에 대한 노드 수가 최대인 트리를 말합니다. 즉, 모든 레벨에서 노드들로 꽉 채워져 있는 것을 말합니다.
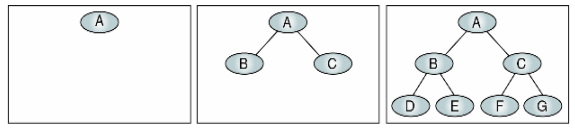
즉, 첫 번째 그림(height = 0) 에서 height 0에 대해 node를 maximum으로 채우는 경우는 오직 1개가 들어가는 구조입니다.
이진 트리(Binary tree)는 거의 완전합니다. 다음 두 조건만 만족한다면.




(a) 그림의 tree는 nearly complete binary tree이면서 max heap property를 만족합니다.
max-heap은 (a) 이진 트리와 (b) 배열로 보입니다. 트리의 각 노드에서 원 안의 숫자는 그 노드에 저장된 값입니다.
원 위의 숫자는 배열의 인덱스와 상응합니다.
(b) 그림에서 배열의 위 아래로 그어진 선들은 부모-자식 관계를 나타나는 것이며, 이는 배열에서 부모 인덱스는 는 항상 그들 자식의 왼쪽에 존재하게 됩니다.
max-heap property를 유지하기 위해서 우리는 MAX_HEAPIFY 절차라고 부릅니다.
그것의 input은 배열 A와 배열에 대한 인덱스 i입니다. 호출될 때 MAX-HEAPIFY는 LEFT(i)과 RIGHT(i)에 루트 된 이진 트리가 max-heap이지만 A[i]가 자식 트리보다 작을 수 있기 때문에 max-heap property에 위배된다고 가정합니다.
MAX_HEAPIFY는 A[i]의 값이 max-heap에서 "float-down" 하도록 하여 인덱스 i에 루팅된 subtree가 max-heap property를 만족하도록 합니다.


배열 A[1 ..n]을 변환하는 bottom-up(상향식) 방식으로 MAX_HEAPIFY 절차를 사용할 수 있습니다.


internal node 중에서 가장 큰 애부터 루트 노드까지에 대하여 Max- heapify를 진행한다.
class MaxHeap:
def __init__(self, data_list = None):
self.h = [0] # the heap
if data_list is not None:
self.h.extend(data_list)
# build the max heap
# apply max_heapify() only for internal nodes
for i in range(self.size() // 2, 0, -1): # internal node의 제일 끝에 있는 애부터 root까지
self.max_heapify(i)a = [4, 8, 7, 2, 9, 10, 5, 1, 3, 6]
h1 = MaxHeap(a)
print(h1.h)
보면 리스트는 heapify가 되어 max-heap 형태가 된 것을 볼 수 있습니다.
# return the current size of the heap
def size(self):
return len(self.h) - 1 # 0 제외
# move item k as down as possible
def max_heapify(self, k): # k는 heapify를 진행할 노드 number
left = k * 2
right = k * 2 + 1
largest = k
if left <= self.size() and self.h[left] > self.h[largest]:
largest = left
if right <= self.size() and self.h[right] > self.h[largest]:
largest = right
if largest != k:
self.h[k], self.h[largest] = self.h[largest], self.h[k]
self.max_heapify(largest) # recursion

# max_heapify 한 번 진행할 때마다 바뀌는 과정
[4, 8, 7, 2, 9, 10, 5, 1, 3, 6] # 초기 배열
[0, 4, 8, 7, 2, 9, 10, 5, 1, 3, 6]
[0, 4, 8, 7, 3, 9, 10, 5, 1, 2, 6] 2-3
[0, 4, 8, 10, 3, 9, 7, 5, 1, 2, 6] 7-10
[0, 4, 9, 10, 3, 8, 7, 5, 1, 2, 6] 8-9
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6] 10-7-4(recursion)
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6]
# 재귀 전까지 print()를 찍어본 것인데 참고
[0, 4, 8, 7, 2, 9, 10, 5, 1, 3, 6] # 초기 상태
[0, 4, 8, 7, 3, 9, 10, 5, 1, 2, 6] # 4번째 노드 (2,3 교환)
[0, 4, 8, 7, 3, 9, 10, 5, 1, 2, 6] # 재귀를 했지만 다음 노드가 없어서 변화 x
[0, 4, 8, 10, 3, 9, 7, 5, 1, 2, 6] # 3번째 노드 (7,10 교환)
[0, 4, 8, 10, 3, 9, 7, 5, 1, 2, 6] # 재귀를 했지만 다음 노드가 없어서 변화 x
[0, 4, 9, 10, 3, 8, 7, 5, 1, 2, 6] # 2번째 노드 (8,9 교환)
[0, 4, 9, 10, 3, 8, 7, 5, 1, 2, 6] # 재귀를 했지만 이미 만족하고 있어서 변화 x(9, 6)
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6] # 1번째 노드 (4, 10 교환)
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6] #
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6]
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6]
[0, 4, 8, 7, 2, 9, 10, 5, 1, 3, 6] # 초기 상태
[0, 4, 8, 7, 2, 9, 10, 5, 1, 3, 6]
[0, 4, 8, 7, 3, 9, 10, 5, 1, 2, 6] # 4번째 노드 (2,3 교환)
[0, 4, 8, 7, 3, 9, 10, 5, 1, 2, 6]
[0, 4, 8, 10, 3, 9, 7, 5, 1, 2, 6] # 3번째 노드 (7,10 교환)
[0, 4, 8, 10, 3, 9, 7, 5, 1, 2, 6]
[0, 4, 9, 10, 3, 8, 7, 5, 1, 2, 6] # 2번째 노드 (8,9 교환)
[0, 4, 9, 10, 3, 8, 7, 5, 1, 2, 6]
[0, 10, 9, 4, 3, 8, 7, 5, 1, 2, 6] # 1번째 노드 (4, 10 교환)
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6] # (재귀) 3번째 노드(4, 7 교환)
[0, 10, 9, 7, 3, 8, 4, 5, 1, 2, 6]
내가 가진 값들 중 가장 큰 data를 가지는 노드는 항상 1번 index 일 것이다라는 아이디어를 이용합니다.


옅게 칠해진 회색 노드들 만이 heap 안에 남아 있는 것들입니다.
다음 과정과 같이 진행됩니다.


root에서 계속 끌어 내리면서 하나씩 배열에 추가하다보면 그 배열은 자연스럽게 정렬된 배열이 됩니다.
이것이 바로 max-heap 구조와 heapify를 통한 정렬이라고 볼 수 있습니다.
앞서 만들어 둔 Heapify 클래스의 멤버 함수인 heap_sort를 구현해 보겠습니다.
def heap_sort(self):
save = self.h[:] # shallow copy
sorted_list = self.h[1:]
for i in range(self.size(), 0, -1): # 제일 마지막 노드부터
self.h[1], self.h[i] = self.h[i], self.h[1]
sorted_list[i - 1] = self.h[i] #제일 큰 걸 가져와서 list에 넣는다.
self.h.pop() #list에 넣은 건 제거
self.max_heapify(1) # root에 대한 heapify
self.h = save # 망가진 h 복구
return sorted_listprint(h1.heap_sort())
print(h1.h)
이 섹션에서는 heap의 가장 일반적인 적용 사례 중 하나를 소개합니다:
heap과 마찬가지로 우선순위 큐는 두 가지 형태로 제공됩니다.
우선순위 큐는 각각 key라고 불리는 연관된 값을 가진 요소들의 집합 S를 유지하기 위한 자료구조입니다. max-priority queue는 다음 연산을 지원합니다.

<psuedo code>
#HEAP-EXTRACT-MAX(A) # max heap 리스트
if A.heap_size < 1: # 1
error "heap underflow"
max = A[1]
A[1] = A[A.heap_size] # 제일 끝에 있는 노드를 제일 첫 노드에 넣는다.
A.heap_size = A.heap_size - 1 # heap size를 하나 줄인다.
MAX-HEAPIFY(A, 1) # 제일 위에 있는 노드는 heap property를 만족하지 않으므로 끌어 내린다.
return max # 7
위는 heap sort에서 배운 메커니즘과 동일합니다.
def pop(self):
if self.size() == 0:
return None
item = self.h[1]
# copy the last item to root and remove it
self.h[1] = self.h[self.size()]
self.h.pop()
self.max_heapify(1)
return itemfor _ in range(h1.size()):
print(h1.pop(), end=' ')
print()
print(h1.h)
데이터를 추가할 때는 그냥 집어 넣으면 안 되고 적절히 자기 자리를 찾아서 넣어주어야 합니다.

def insert(self, item):
self.h.append(item)
# move up the item to keep the max-heap property
k = self.size()
while k > 1 and self.h[k] > self.h[k//2]:
self.h[k], self.h[k//2] = self.h[k//2], self.h[k]
k //= 2 # 내 index를 부모 node index와 바꿈.h1 = MaxHeap()
for d in (4, 8, 7, 2, 9, 10, 5, 1, 3, 6):
h1.insert(d)
print(h1.h)
MaxHeap()의 time complexity는 어떻게 될까요?
MAX_HEAPIFY에 대한 각 호출은 O(logn) 시간이 소요되며, BUILD-MAX-HEAP는 O(n)에 해당하는 시간이 소요됩니다.
이 상한은 정확하지만 점근적으로 딱 들어맞지는 않습니다.
MAX-HEAPIFY가 노드에서 실행된 시간은 트리의 height에 따라 달라지며 대부분의 노드 height 값이 작다는 것을 관찰함으로써 더 엄격한 경계(bound)를 설정할 수 있습니다.
우리의 철저한 분석은 n개 원소를 가진 heap에 대해 높이 ⌊logn] 그리고 어떤 높이 h에서 최대 [n/2h+1⌉ 개의 노드를 갖는 특성에 의존합니다.
⌊log2N⌋ ⌈ − ⌉
최악의 시간 복잡도

높이 h의 노드에서 호출될 때, MAX_HEAPIFY가 요구하는 시간은 O(h)이므로, 우리는 위에서 제한된 BUILD-MAX-HEAP의 총 cost를 O(h)로 표현할 수 있습니다.
→ O(h) : max-heapify에서 loop를 도는 횟수


위 식에서 x = 1/2로 대체하여 마지막 합계를 평가합니다.


따라서 우리는 BUILD-MAX-HEAP의 실행 시간을 다음과 같이 제한할 수 있습니다.

정렬된 배열 대신 힙을 사용해야 하는 이유?
맞습니다. 힙을 작성하는 데는 선형적인 시간이 걸리고 삽입/삭제 연산에는 O(logn)이 걸립니다. 최소/최대 저장 요소를 찾는 즉, heap을 peek하는 것은 물론 O(1)이며, head를 pop하는 것은 O(logn)입니다.
질문에 대한 답은 간단합니다. 일부 사용 사례에서는 모든 데이터를 정렬하는 것은 중요하지 않지만, 가장 작은/큰 요소를 지속적으로 유지하는 것은 중요합니다. 이는 많은 적용 사례에서 광범위하게 사용되는 개념인 우선순위 큐(Priority Queue)에 해당하는 것입니다.
python 내장 heap module
1. heapq.heappush(heap, item)
2. heapq.heappop(heap)
3. heapq.heappushpop(heap, item)
4. heapq.heapify(x)
아래 링크를 통해 heapq 모듈에 대한 자세한 사용법을 보실 수 있습니다.
heapq — Heap queue algorithm — Python 3.8.14 documentation
heapq — Heap queue algorithm Source code: Lib/heapq.py This module provides an implementation of the heap queue algorithm, also known as the priority queue algorithm. Heaps are binary trees for which every parent node has a value less than or equal to an
docs.python.org
import heapq
# A heap sort algorithm
def heapsort(iterable):
h = []
for value in iterable: # heapify 하는 과정
heapq.heappush(h, value)
return [heapq.heappop(h) for _ in range(len(h))] # sorting 과정
# You can transform a populated list into a heap
a = [3, 5, 1, 2, 6, 8, 7]
heapq.heapify(a)
print(a)
print(heapsort(a))
# Or use a list initialized to []
# Heap elements can be tuples.
b = []
heapq.heappush(b, (5, 'write code'))
heapq.heappush(b, (7, 'release product'))
heapq.heappush(b, (1, 'write spec'))
print(heapq.heappop(b))
실행 결과
[1, 2, 3, 5, 6, 8, 7]
[1, 2, 3, 5, 6, 7, 8]
(1, 'write spec')[0, 3, 5, 1, 2, 6, 8, 7]
[0, 3, 5, 8, 2, 6, 1, 7]
[0, 3, 5, 8, 2, 6, 1, 7]
[0, 3, 6, 8, 2, 5, 1, 7]
[0, 3, 6, 8, 2, 5, 1, 7]
[0, 8, 6, 3, 2, 5, 1, 7]
[0, 8, 6, 7, 2, 5, 1, 3]
14235번: 크리스마스 선물
크리스마스에는 산타가 착한 아이들에게 선물을 나눠준다. 올해도 산타는 선물을 나눠주기 위해 많은 노력을 하고 있는데, 전세계를 돌아댕기며 착한 아이들에게 선물을 나눠줄 것이다. 하지만
www.acmicpc.net


import heapq
import sys
sys.stdin = open('bj14235_in.txt', 'r')
n = int(input())
present = []
for i in range(n):
a = list(map(int, input().split()))
if a[0] == 0:
if len(present) == 0:
print(-1)
else:
tmp = -heapq.heappop(present)
print(tmp)
else:
for j in range(a[0]):
heapq.heappush(present, -a[j+1])
14241번: 슬라임 합치기
영선이와 효빈이는 슬라임을 합치는 게임을 하고 있다. 두 사람은 두 슬라임을 골라서 하나로 합쳐야 한다. 게임은 슬라임이 하나 남았을 때 끝난다. 모든 슬라임은 양수 크기를 가지고 있다. 두
www.acmicpc.net


| [자료구조와 알고리즘 | 파이썬] Greedy Algorithms(그리디 알고리즘) (1) | 2022.12.31 |
|---|---|
| [자료구조와 알고리즘 | 파이썬] Dynamic Programming(동적계획법) - 다이나믹 프로그래밍; DP (2) | 2022.12.31 |
| [자료구조와 알고리즘 | 파이썬] Graphs - 그래프 자료구조(+약간의 python 개념) (1) | 2022.12.31 |
| [자료구조와 알고리즘 | 파이썬] Trees (트리 자료구조) (0) | 2022.12.31 |
| [자료구조와 알고리즘 | 파이썬] Stacks and Queues (스택 & 큐) (0) | 2022.12.31 |
소중한 공감 감사합니다