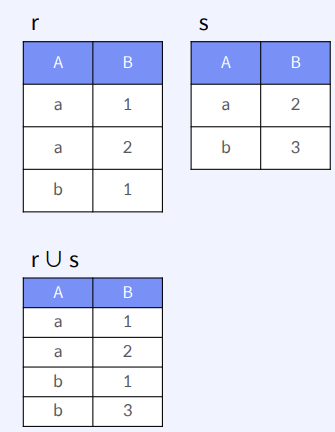
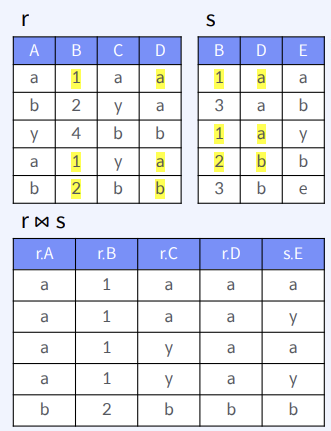
CS 지식/데이터베이스 [데이터베이스-simple버전] 2. 관계형 데이터 모델(Relational Data Model) 2023.11.07 - 반응형 관계형 데이터 모델 1. 데이터 모델링 데이터 모델링 (data modeling) 현실 세계에 존재하는 데이터를 컴퓨터 세계의 데이터베이스로 옮기는 과정 데이터베이스 설계의 핵심 과정 데이터 모델링 3단계 개념적 데이터 모델링 현실세계를 추상화하여 중요 데이터를 개념 세계로 추출해 가는 과정 결과물로 개념적 데이터 모델 (객체 – 관계 (E-R) 모델) 논리적 데이터 모델링 개념 세계의 데이터를 데이터베이스가 저장할 구조로 변환하는 과정 결과물로 관계 데이터 모델 물리적 데이터 모델링 논리 데이터 모델이 실제 데이터베이스 저장소에 저장되는 저장 구조 (테이블, 컬럼)로 변경 데이터 모델링 예제 2. 관계형 데이터 모델 관계 데이터 모델 개체에 대한 데이터를 저장하는 논리적 구조 – 릴레이션 (2차원의 테이블 구조) 릴레이션의 특성 튜플의 유일성 : 동일한 튜플이 존재할 수 없다 튜플의 무순서 : 튜플 사이의 순서는 무의미 속성(애트리뷰트)의 무순서 : 속성 사이의 순서는 무의미 속성의 원자성(Atomic) : 애트리뷰트 값으로 하나 (나누어지지 않는) 값만 가짐 Key의 종류 Key란? 릴레이션에 튜플을 구별하는 역할을 하는 속성 또는 속성의 집합 Super key : 튜플을 구별하기 위해 유일성을 제공할 수 있는 속성 또는 속성의 집합 Ex) {ID}, {ID, name} Candidate key : super key 중에서 개수가 가장 작은 키 Ex) {ID} Primary key : candidate key 중에서 디자인을 고려하여 선택된 키 Foreign key : 다른 릴레이션의 primary key을 참조하는 속성 또는 속성의 집합 3. 관계대수 - 1 관계 데이터 연산 모든 DBMS는 데이터 처리를 위해 하나 이상의 데이터 언어를 제공 Formal query language 수학기호(notation)을 사용하여 데이터 처리를 기술한 언어 새로운 언어의 개념과 유용성을 검증하는 기준 관계 대수 (Relation algebra) Commercial language 수학적인 원리를 기반으로 사용하기 쉽게 만들어진 단어 관계 대수로 만들어진 모든 질의가 표현 가능 – Relationally complete SQL 관계대수 연산자 관계 대수 연산자 (Relational Algebra Operations) 피연산자로 하나 또는 두 개의 릴레이션 (Unary and binary operations) 각 연산자의 연산 결과는 새로운 릴레이션-연산의 합성(compose)&체이닝(chaining) 가능 연산자 종류 select project union difference intersection cartesian product natural join theta join outer join select operation project operation union(합집합) operation difference(차집합) operation intersection operation 4. 관계 대수 -2 Cartesian product(카티션 프로덕트) operation Natural join(자연 조인) theta join(세타 조인) outer join(외부 조인) operation 반응형 공유하기 URL 복사카카오톡 공유페이스북 공유엑스 공유 게시글 관리 구독하기개발자로 살아남기 Contents 1.데이터모델링 데이터모델링예제 2.관계형데이터모델 관계데이터모델 릴레이션의특성 Key의종류 Key란? 3.관계대수-1 관계데이터연산 관계대수연산자 selectoperation projectoperation union(합집합)operation difference(차집합)operation intersectionoperation 4.관계대수-2 Cartesianproduct(카티션프로덕트)operation Naturaljoin(자연조인) thetajoin(세타조인) outerjoin(외부조인)operation 당신이 좋아할만한 콘텐츠 [데이터베이스-simple버전] 4. SQL 심화 2023.11.07 [데이터베이스-simple버전] 3. SQL 데이터베이스 언어 2023.11.07 [SQL 코테 준비] SQL 문법 정리 및 팁 2023.03.07 [데이터베이스- simple버전] 1. 데이터베이스 정의 2023.01.03 댓글 0 + 이전 댓글 더보기